1. 1
Preparar: Proyecto de Analysis Service, Origen de datos y Vista al origen de datos.
El primer paso para poder implementar los escenarios de minería de datos es preparar el
Proyecto de Analysis Service, Origen de datos y Vista al origen de datos. Dicho proceso se
muestra a continuación.
1. Crear Proyecto de Analysis Service
Ejecutamos SQL Server Business Intelligence Development Studio ubicado en inicio,
todos los programas, Microsoft SQL Server 2008 (esta ubicación puede variar dependiendo
de la versión de Windows).
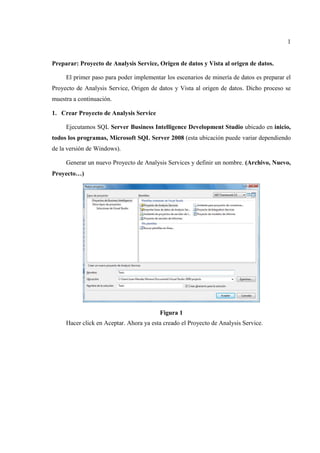
Generar un nuevo Proyecto de Analysis Services y definir un nombre. (Archivo, Nuevo,
Proyecto…)
Figura 1
Hacer click en Aceptar. Ahora ya esta creado el Proyecto de Analysis Service.
2. 2
Figura 2
2. Preparar origen de datos
Hacer click con el botón derecho sobre “Origenes de Datos” y seguidamente en “Nuevo
Origen de Datos”.
Figura 3
Seleccionar la base de datos de donde se leerán los datos, en este caso
“AdventureWorksDW2008”.
3. 3
Figura 4
Proporcionar los datos con los cuales nos conectaremos a la base de datos (en este caso
se utilizara la cuenta de servicio)
Figura 5
Asignar un nombre al origen de datos (AdventureWorksDW2008) y finalizar.
4. 4
Figura 6
Con esto ya se encuentra listo el origen de datos.
5. 5
3. Crear vista al origen de datos
Realizar click con el botón derecho sobre “Vistas del Origen de Datos” y a continuación
click sobre “Nueva Vista del Origen de Datos…”.
Figura 7
Seleccionar el origen de datos (creado con anterioridad) y realizar click en siguiente.
Figura 8
6. 6
Ahora aparecerá un listado que contiene las tablas y vistas de la base de datos
seleccionada, debe seleccionar las tablas y vistas necesarias para llevar a cabo los escenarios
de minería de datos (FactCallCenter, ProspectiveBuyer, vAssocSeqLineItems,
vAssocSeqOrders, vTargetMail y vTimeSeries).
Figura 9
Una vez realizado esto hacer click en siguiente.
Asignar un nombre a la vista del origen de datos (AdventureWorksDW2008) y
finalizamos.
7. 7
Figura 10
Ahora se hay que relacionar el atributo OrderNumber de la vista vAssocSeqLineItems
con la vista vAssocSeqOrders. Esto se realiza arrastrando el atributo OrderNumber de la tabla
vAssocSeqLineItems al atributo OrderNumber de la tabla vAssocSeqOrders.
Figura 11
Así debería lucir el proyecto con la relación entre las vistas, el origen de datos y la vista
al origen de datos creados.
9. 9
Implementación de escenarios de minería de datos permitidos por SQL Server 2008
Este anexo tiene por objetivo mostrar el paso a paso de la implementación de los distintos
escenarios de minería de datos permitidos por SQL Server, los cuales son: escenario de correo
directo, escenario de previsión, escenario de la cesta de compra, escenario de clústeres de
secuencia, escenario de red neuronal y de regresión logística.
Escenario de correo directo
El departamento de marketing de Adventure Works desea aumentar las ventas dirigiendo
una campaña de correo directo a clientes específicos. Mediante el análisis de los atributos de
clientes conocidos, la empresa espera determinar los patrones que posteriormente se aplicarán
a clientes potenciales. La empresa pretende utilizar los patrones hallados para predecir qué
clientes potenciales tienen más probabilidades de comprar un producto.
