[Webinar] SpiraTest - Setting New Standards in Quality Assurance
Hive
1. Prepared by
Vetri.V
What is Hive?
Hive is a data warehouse system for Hadoop that facilitates easy data
summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop
compatible file systems.
Hive provides a mechanism to project structure onto this data and query the data
using a SQL-like language called HiveQL.
At the same time this language also allows traditional map/reduce programmers to
plug in their custom mappers and reducers when it is inconvenient or inefficient to
express this logic in HiveQL.
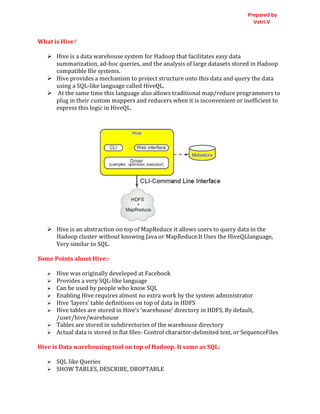
Hive is an abstraction on top of MapReduce it allows users to query data in the
Hadoop cluster without knowing Java or MapReduce.It Uses the HiveQLlanguage,
Very similar to SQL.
Some Points about Hive:-
Hive was originally developed at Facebook
Provides a very SQL-like language
Can be used by people who know SQL
Enabling Hive requires almost no extra work by the system administrator
Hive ‘layers’ table definitions on top of data in HDFS
Hive tables are stored in Hive’s ‘warehouse’ directory in HDFS, By default,
/user/hive/warehouse
Tables are stored in subdirectories of the warehouse directory
Actual data is stored in flat files- Control character-delimited text, or SequenceFiles
Hive is Data warehousing tool on top of Hadoop. It same as SQL:
SQL like Queries
SHOW TABLES, DESCRIBE, DROPTABLE
2. Prepared by
Vetri.V
CREATE TABLE, ALTER TABLE
SELECT, INSERT
Hive Limitations:
Not all ‘standard’ SQL is supported
No support for UPDATE or DELETE
No support for INSERTing single rows
Relatively limited number of built-in functions
No datatypes for date or time - Use the STRING datatypeinstead.In new version date
or time datatype will support.
Hive Architecture
Metastore:
Stores system catalog.
Driver:
Manages life cycle of HiveQL query as it moves thru’ HIVE; also manages session
handle and session statistics
Query compiler:
Compiles HiveQL into a directed acyclic graph of map/reduce tasks
Execution engines:
The component executes the tasks in proper dependency order; interacts with
Hadoop
Hive Server:
3. Prepared by
Vetri.V
Provides Thrift interface and JDBC/ODBC for integrating other applications.
Client components:
CLI, web interface, jdbc/odbc interface Extensibility interface include Server , User Defined
Functions and User Defined Aggregate Function.
Hive Installations and Metastore with Mysql:
Store Hive Metadata into RDBMS.
The Metastore stores all the information about the tables, their partitions, the
schemas, the columns and their types, the table locations etc.
This information can be queried or modified using a thrift interface and as a result
it can be called from clients in different programming languages.
As this information needs to be served fast to the compiler, they have chosen to
store this information on a traditional RDBMS.
By default, hive use an embedded Derby database to store metadata information.
The metastore is the "glue" between Hive and HDFS.
It tells Hive where your data files live in HDFS, what type of data they contain, what
tables they belong to, etc.
The Metastore is an application that runs on an RDBMS and uses an open source
ORM layer called DataNucleus, to convert object representations into a relational
schema and vice versa.
They chose this approach as opposed to storing this information in hdfs as they
need the Metastore to be very low latency. The DataNucleus layer allows them to
plugin many different RDBMS technologies.
Facebook uses MySQL to store metadata information.
Store Hive metadata into MySQL:
write on /etc/profile the following:
export JAVA_HOME=/usr/java/jdk1.7.0_17
export PATH=$PATH:/usr/java/jdk1.7.0_17/bin
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:/opt/hadoop/bin
export HIVE_HOME=/opt/hive
export PATH=$HADOOP_HOME/bin:$HIVE_HOME/bin:$PATH
Go to hadoop home and perform the following tasks:
Commands to perform this setup are as follows:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
4. Prepared by
Vetri.V
We need to perform following steps to setup a metastore in a MySQL server.
1. Install mysql-server.
sudo apt-get install mysql-server
(or)
yum install mysql-server <---centOS------>
2. Use su command. You will see password promt. Type your root
userpassword.
3. If your password correct, you'll see like this; root@yourdesktopname#.
4. Now, Start mysql server.
/etc/init.d/mysql start.
5. When mysql server started, type mysql -u root mysql.
6. Next, I'm going to create a new MySQL user for hadoop/hive.
mysql> CREATE USER 'hadoop'@'localhost' IDENTIFIED BY 'hadoop';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'localhost' WITH
GRANT OPTION;
mysql> exit;
7. su – userName // In my case userName is hadoop. So, switch to that user.
8. mysql -h localhost -u userName -p.
9. Now, we need to change the hive configuration so it can use MySQL:
10. Go to hive/conf directory, then open hive-default.xml and perform
following changes.
