Télécharger en tant que PDF, PPTX

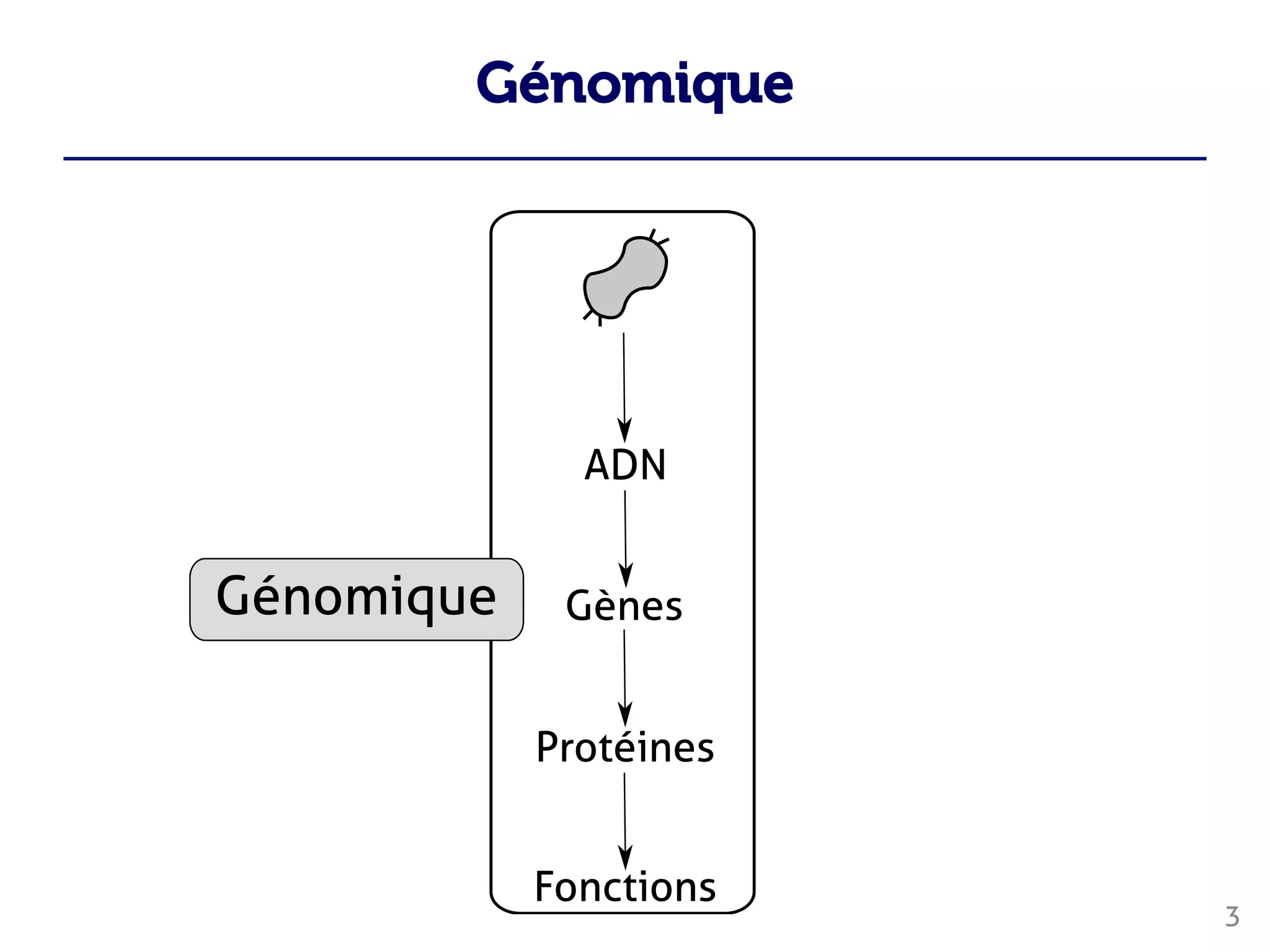
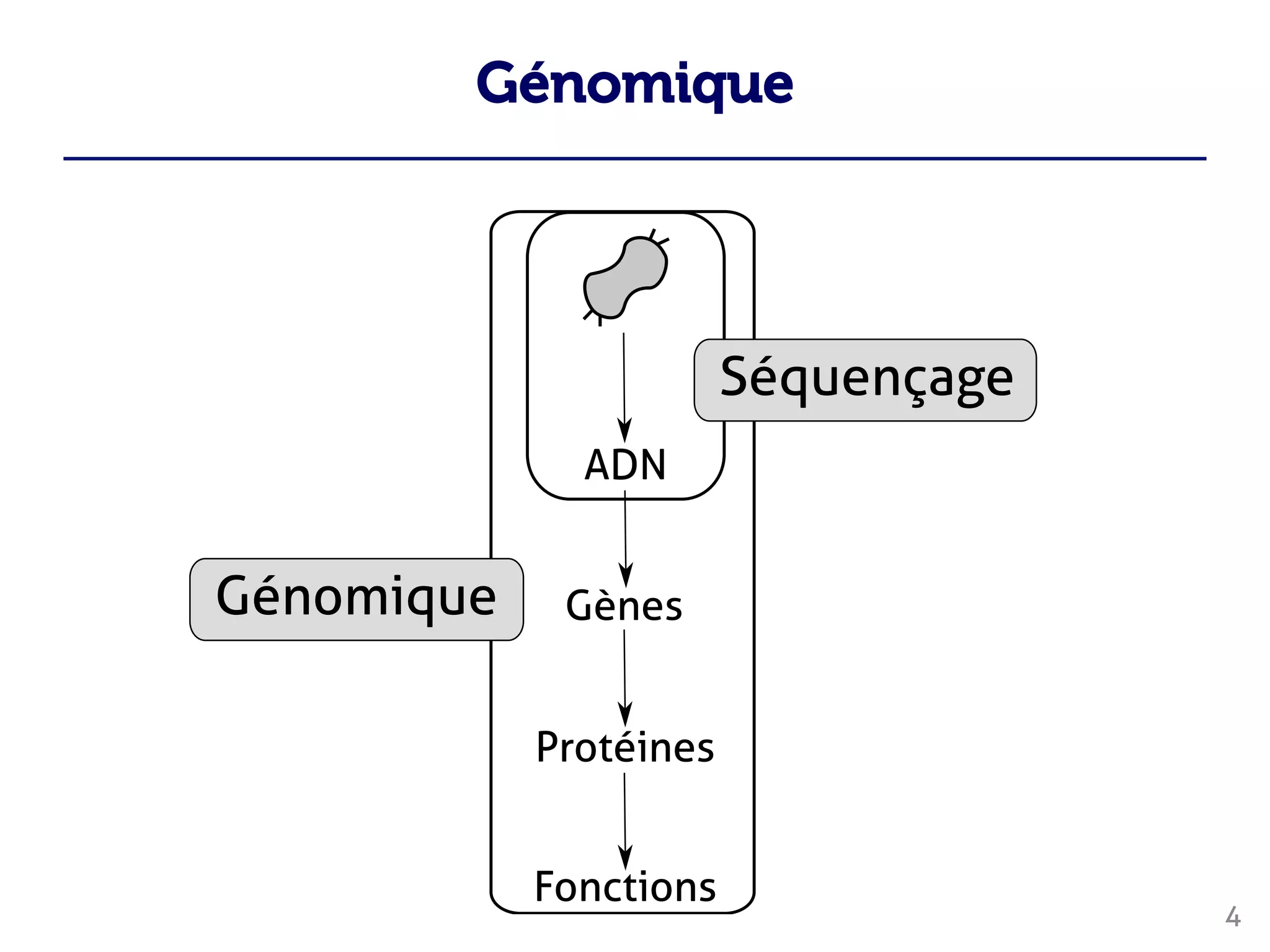
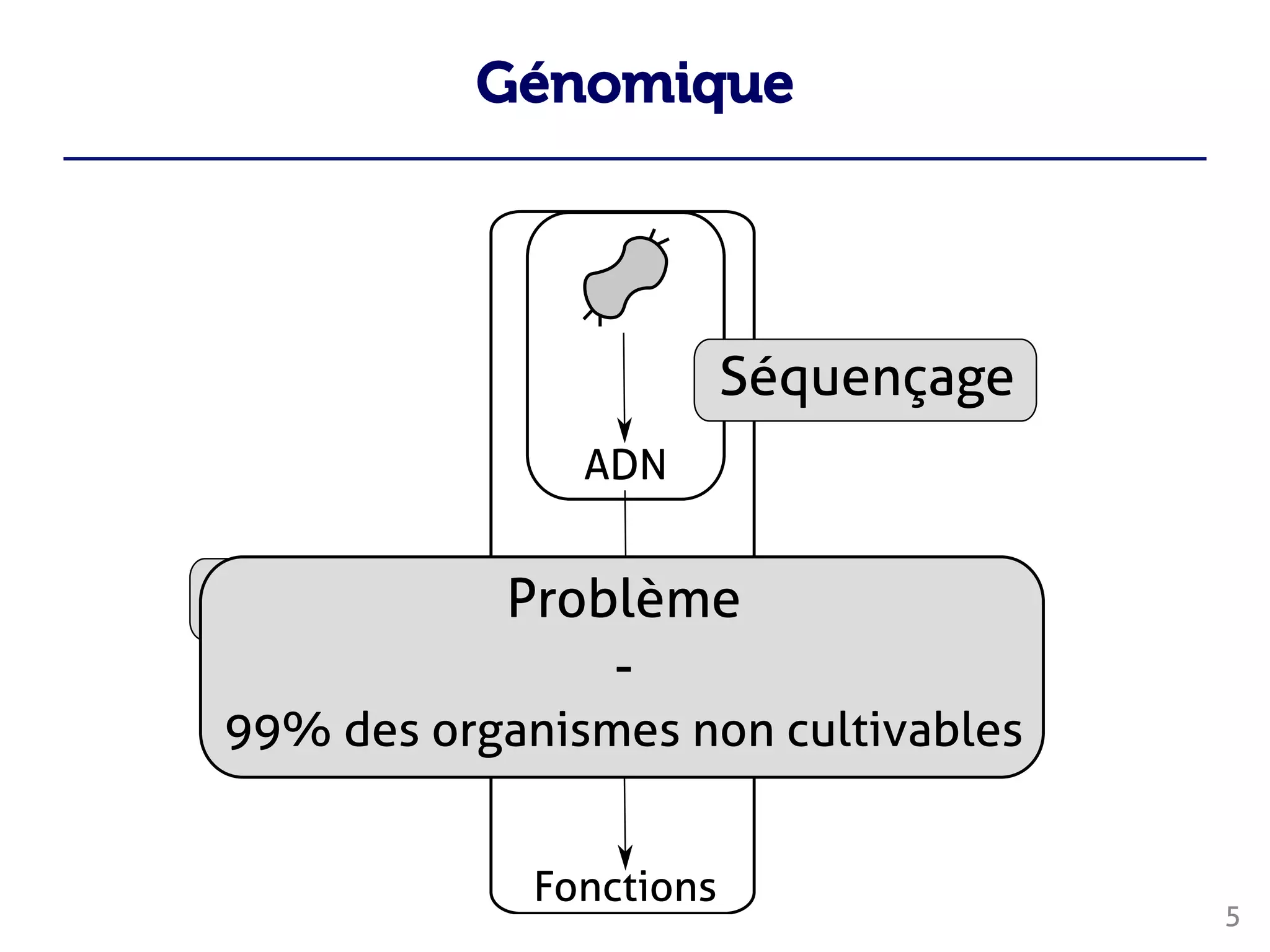