Algoritmos a utilizar:
• Árboles de decisión de Microsoft
• Clústeres de Microsoft
• Bayes naive de Microsoft
Árboles de decisión de Microsoft
Preparamos el origen de datos y la vista al origen de datos.
Seleccionamos una nueva estructura de minería de datos.
10. 10
Figura 13
Seleccionamos el método a utilizar para crear la definición de la estructura, en este caso a
partir de una base de datos relacional.
Figura 14
Seleccionamos la técnica de minería de datos a utilizar en este caso Árboles de decisión de
Microsoft.
11. 11
Figura 15
Seleccionamos la vista del origen de datos que se realizo con anterioridad.
Figura 16
Seleccionamos las tablas de la siguiente manera:
En tabla vTargetMail activamos la casilla escenario.
12. 12
Figura 17
En la página Especificar los datos de aprendizaje debemos seleccionar:
Columna clave: CustomerKey
Columna predicción: BikeBuyer
Columna entrada: BikeBuyer, Age, CommuteDistance, EnglishEducation,
EnglishOccupation, FirstName, Gender, GeographyKey, HouseOwnerFlag, LastName,
MaritalStatus, NumberCarsOwned, NumberChildrenAtHome, Region, TotalChildren y
YearlyIncome.
13. 13
Figura 18
En la página Especificar el contenido y el tipo de datos de las columnas, haga clic en Detectar
para ejecutar un algoritmo que ejecute los datos numéricos de los ejemplos y determine si las
columnas numéricas contienen valores continuos o discretos. Por ejemplo, una columna puede
contener información salarial como valores de sueldo actuales, que son continuos, o bien
integrales que representan rangos de sueldo codificados, como 1 = < $25.000; 2 = de $25.000
a $50.000, que son discretos.
Figura 19
14. 14
Después de hacer clic en Detectar, debemos revisar las entradas de las columnas Tipo de
contenido y Tipo de datos, y cambiarlas si es necesario para asegurarse de que la
configuración es igual que la que se muestra en la tabla siguiente.
Columna Tipo de contenido Tipo de datos
Age Continuous Long
BikeBuyer Discrete Long
CommuteDistance Discrete Text
CustomerKey Key Long
EnglishEducation Discrete Text
EnglishOccupation Discrete Text
FirstName Discrete Text
Gender Discrete Text
GeographyKey Discrete Text
HouseOwnerFlag Discrete Text
LastName Discrete Text
MaritalStatus Discrete Text
NumberCarsOwned Discrete Long
NumberChildrenAtHome Discrete Long
Region Discrete Text
TotalChildren Discrete Long
YearlyIncome Continuous Double
Tabla 1
Una vez que hemos verificado esto podemos hacer click en siguiente.
15. 15
En la página Crear Conjunto de Pruebas debemos dejar el porcentaje de datos para pruebas por
defecto (30%) y debemos fijar el Número máximo de casos en el conjunto de datos de prueba
en 1000.
Clic en siguiente.
Figura 20
Especificamos el nombre de la estructura de minería de datos y el nombre del modelo de
minería de datos, además debemos marcar la casilla Permitir obtención de detalles.
Finalizar
17. 17
Al terminar los pasos anteriores debemos tener lo siguiente.
Figura 22
Ahora es el momento de procesar nuestra estructura de minería de datos, haciendo clic en
Procesar estructuras de minería de datos y todos los modelos…
Figura 23
18. 18
Aparecerá la siguiente ventana, en la cual hacemos clic en ejecutar.
Figura 24
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana anteriormente.
Figura 25
Una vez terminados los pasos anteriores estamos en condiciones de explorar nuestro proyecto
de minería de datos recién creado.
19. 19
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
Figura 26
20. 20
Clústeres de Microsoft
Debido a que para nuestro escenario de correo directo ya tenemos configurados los datos de
entrada (como se realizo en el punto a), lo único que tenemos que modificar a nuestro
escenario es agregar una nueva estructura de minería de datos. Para lo cual realizamos lo
siguiente:
Nos vamos a la ficha Modelos de Minería de Datos, luego a la columna Estructura y sobre esta
realizamos un click con el botón derecho del mouse y seleccionamos Nuevo Modelo de
Minería de Datos.
