Phd defense - Linked data based exploratory search - Nicolas MARIE

The general topic of the thesis is web search. It focused on how to leverage the data semantics for exploratory search. Exploratory search refers to cognitive consuming search tasks that are open-ended, multi-faceted, and iterative like learning or topic investigation. Semantic data and linked data in particular offer new possibilities to solve complex search queries and information needs including exploratory search ones. In this context the linked open data cloud plays an important role by allowing advanced data processing and innovative interactions model elaboration. First, we detail a state-of-the-art review of linked data based exploratory search approaches and systems. Then we propose a linked data based exploratory search solution which is mainly based on an associative retrieval algorithm. We started from a spreading activation algorithm and proposed new diffusion formula optimized for typed graph. Starting from this formalization we proposed additional formalizations of several advanced querying modes in order to solve complex exploratory search needs. We also propose an innovative software architecture based on two paradigmatic design choices. First the results have to be computed at query-time. Second the data are consumed remotely from distant SPARQL endpoints. This allows us to reach a high level of flexibility in terms of querying and data selection. We specified, designed and evaluated the Discovery Hub web application that retrieves the results and present them in an interface optimized for exploration. We evaluate our approach thanks to several human evaluations and we open the discussion about new ways to evaluate exploratory search engines. Main contributions of the thesis: • A state-of-the-art review of semantic exploration systems • Several exploratory search algorithms • Their innovative implementations and calibrations on top of DBpedia (the semantic Wikipedia) • The Discovery Hub exploratory search system web application • The evaluations of the algorithms' results and of the interface: http://discoveryhub.co • A novel experimentation protocol for evaluating exploratory search systems
![COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
10 blue links paradigm,
Simple, fast
Exploratory search
bottleneck
Exploratory search: open search tasks having a general objective
like learning or investigating a poorly known topic
Search is only a partially solved
problem
[White, 2009]](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommandé
Recommandé
Contenu connexe
Similaire à Phd defense - Linked data based exploratory search - Nicolas MARIE
Similaire à Phd defense - Linked data based exploratory search - Nicolas MARIE (20)
Dernier
Dernier (20)
Phd defense - Linked data based exploratory search - Nicolas MARIE
- 1. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Linked data based exploratory search Phd defense – Nicolas MARIE – 12.12.2014
- 2. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. 10 blue links paradigm, Simple, fast Exploratory search bottleneck Exploratory search: open search tasks having a general objective like learning or investigating a poorly known topic Search is only a partially solved problem [White, 2009]
- 3. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. 10 blue links paradigm, Simple, fast Exploratory search bottleneck Exploratory search: open search tasks having a general objective like learning or investigating a poorly known topic
- 4. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. 10 blue links paradigm, Simple, fast Exploratory search bottleneck
- 5. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. <1990 Web <2001 + Semantic web <2007 + Linked data <2012 +Proprietary KG Semantic search refers to the incorporation of structured semantics in search
- 6. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Human Computer Information Retrieval Linked data based exploratory search Research questions
- 7. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Human Computer Information Retrieval Linked data based exploratory search Research questions • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize a data based exploration at the interaction level? • How to evaluate such exploratory search systems?
- 8. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion
- 9. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient execution over distant linked datasets • Contribution 3: a novel interaction model and its implementation in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 10. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient execution over distant linked datasets • Contribution 3: a novel interaction model and its implementation in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 11. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. State-of-the-art review Linked data • Browsers • Recommenders • Exploratory search systems
- 12. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. State-of-the-art review Linked data • Browsers • Recommenders • Exploratory search systems
- 13. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. State-of-the-art review Linked data • Browsers • Recommenders • Exploratory search systems Trade-off
- 14. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Systems matrix
- 15. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Timeline
- 16. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Opportunities identification Semantic search aspects
- 17. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Opportunities identification Exploratory search aspects
- 18. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their innovative implementation over linked datasets • Contribution 3: a novel interaction model and its application in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 19. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Algorithm - challenges • Richness/complexity of linked datasets • Supporting diverse exploration needs
- 20. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Spreading activation • Well-tried algorithm • Connectionist • Semantic friendly • Fast 1.0
- 21. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 22. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 23. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 24. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Semantic spreading activation Filtering Similarity Semantic weighting
- 25. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 26. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 27. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 28. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 29. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. a w g q j k s m i p e o b n 1 class propagation domain: Artist, Museum
- 30. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. a w g q j k s m i p e o b n 1 class propagation domain: Artist, Museum
- 31. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. a w g q s m p e o n 1 , dcterms:category, ?x , dcterms:category, ?x Similarity computation
- 32. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. a w g q s m p e o n 1 a(...)a(...) * 4 a(...) a(...) a(...) * 3 a(...) a(...) a(...) a(...) a(...) * 2 a(...) * 3 , dcterms:category, ?x , dcterms:category, ?x Category:People from Paris Category:French painters Category:Impressionist painters = +3 Similarity computation a(...) a(...)
- 33. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Composites interest queries: knowing my interest for X and Y what can I discover/learn which is related to all these resources? The BeatlesKen Loach Polycentric algorithm ?????