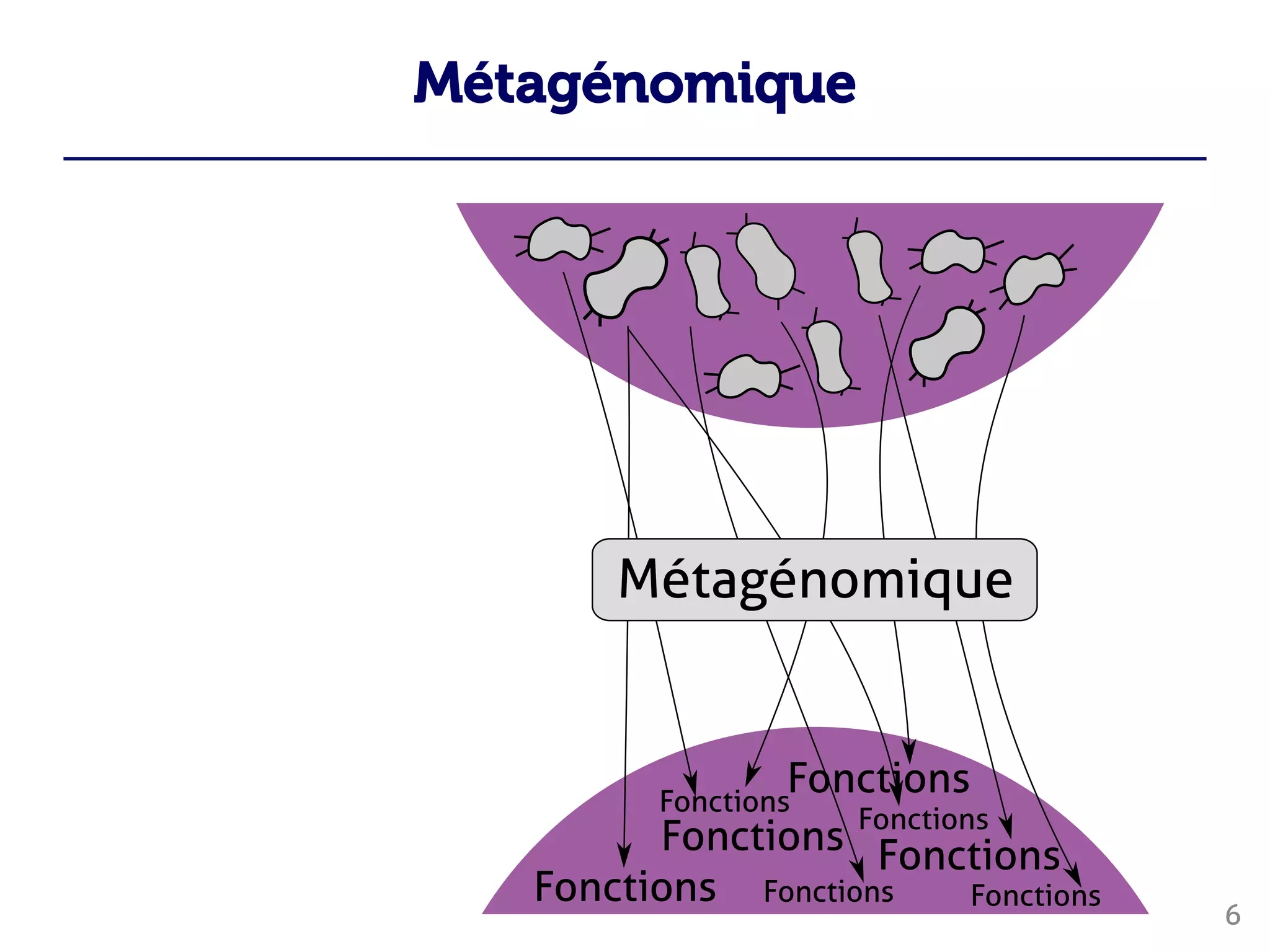
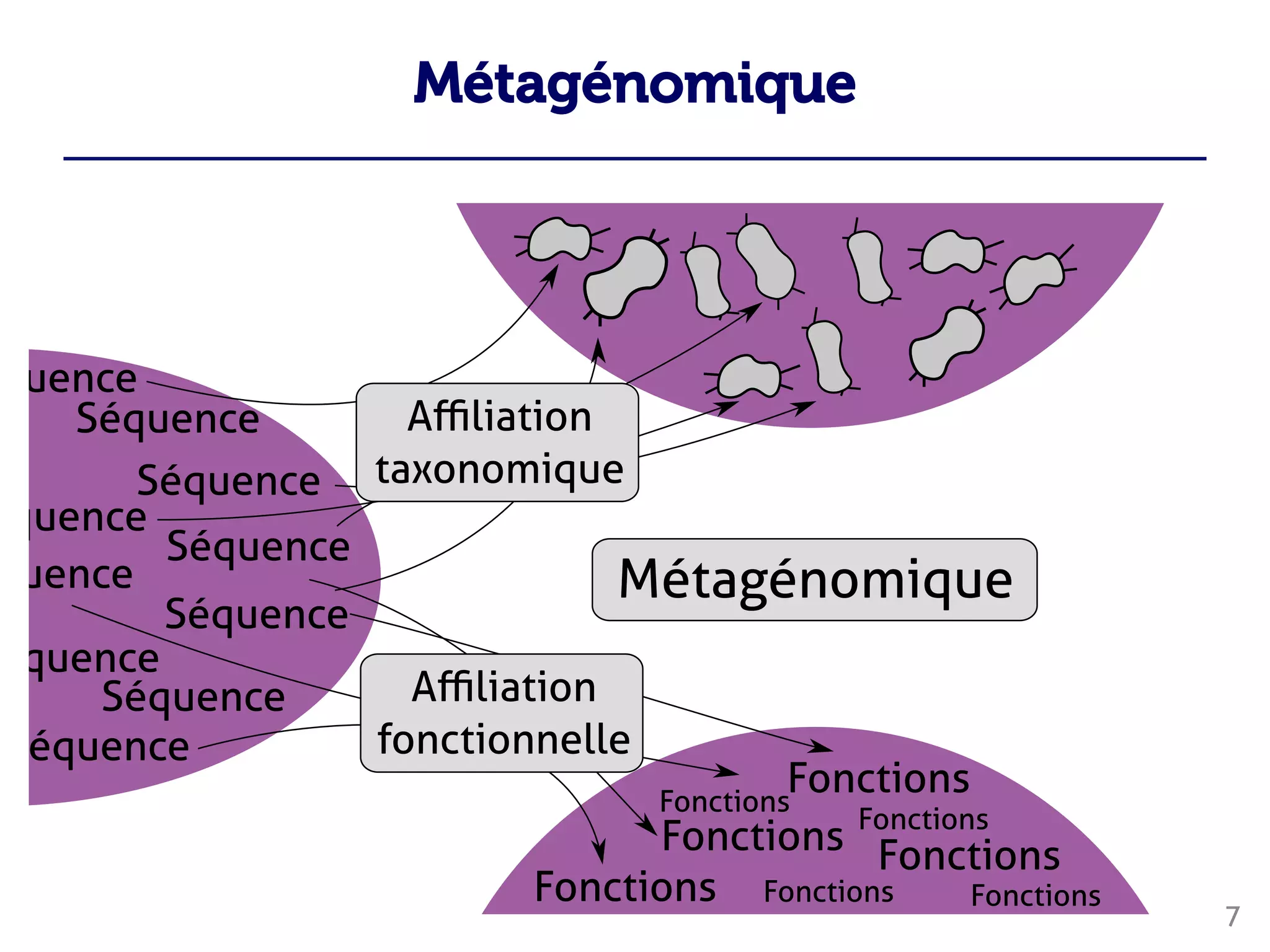
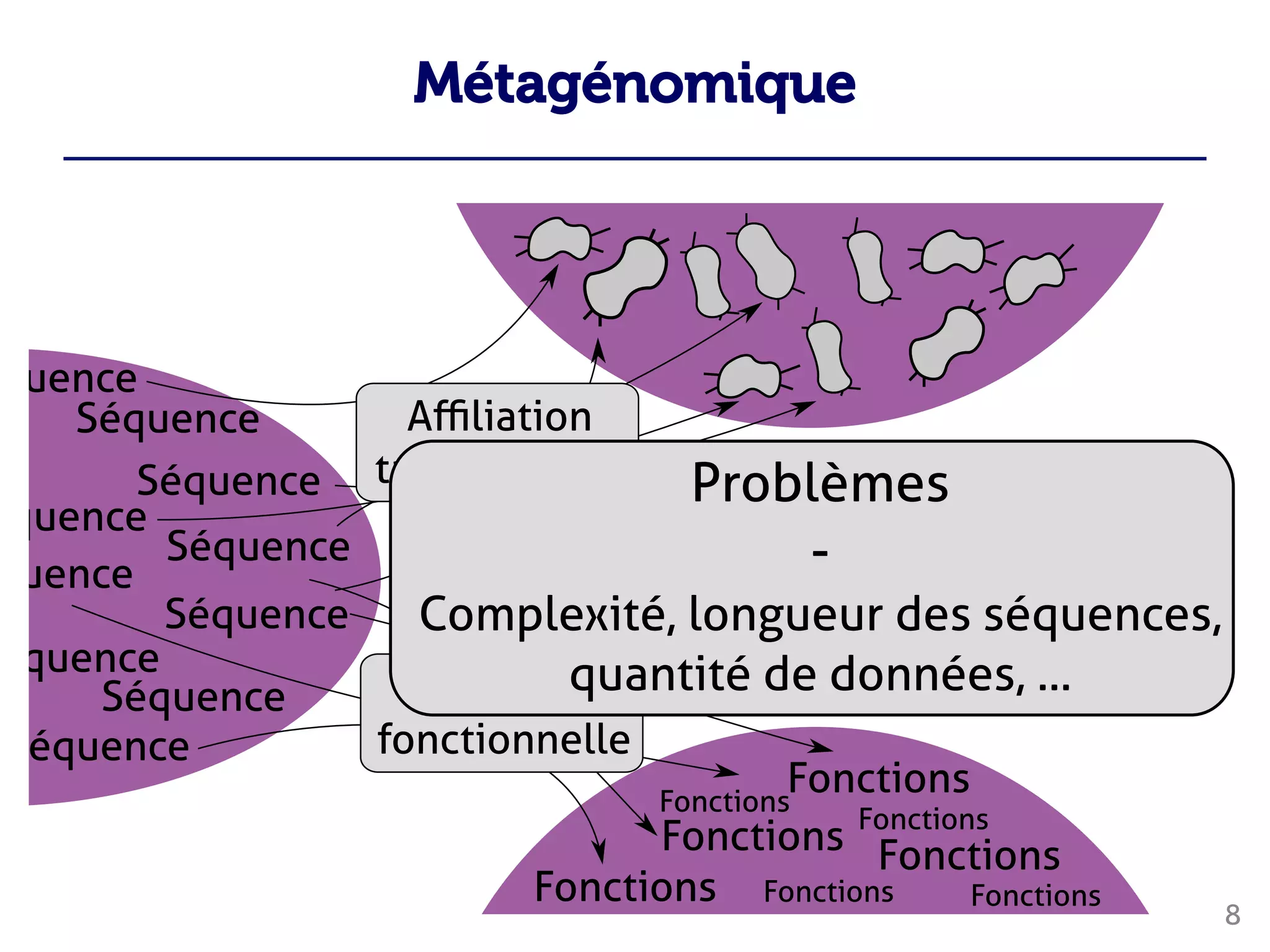






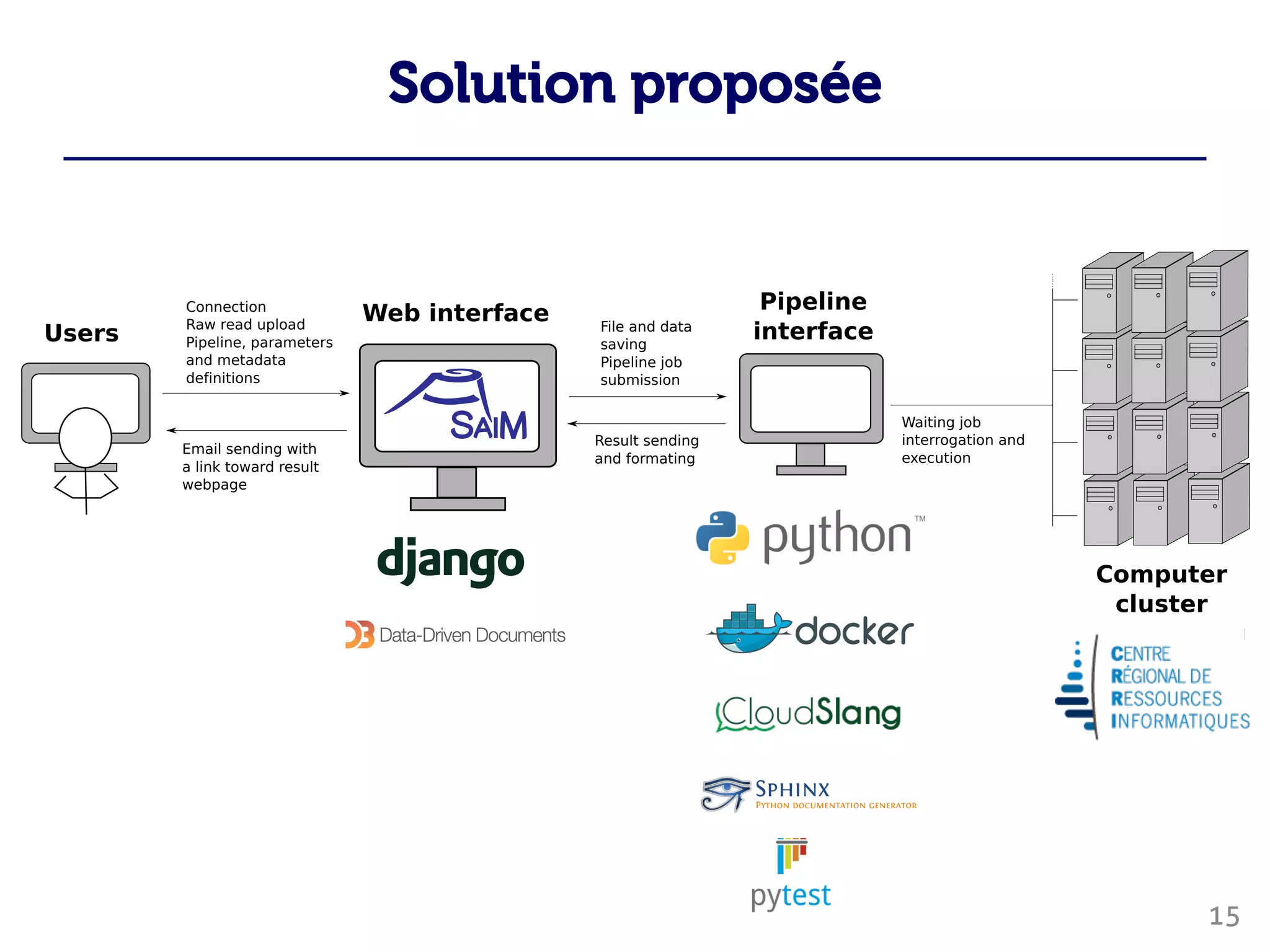
