Speaker Recognition using Gaussian Mixture Model
•Télécharger en tant que PPTX, PDF•
16 j'aime•12,407 vues

This presentation slide contains, Introduction to Gaussian mixture model and its application in identifying speaker.

Recommandé
Contenu connexe
Tendances
Tendances (20)
Similaire à Speaker Recognition using Gaussian Mixture Model
Similaire à Speaker Recognition using Gaussian Mixture Model (20)
Dernier
Dernier (20)
Speaker Recognition using Gaussian Mixture Model
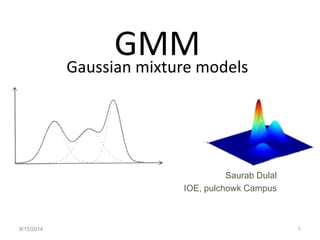
- 1. GMMGaussian mixture models 8/15/2014 1 Saurab Dulal IOE, pulchowk Campus
- 2. Introduction to GMM • Gaussian “Gaussian is a characteristic symmetric "bell curve" shape that quickly falls off towards 0 (practically)” • Mixture Model “mixture model is a probabilistic model which assumes the underlying data to belong to a mixture distribution” 2
- 3. Introduction to GMM • Mathematical Description of GMM p(x) = w1 p1 (x) + w2p2 (x) + w3 p3 (x) ……… +wn pn (x) where p(x) = mixture component w1, w2 ….. wn = mixture weight or mixture coefficient pi (x) = Density functions Fig :- Image showing Best fit Gaussian Curve 3
- 4. Introduction to GMM “The most common mixture distribution is the Gaussian (Normal) density function, in which each of the mixture components are Gaussian distributions, each with their own mean and variance parameters.” p(x) = w1N( x | µ1∑1 )+ w1N( x | µ2∑2 )… +w1N( x | µn∑n ) µi ‘s are means and ∑i ‘s are covariance-matrix of individual components(probability density function) 4 G1,w1 G2,w2 G3,w3 G4,w4 G5,w5
- 5. -5 0 5 10 0 0.1 0.2 0.3 0.4 0.5 Component 1 Component 2 p(x) -5 0 5 10 0 0.1 0.2 0.3 0.4 0.5 Mixture Model x p(x)
- 6. -5 0 5 10 0 0.1 0.2 0.3 0.4 0.5 Component 1 Component 2 p(x) -5 0 5 10 0 0.1 0.2 0.3 0.4 0.5 Mixture Model x p(x)
- 7. -5 0 5 10 0 0.5 1 1.5 2 Component Models p(x) -5 0 5 10 0 0.1 0.2 0.3 0.4 0.5 Mixture Model x p(x)
- 8. GMM for Speaker Recognition Motivation • Interpretation that Gaussian component represent some general speaker –dependent spectral shapes • Capabilities of Gaussian mixture to model arbitrary densities 8
- 9. Description of SR-using GMM • Speech Analysis • Model Description • Model Interpretations • Maximum Likelihood Parameters Estimation • Speaker Identification 9
- 10. Speech Analysis 10 • Linear predictive coding(LPC) •Mel-scale filter-bank(to reduce noise) Analysis is ended with the generation of Cepstrum coefficients x1 ’, x2 ’ x3’….xn ’ A cepstrum is the result of taking the Inverse Fourier transform (IFT) of the logarithm of the estimated spectrum of a signal. Cosine transform
- 11. 2000/05/03 11 Model Description Gaussian Mixture Density )()|( 1 xbpxp M i ii Where x D-dimensional random vector )()'( 2 1 exp )2( 1 )( 1 212 iii i Di xxxb iiip ,, Mi ,,1 Nodal, Grand,Global Nodal, diagonal (this) Covariance matrix Mean Component Density Speaker Model
- 12. Choice of Covariance Matrix 12 • Nodal Covariance One co-variance matrix per Gaussian component • Grand Covariance One co-variance matrix for all Gaussian component • Global Covariance single co-variance matrix shared by all speaker component
- 13. Model Interpretation • Intuitive notion Acoustic classes(vowels, nasals, fricatives) reflects some general speaker-dependent vocal tract configuration that are useful for characterizing speaker- identity • GMM have ability to form smooth approximation to arbitrary shaped density • It doesn’t only have smooth approx but also multimodal nature of densities 13
- 14. 2000/05/03 14 ML-Parameters Estimation Step: 1. Beginning with an initial model 2. Estimate a new model such that Mixture density 3. Repeated 2. until certain threshold is reached. …Maximum Likelihood )|()|( XpXp
- 15. 2000/05/03 15 (Mixture Weights) (Means) (Variances) T t ti xip T p 1 ),|( 1 T t t T t tt i xip xxip 1 1 ),|( ),|( 2 1 1 2 2 ),|( ),|( iT t t T t tt i xip xxip M k tkk tii t xbp xbp xip 1 )( )( ),|( Mixture Density Component Density and refers to arbitrary elements of vectors ii ,2 and tx ii ','2 'tx and
- 16. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 ANEMIA PATIENTS AND CONTROLS Red Blood Cell Volume RedBloodCellHemoglobinConcentration
- 17. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 1
- 18. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 3
- 19. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 5
- 20. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 10
- 21. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 15
- 22. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration EM ITERATION 25
- 23. 0 5 10 15 20 25 400 410 420 430 440 450 460 470 480 490 LOG-LIKELIHOOD AS A FUNCTION OF EM ITERATIONS EM Iteration Log-Likelihood
- 24. 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4 Red Blood Cell Volume RedBloodCellHemoglobinConcentration ANEMIA DATA WITH LABELS Anemia Group Control Group
- 25. 2000/05/03 25 Speaker Identification A group of speakers S = {1,2,…,S} is represented by GMM’s λ1, λ2, …, λs, the obective is to find the speaker model which has the maximum a posteriori probability for a given observation sequence )( )Pr()|( maxarg)|Pr(maxargˆ 11 Xp Xp XS kk Sk k Sk )|(maxargˆ 1 k Sk XpS )|(logmaxargˆ 1 1 kt T t Sk xpS T t tiikt xbpxp 1 )()|( which logtake
- 26. References D. A. Reynolds and R. C. Rose, “Robust Text- Independent Speaker Identification Using Gaussian Mixture Speaker Models”, IEEE Trans. on Speech and Audio Processing, vol.3, No.1, pp.72-83,January 1995. • http://en.wikipedia.org/wiki/Probability_density_function • http://crsouza.blogspot.com/2010/10/gaussian-mixture- models-and-expectation.html • https://www.ll.mit.edu/mission/communications/ist/publications /0802_Reynolds_Biometrics-GMM.pdf • http://statweb.stanford.edu/~tibs/stat315a/LECTURES/em.pdf • http://eprints.pascal network.org/archive/00008291/01/SoftAssignReconstr_ICIP20 11.pdf • http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/km eans.html 26
Notes de l'éditeur
- Linear predictive coding (LPC) is a tool used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model. It is one of the most powerful speech analysis techniques, and one of the most useful methods for encoding good quality speech at a low bit rate and provides extremely accurate estimates of speech parameters.