- 34. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Composites interest queries: knowing my interest for X and Y what can I discover/learn which is related to all these resources? Ken Loach Polycentric algorithm Margaret Thatcher ?????
- 35. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 36. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 37. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 38. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 39. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 40. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Polycentric semantic spreading activation Propagation domain ( ) Propagation domain ( , ) Bands, Movies, Music genre Movies, Office Holder, Political party
- 41. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Multi-perspectives exploration The models and algorithms we propose unveil topic knowledge nuances by allowing the exploration of topics through several perspectives. In the graph context of linked data these perspectives correspond to different non exclusive sets of objects and relations that are informative on a topic regarding specific aspects. Flexible querying and data processing
- 42. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. 2 perspective-operations to expose the topic knowledge nuances • Criteria of interest specification • Controlled randomness injection Multi-perspectives exploration
- 43. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. , dcterms:category, ?x , dcterms:category, ?x Classic similarity measure , dcterms:category, ?a | ?b | ?c |... , dcterms:category, ?a | ?b | ?c |... Criteria spec. similarity Multi-perspectives
- 44. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. , dcterms:category, ?x , dcterms:category, ?x Classic similarity measure , dcterms:category, ?a | ?b | ?c |... , dcterms:category, ?a | ?b | ?c |... Criteria spec. similarity Multi-perspectives
- 45. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Chosen level of randomness Multi-perspectives
- 46. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Chosen level of randomness Multi-perspectives
- 47. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient execution over distant linked datasets • Contribution 3: a novel interaction model and its application in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 48. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Computing the results from distant datasets • Computing the results on run-time Algorithm execution - challenge
- 49. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Remote LOD sourceComputation at query-time from distant linked datasets
- 50. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 51. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 52. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 53. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 54. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 55. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 56. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Dbpedia 3.7 • 3.4 million resources • 270 million triples • Spread in both direction • Categories based similarity Settings Mirizzi and al., 2010
- 57. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Import size Result quality Iterations Trade-off
- 58. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Algorithm studied on 100.000 representative DBpedia queries obtained with a random walker J. Leskovec and C. Faloutsos. Sampling from large graphs, 2006 Algorithm behavior analysis
- 59. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis - Number of iterations
- 60. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis - Number of iterations
- 61. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis – Triples imported
- 62. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis – Triples imported
- 63. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 64. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 65. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 66. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 67. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 68. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 69. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 70. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Remote LOD source Computation at query-time ? ? ? ?? Analysis – Convergence polycentric
- 71. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Classic – top 5 artists « French / not impressonist » criteria specification – top 5 artists « Not French / Impressonist » criteria specification – top 5 artists
- 72. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Discovery Hub Local Kgram instance Data source selection fr.dbpedia.org/sparql it.dbpedia.org/sparql de.dbpedia.org/sparql es.dbpedia.org/sparql dbpedia.org/sparql
- 73. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Discovery Hub Local Kgram instance Data source selection fr.dbpedia.org/sparql it.dbpedia.org/sparql de.dbpedia.org/sparql es.dbpedia.org/sparql dbpedia.org/sparql Analysis: 700 queries from the Discovery Hub query-log
- 74. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Discovery Hub Local Kgram instance Data source selection fr.dbpedia.org/sparql it.dbpedia.org/sparql de.dbpedia.org/sparql es.dbpedia.org/sparql dbpedia.org/sparql Analysis: 700 queries from the Discovery Hub query-log
- 75. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis on random graphs Monocentric algorithm behavior analyzed on 3700+ random graphs having diverse characteristics
- 76. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Analysis on random graphs Monocentric algorithm behavior analyzed on 3700+ random graphs having diverse characteristics
- 77. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient execution over distant linked datasets • Contribution 3: a novel interaction model and its application in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 78. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Build an intuitive and supportive interface • Favor the users engagement Interactions - challenge
- 79. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Application design http://discoveryhub.co
- 80. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Application design http://discoveryhub.co
- 81. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. http://discoveryhub.co
- 82. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Examples of evolutions
- 83. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Examples of evolutions
- 84. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Favoris Nouvelle recherche TEMPS Debut test Free Jazz 24s Free improvisation 33s (fiche) Avant-garde 47s John Coltrane (vidéo) 1min 28 Marc Ribot 2min11 (fiche) experimental music 2min18 2min23 Krautrock 2min31 (fiche) Progressive rock 2min37 2min39 Red (King Crimson album) 2m52 2min59 King Crimson 3min05 (fiche) Jazz fusion 3min18 (fiche) Free Jazz 3min32 3min54 Sun Ra 4min18 (fiche) Hard bop 4min41 4min47 Charles Mingus (vidéo) 5min29 (fiche) Third Stream (vidéo) 6min20 Bebop 7min19 Modal jazz 7min26 (fiche) Saxophone 7min51 7min55 Mel Collins 21st Century Schizoid Band Crimson Jazz Trio (fiche) King Crimson (fiche) Robert Fripp Miles Davis Thelonious Monk (fiche) Blue Note Record McCoy Tyner (fiche) Modal Jazz (fiche) Jazz Chick Corea (fiche) Jazz Fusion Return to Forever Mahavishnu Orchestra Shakti (band) U.Srinivas Bela Fleck Flecktones John McLaughlin (musician) Dixie Dregs FICHE Dixie Degs T Lavitz Jordan Rudess Behold… The Arctopus (fiche) Avant-garde metal Unexpected FICHE unexpected Dream Theater King Crimson (fiche) Jazz fusion King Crimson Tony Levin (fiche) Anderson Bruford Wakeman Howe (fiche) Rike Wakeman (vidéo) Fin test Ongoing work – Palagi, Giboin and al.