Figura 27
Especificamos el Nombre del modelo y el Algoritmo a utilizar que en este caso es Microsoft
Clustering.
Figura 28
21. 21
Click en Aceptar y ahora tendremos lo siguiente:
Figura 29
A nuestro Escenario de correo directo le agregamos otro modelo de minería de datos, por lo
tanto en el mismo escenario tenemos dos modelos de minería de datos Árboles de decisión de
Microsoft y Clústeres de Microsoft.
Ahora para procesar nuestro nuevo modelo de minería de datos realizamos un click con el
botón derecho sobre la columna Clústeres de Microsoft y después hacemos click sobre la
opción Procesar modelo ...
22. 22
Figura 30
Ahora nos aparecerá la siguiente ventana, en la cual presionamos Ejecutar.
Figura 31
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Una vez terminados los pasos anteriores estamos en condiciones de explorar nuestro proyecto
de minería de datos recién creado.
23. 23
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
En algunos casos debemos especificar el Modelo de minería “Clústeres de Microsoft”, ya que
es posible que nos muestre el modelo anterior (Árboles de decisión).
Figura 32
24. 24
Bayes naive de Microsoft
Como ya vimos en el caso anterior debido a que para nuestro escenario de correo directo ya
tenemos configurados los datos de entrada (como se realizo en el punto a), lo único que
tenemos que modificar a nuestro escenario es agregar una nueva estructura de minería de
datos. Para lo cual realizamos lo siguiente:
Nos vamos a la ficha Modelos de Minería de Datos, luego a la columna Estructura y sobre esta
realizamos un click con el botón derecho del mouse y seleccionamos Nuevo Modelo de
Minería de Datos.
Figura 33
Especificamos el Nombre del modelo y el Algoritmo a utilizar que en este caso es Bayes naive
de Microsoft.
Figura 34
25. 25
Click en aceptar y nos mostrara el mensaje que este algoritmo no admite el tipo de contenido
de ciertas columnas, además nos preguntara si deseamos continuar.
Figura 35
Click en Sí y ahora tendremos lo siguiente:
Figura 36
A nuestro Escenario de correo directo le agregamos otro modelo de minería de datos, por lo
tanto en el mismo escenario tenemos tres modelos de minería de datos Árboles de decisión de
Microsoft, Clústeres de Microsoft y Bayes Naive Microsoft.
26. 26
Ahora para procesar nuestro nuevo modelo de minería de datos realizamos un click con el
botón derecho sobre la columna Bayes naive de Microsoft y después hacemos click sobre la
opción Procesar modelo ...
Figura 37
Ahora nos aparecerá la siguiente ventana, en la cual presionamos Ejecutar.
Figura 38
27. 27
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
En algunos casos debemos especificar el Modelo de minería “Bayes naive de Microsoft”, ya
que es posible que nos muestre algunos de los modelos anteriores (Árboles de decisión o
Clústeres de Microsoft).
Figura 39
28. 28
Escenario de previsión.
Como analista de ventas de Adventure Works, se ha solicitado una previsión de las
ventas de modelos individuales de bicicletas para el “próximo año”. En concreto, se debe
obtener los altos en las ventas de bicicletas y determinar qué regiones lideran las ventas y
cuáles van por detrás. Además, se debe determinar si las ventas de diferentes modelos varían
en función de la época del año.
Algoritmo a utilizar: Serie temporal de Microsoft.
Preparamos el origen de datos y la vista al origen de datos (Ver anexo A).
Seleccionamos una nueva estructura de minería de datos.
Figura 40
Seleccionamos el método a utilizar para crear la definición de la estructura, en este caso a
partir de una base de datos relacional.
29. 29
Figura 41
Seleccionamos la técnica de minería de datos a utilizar en este caso serie temporal de
Microsoft.