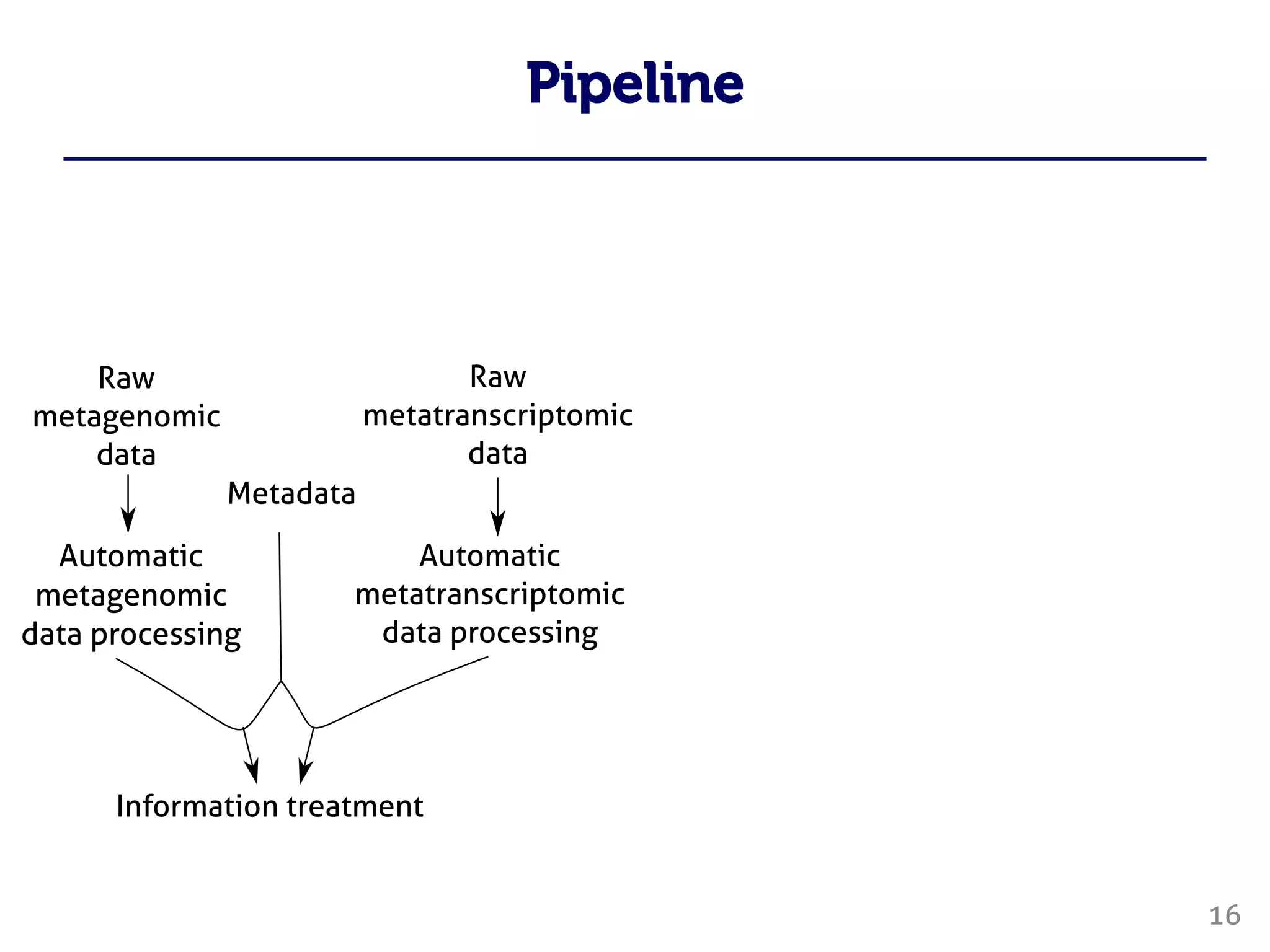
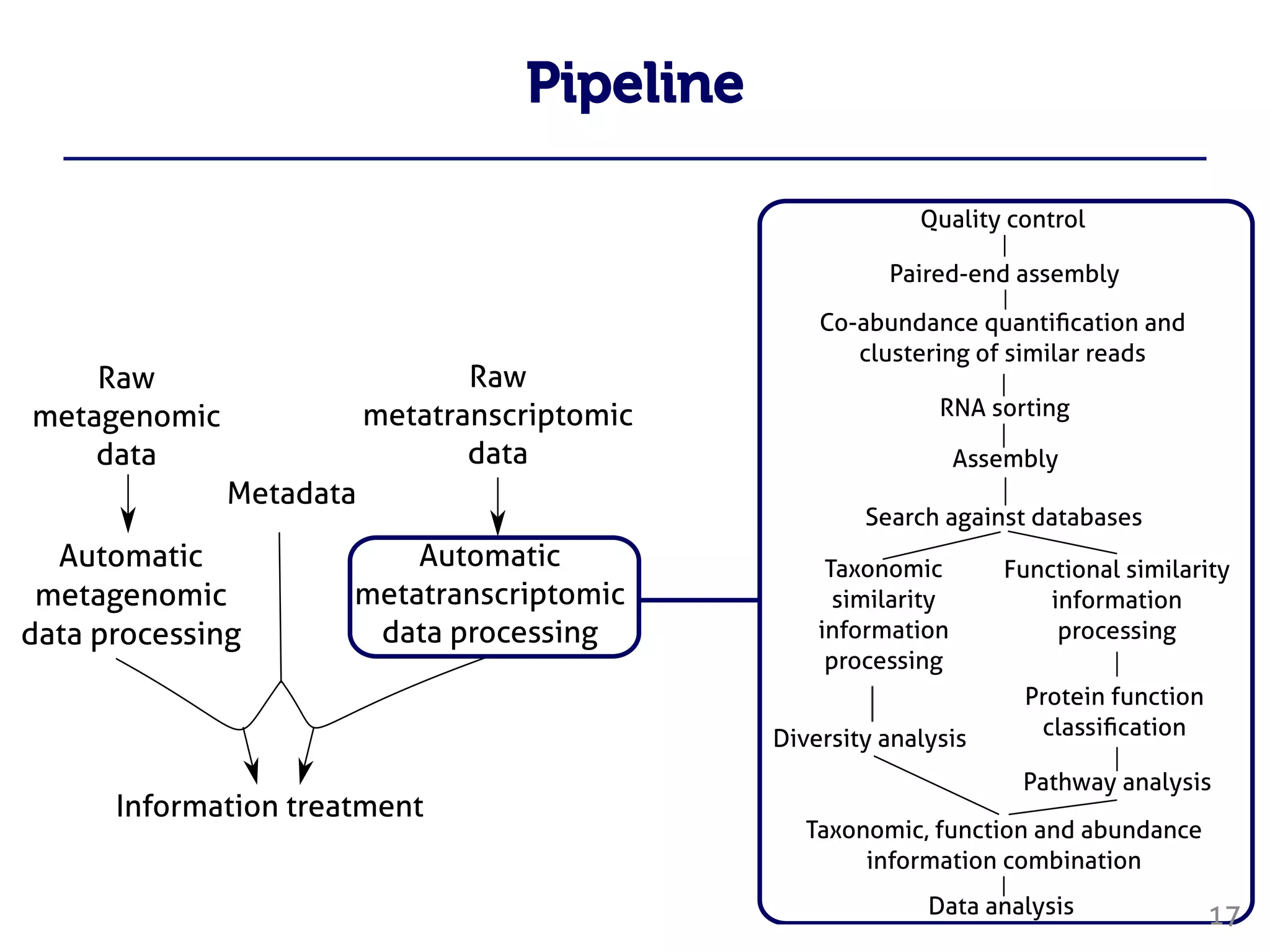



Le document traite du traitement des 'big data' en biologie, en se concentrant sur la génomique et la métagénomique. Il présente des outils et des solutions pour gérer des données massives, notamment un pipeline de traitement évolutif, tout en soulignant les défis liés à la gestion des workflows et des mises à jour des outils. Enfin, il aborde le projet CPER Auvergne en relation avec ces technologies.

![[2013.09.27] extracting genomes from metagenomes](https://cdn.slidesharecdn.com/ss_thumbnails/2013-130927034103-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![Atlas fotográfico de anatomia del cuerpo humano [3era edicion]](https://cdn.slidesharecdn.com/ss_thumbnails/anon-atlasfotograficodeanatomiadelcuerpohumano3eraedicion-140215224329-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