<!-- In local metastore setup, each Hive Client will open a connection to
the datastore and make SQL queries against it.-->
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
5. Prepared by
Vetri.V
<name>javax.jdo.option.ConnectionUserName</name>
<value>Username</value><!-- In my case UserName is hadoop-->
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>UserPassword</value><!-- In my case password is hadoop-->
</property>
(OR)
create hive-site.xml and paste the followings:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- WARNING!!! This file is provided for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<!-- In local metastore setup, each Hive Client will open a connection to
the datastore and make SQL queries against it.-->
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/eattributes?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value><!-- In my case UserName is hadoop-->
</property>
<property>
6. Prepared by
Vetri.V
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value><!-- In my case password is hadoop-->
</property>
</configuration>
11. Hive needs to have the MySQL jdbc drivers, so we need to download and
12. If all settings are done correctly, we can do this:-
copy it to hive/lib folder.
impetus@ubuntu:~$ cd HIVE_HOME
impetus@ubuntu:~/hive$ bin/hive
Hive history file=/tmp/ankit
/hive_job_log_ankit_201102211937_456962737.txt
hive>
hive>create table temp(info INT);
OK
Time taken: 4.745 seconds
hive> show tables;
OK
temp
Time taken: 0.137 seconds
hive>
13. Again, start MySQL server.
vetri@ubuntu:~$mysql -h localhost -u hadoop -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 84
Server version: 5.1.41-3ubuntu12.8 (Ubuntu)
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql>
14. Use following command to view all existing databases.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
7. Prepared by
Vetri.V
| hive |
| mysql |
+--------------------+
3 rows in set (0.05 sec)
mysql> use hive; //Select database.
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql>
15. Use following command to view all exiting tables.
mysql> show tables;
+--------------------+
| Tables_in_hive |
+--------------------+
| BUCKETING_COLS |
| COLUMNS |
| DBS |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SORT_COLS |
| TABLE_PARAMS |
| TBLS |
+--------------------+
16 rows in set (0.00 sec)
mysql>
16. Use following command to view the metadata information of hive table
columns.
8. Prepared by
Vetri.V
mysql> select * from COLUMNS;
+-------+---------+-------------+-----------+-------------+
|SD_ID|COMMENT|COLUMN_NAME|TYPE_NAME|INTEGER_IDX|
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | info | int | 0 |
+-------+---------+-------------+-----------+-------------+
1 rows in set (0.00 sec)
mysql>
//Where info is the column of temp table.
17. Similarly, you can View the information of partiotions, Bucketing,
tables, etc.
Hive Applications, Components, Model and Layout
Hive Applications:
Log processing
Text mining
Document indexing
Customer-facing business intelligence (e.g., Google Analytics)
Predictive modeling, hypothesis testing
Hive Components:
Shell: allows interactive queries like MySQL shell connected to database – Also
supports web and JDBC clients
Driver: session handles, fetch, execute
Compiler: parse, plan, optimize
sExecution engine: DAG of stages (M/R,HDFS, or metadata)
Metastore: schema, location in HDFS,SerDe
Data Model:
Tables – Typed columns (int, float, string, date,boolean) – Also, list: map (for JSON-
like data)
Partitions – e.g., to range-partition tables by date
Buckets – Hash partitions within ranges (useful for sampling, join optimization)
Metastore:
Database: namespace containing a set of tables
Holds table definitions (column types,physical layout)
Partition data
9. Prepared by
Vetri.V
Uses JPOX ORM for implementation; can be stored in Derby, MySQL, many other
relational databases
Physical Layout:
Warehouse directory in HDFS – e.g., /home/hive/warehouse
Tables stored in subdirectories of warehouse – Partitions, buckets form
subdirectories of tables
Actual data stored in flat files – Control char-delimited text, or SequenceFiles – With
custom Server, can use arbitrary format
Hive Command Line Interface:
To launch the Hive shell, start a terminal and run $ hive
Note: example is the table name for all qurey
hive>
Hive : Creating Tables
hive> CREATE TABLE example (id INT, name STRING) ROW FORMAT DELIMITED FIELDS
TERMINATED BY 't' STORED AS TEXTFILE;
hive> DESCRIBE example;
hive> SHOW TABLES;
Hive : Loading Data Into Hive
Data is loaded into Hive with the LOAD DATA INPATH statement – Assumes that the data is
already in HDFS
hive> LOAD DATA INPATH “file_txtdata.txt” INTO TABLE example;
If the data is on the local filesystem, use LOAD DATA LOCAL INPATH – Automatically loads
it into HDFS
hive> LOAD DATA LOCAL INPATH "file_txtdata.txt" INTO TABLE example;
Hive : SELECT Queries
Hive supports most familiar SELECT syntax
hive> SELECT * FROM example LIMIT 10;
hive> SELECT * FROM example WHERE id > 100 ORDER BY name ASC LIMIT 10;
Joining Tables
SELECT e.name, e.dep, s.id FROM example e JOIN sample s ON (e.dep = s.dep) WHERE e.id
>= 20;
Creating User-Defined Functions
INSERT OVERWRITE TABLE u_data_new
SELECT TRANSFORM (userid, movieid, rating, unixtime) USING 'python
weekday_mapper.py' AS (userid, movieid, rating, weekday) FROM u_data;
10. Prepared by
Vetri.V
Join Query: sample
1.Create table
CREATE TABLE example(ID
int,SUBJECTstring,PRODUCTstring,PERIODint,START_TIMEint,OPERATION string)ROW
FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS TEXTFILE;
2.Load data (save the file in related folder)
hive> LOAD DATA LOCAL INPATH "file_txtdata.txt" INTO TABLE example;
3.Join Query
select A.*
from example A
join (
select id, max(start_time) as start_time
from example B
where start_time< 25
group by id ) MAXSP
ON A.id=MAXSP.id and A.start_time = MAXSP.start_time;
Using NOT IN / IN hive query
SELECT * FROM example WHERE NOT array_contains(array(7,6,5,4,2,12), id)
---THANK YOU---