Figura 42
Seleccionamos la vista del origen de datos que se realizo con anterioridad.
31. 31
Activamos la casilla escenario de la tabla vtimeSeries
Figura 44
Especificamos las columnas que utilizaremos en el análisis como se observa en la figura.
Figura 45
32. 32
Siguiente
Figura 46
En este paso debemos especificar el nombre de la estructura de minería de datos y el nombre
del modelo de minería de datos.
Finalizar
Figura 47
33. 33
Al terminar los pasos anteriores debemos tener lo siguiente.
Figura 48
Ahora es el momento de procesar nuestra estructura de minería de datos de la siguiente forma:
Figura 49
34. 34
Aparecerá la siguiente ventana, en la cual colocamos ejecutar.
Figura 50
Seguidamente los aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Figura 51
35. 35
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar la predicción realizada.
Figura 52
36. 36
Escenario de la cesta de compra
El departamento de marketing de Adventure Works desea mejorar el sitio Web de la
empresa para promover las ventas cruzadas.
Antes de actualizar el sitio, necesitan crear un modelo de minería de datos que pueda
predecir los productos cuya adquisición podría interesar a los clientes, basándose en otros
productos que ya se encuentran en las cestas de la compra en línea de los clientes. Estas
predicciones también ayudarán al departamento de marketing a agrupar en el sitio Web
aquellos artículos que los clientes suelen comprar juntos.
Algoritmo a utilizar: Reglas de asociación de Microsoft.
Preparamos el origen de datos y la vista al origen de datos (Ver anexo A).
Seleccionamos una nueva estructura de minería de datos.
Figura 53
Seleccionamos el método a utilizar para crear la definición de la estructura, en este caso a
partir de una base de datos relacional.
38. 38
Seleccionamos la técnica de minería de datos a utilizar en este caso Reglas de asociación de
Microsoft.
Figura 55
Seleccionamos la vista del origen de datos que se realizo con anterioridad.
Figura 56
39. 39
Seleccionamos las tablas de la siguiente manera:
En tabla vAssocSeqOrders actibamos la casilla escenario.
En tabla vAssocSeqLineItems activamos la casilla anidado.
Figura 57
Debemos seleccionar las columnas de las tablas seleccionadas como se muestra en la figura.
Figura 58
Dado que el propósito del análisis de la cesta de la compra es determinar qué productos están
incluidos en una transacción única, no tiene que usar el campo CustomerKey. En su lugar,
usaremos OrderNumber como la clave para la tabla de casos. No tiene que usar LineNumber
40. 40
como una clave para la tabla anidada. Para este modelo de asociación, todo lo que necesita es
OrderNumber porque combina la tabla de pedidos con la tabla anidada de productos
comprados.
En esta ventana solo hacemos clic en siguiente
Figura 59
Aceptamos el porcentaje de datos de prueba (30%).
Solo hacemos clic en siguiente.
Figura 60
41. 41
Especificamos el nombre de la estructura de minería de datos y el nombre del modelo de
minería de datos, ademas debemos marcar la casilla Permitir obtención de detalles.
Finalizar
Figura 61
Al terminar los pasos anteriores debemos tener lo siguiente.
Figura 62
42. 42
Ahora es el momento de procesar nuestra estructura de minería de datos de la siguiente forma:
Figura 63
Aparecerá la siguiente ventana, en la cual colocamos ejecutar.
Figura 64
43. 43
Seguidamente los aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Figura 65
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar la predicción realizada.
Figura 66
45. 45
Escenario de clústeres de secuencia
El departamento de marketing de Adventure Works desea saber cómo se mueven los
clientes por el sitio Web de Adventure Works. La empresa cree que existe un patrón según el
cual los clientes incluyen productos en las cestas de la compra. Con el algoritmo de Clústeres
de secuencia de Microsoft, pueden buscar secuencias que proporcionen información sobre la
manera en la que los clientes agregan elementos relacionados a sus cestas. Posteriormente,
esta información se puede utilizar para mejorar el flujo del sitio Web y propiciar que los
clientes adquieran productos adicionales.
Algoritmo a utilizar: Clústeres de secuencia de Microsoft.
Preparamos el origen de datos y la vista al origen de datos (Ver anexo A).
Seleccionamos una nueva estructura de minería de datos.
Figura 68
Seleccionamos el método a utilizar para crear la definición de la estructura, en este caso a
partir de una base de datos relacional.
47. 47
Seleccionamos la técnica de minería de datos a utilizar en este caso Clústeres de secuencia de
Microsoft.
Figura 70
Seleccionamos la vista del origen de datos que se realizo con anterioridad.
Figura 71
48. 48
Seleccionamos las tablas de la siguiente manera:
En tabla vAssocSeqOrders actibamos la casilla escenario.
En tabla vAssocSeqLineItems activamos la casilla anidado.
Figura 72
En la página Especificar los datos de aprendizaje debemos seleccionar las columnas de las
tablas seleccionadas como se muestra en la figura.
Figura 73
49. 49
En la página Especificar el contenido y el tipo de datos de las columnas, compruebe que la
cuadrícula contiene los tipos de contenido y las columnas siguientes y, a continuación, haga
clic en Siguiente.
Figura 74
En esta página debemos modificar el porcentaje de datos para pruebas de 30% a 20%.
Clic en siguiente.
Figura 75
50. 50
Especificamos el nombre de la estructura de minería de datos y el nombre del modelo de
minería de datos, además debemos marcar la casilla Permitir obtención de detalles.
Finalizar
Figura 76
Al terminar los pasos anteriores debemos tener lo siguiente.
Figura 77
51. 51
Ahora es el momento de procesar nuestra estructura de minería de datos, haciendo clic en
Procesar estructuras de minería de datos y todos los modelos…
Figura 78
Aparecerá la siguiente ventana, en la cual hacemos clic en ejecutar.
Figura 79
52. 52
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Figura 80
Una vez terminados los pasos anteriores estamos en condiciones de explorar nuestro proyecto
de minería de datos recién creado.
53. 53
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
Figura 81
El visor de clústeres de secuencia de Microsoft contiene cinco fichas: Diagrama del clúster,
Perfiles del clúster, Características del clúster, Distinción del clúster y Transiciones de estado.
54. 54
Escenario de red neuronal y de regresión logística
El departamento de operaciones de Adventure Works está ocupado en un proyecto para
mejorar la satisfacción del cliente con su centro de llamadas. Han contratado a un proveedor
para administrar el centro de llamadas y proporcionar métricas sobre la efectividad del centro
de llamadas, y han solicitado el análisis de algunos datos preliminares que proporciona el
proveedor con el fin de encontrar hallazgos interesantes. En particular, desean saber si los
datos sugieren algún problema con el personal o métodos para mejorar el tipo de respuesta.
El conjunto de datos cubre un período de 30 días en el funcionamiento del centro de
llamadas. Los datos realizan el seguimiento del número de operadores en cada turno, el
número de llamadas y pedidos, el tiempo de respuestas y una métrica de grado de servicio
basado en la tasa de abandono, un indicador de la frustración del cliente.
Puesto que no se cuenta con expectativas a priori sobre lo que mostrarán los datos, se
decide usar un modelo de red neuronal para explorar posibles correlaciones. En la detección de
conocimiento se suelen utilizar modelos de red neuronal que pueden analizar relaciones
complejas entre un alto número de entradas y salidas.
Cuando se determinen los factores que contribuyen a la satisfacción del cliente con el
centro de llamadas, se generará un modelo de regresión que se pueda utilizar para realizar
predicciones sobre cómo el personal y otras decisiones comerciales cotidianas.
Algoritmos a utilizar:
• Red Neuronal de Microsoft
• Regresión logística de Microsoft
Escenario de Red Neuronal de Microsoft
Preparamos el origen de datos y la vista al origen de datos (Ver anexo A).
Seleccionamos una nueva estructura de minería de datos.
56. 56
Seleccionamos el método a utilizar para crear la definición de la estructura, en este caso a
partir de una base de datos relacional.
Figura 83
Seleccionamos la técnica de minería de datos a utilizar en este caso Red Neuronal de
Microsoft.
Figura 84
57. 57
Seleccionamos la vista del origen de datos que se realizo con anterioridad.
Figura 85
Seleccionamos las tablas de la siguiente manera:
En tabla FactCallCenter la casilla escenario.
Figura 86
58. 58
En la página Especificar los datos de aprendizaje debemos seleccionar las columnas de la tabla
seleccionada de la siguiente forma:
Clave: FactCallCentreID
Entrada: AutomaticResponses, AverageTimePerIssue, Calls, IssuesRaised,
LevelOneOperators, LevelTwoOperators, Orders, ServiceGrade, Shift y WageType.
De predicción: AverageTimePerIssue, LevelOneOperators, Orders, ServiceGrade.
Figura 87
59. 59
En la página Especificar el contenido y el tipo de datos de las columnas, compruebe que la
cuadrícula contiene los tipos de contenido y las columnas siguientes y, a continuación, haga
clic en Siguiente.
Figura 88
En la página Crear conjunto de pruebas, debemos modificar el porcentaje de datos para
pruebas de 30% a 20%.
Clic en siguiente.
Figura 89
60. 60
Especificamos el nombre de la estructura de minería de datos y el nombre del modelo de
minería de datos.
Finalizar
Figura 90
Al terminar los pasos anteriores debemos tener lo siguiente.
Figura 91
61. 61
Ahora es el momento de procesar nuestra estructura de minería de datos, haciendo clic en
Procesar estructuras de minería de datos y todos los modelos…
Figura 92
Aparecerá la siguiente ventana, en la cual hacemos clic en ejecutar.
Figura 93
62. 62
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana mostrada anteriormente.
Figura 94
Una vez terminados los pasos anteriores estamos en condiciones de explorar nuestro proyecto
de minería de datos recién creado.
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
Figura 95
63. 63
Escenario de regresión logística de Microsoft
Debido a que para nuestro escenario de red neuronal y regresión logística ya tenemos
configurados los datos de entrada (como se realizo en el punto a), lo único que tenemos que
modificar a nuestro escenario es agregar una nueva estructura de minería de datos. Para lo cual
realizamos lo siguiente:
Nos vamos a la ficha Modelos de Minería de Datos, luego a la columna Estructura y sobre esta
realizamos un click con el botón derecho del mouse y seleccionamos Nuevo Modelo de
Minería de Datos.
Figura 96
Especificamos el Nombre del modelo y el Algoritmo a utilizar que en este caso es Microsoft
Logistic Regression.
Figura 97
64. 64
Click en Aceptar y ahora tendremos lo siguiente:
Figura 98
Al Escenario de red neuronal y regresión logística se le ha agregado otro modelo de minería de
datos, por lo tanto en el mismo escenario tenemos dos modelos de minería de datos Redes
Neuronales y Regresión Logística.
Ahora para procesar nuestro nuevo modelo de minería de datos realizamos un click con el
botón derecho sobre la columna Regresión Logística y después hacemos click sobre la opción
Procesar modelo ...
Figura 99
65. 65
Ahora nos aparecerá la siguiente ventana, en la cual presionamos Ejecutar.
Figura 100
Seguidamente nos aparecerá una ventana que nos indica el progreso del proceso, el cual una
vez que finalice lo cerramos. Además debemos cerrar la ventana anteriormente.
Una vez terminados los pasos anteriores estamos en condiciones de explorar nuestro proyecto
de minería de datos recién creado.
66. 66
Ahora nos vamos a la pestaña de visor de modelos de minería de datos, en la cual podemos
observar lo siguiente:
En algunos casos debemos especificar el Modelo de minería “Regresión Logística”, ya que es
posible que nos muestre el modelo anterior (Red neuronal).
Figura 101