- 85. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient execution over distant linked datasets • Contribution 3: a novel interaction model and its application in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 86. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Designing exploratory search evaluation protocols • Evaluating all the Discovery Hub algorithms Evaluation - challenge
- 87. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Using Cases Compared to sSVM [Mirizzi and al., 2010]
- 88. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Hypotheses 1. The MSSA algorithm gives results at least as relevant as the sVSM one, even if it is not domain-optimized 2. The MSSA algorithm has less degradation than the sVSM algorithm 3. There is a greater chance that the results are less relevant but newer to users at the end of the lists. 15 participants, questions 1. With the film A, I think I will live a similar cinematographic experience as with the film B ? Strongly agree, agree, disagree, strongly disagree 2. You and the film A ? Seen, known but not seen, unknown Monocentric evaluations
- 89. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Very relevant Not relevant at all Monocentric evaluations
- 90. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Very relevant Not relevant at all Hypothesis 1: The SSA algorithm gives results at least as releva the sVSM one
- 91. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Very relevant Not relevant at all Known Not known Hypothesis 2: The SSA algorithm has less degradation than the sVSM one.
- 92. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Very relevant Not relevant at all Known Not known Hypothesis 3: There is a greater chance that the results are less relevant but newer to users at the end of the lists.
- 93. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Very relevant Not relevant at all Hypothesis 4: The explanatory features increase the users’ overall judgments positivity.
- 94. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Random combination Evaluated using dbpedia:A dbpedia:B dbpedia:C dbpedia:D = = = = dbpedia:A & dbpedia:D Hypothesis 5: the composite-query results are interesting to the users Hypothesis 6: a consequent proportion of the results are unexpected; they favor discoveries Question 1: The result interests me: [Strongly agree, agree, disagree, strongly disagree]. Question 2: The result is unexpected: [strongly agree, agree, disagree, strongly disagree]
- 95. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. •61.6% of the results were rated as strongly relevant or relevant by the participants. •65% of the results were rated as strongly unexpected or unexpected. •35.4% of the results were rated both as strongly relevant or relevant and strongly unexpected or unexpected. Hypothesis 5: the composite-query results are interesting to the users Hypothesis 6: a consequent proportion of the results are unexpected
- 96. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Helpful Not helpful at all Hypothesis 7: The explanatory features help the users to understand results
- 97. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Using Information visualization Serge Gainsbourg Algorithm variants compared: • Basis • Criteria • Randomized - 0.5 • Randomized - 1 Advanced querying evaluation
- 98. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Hypotheses • Hypothesis 8: The users who specify their criteria of interest find the results of the search more relevant • Hypothesis 9: The users who specify their criteria of interest do not find the results less novel • Hypothesis 10: The stronger is the level of randomness the more surprising the results are for the users. • Hypothesis 11: Even if the level of surprise is high, the majority of the top results are still relevant to the users.
- 99. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Questions 1. Is the result in itself is surprising? 2. Is the relation between the result and the query is surprising? 3. Is the result interesting? 4. Is the result too distant from the topic searched? Very close 1-2-3-4 Too distant. Not agreeat all 1-2-3-4 Totally agree
- 100. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 101. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 102. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 103. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 104. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 105. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Plan • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest? • How to address remote linked data source for this selection? • How to optimize such data based exploration approach at the interaction level? • How to evaluate such exploratory search systems? • State-of-the-art review • Conclusion • Contribution 1: several exploratory search algorithms optimized for linked datasets • Contribution 2: their efficient implementation over distant linked datasets • Contribution 3: a novel interaction model and its application in the Discovery Hub web application • Contribution 4: multiple users’ evaluations of the Discovery Hub results
- 106. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Contribution 1: four exploratory search algorithms leveraging the linked data semantics Monocentric Polycentric Criteria variant Randomized variant … … … … Contribution summary • How can we discover and rank linked resources to be explored starting from the user topic(s) of interest?
- 107. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Contribution 1: four exploratory search algorithms leveraging the linked data semantics Monocentric Polycentric Criteria variant Randomized variant … … … … Contribution summary
- 108. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • How to address remote linked data source for this selection? Contribution summary • Contribution 2: efficient algorithm implementation over distant linked datasets
- 109. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • How to optimize such data based exploration approach at the interaction level? Contribution summary • Contribution 3: a novel interaction model and its application in the Discovery Hub web application
- 110. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • How to evaluate such exploratory search systems? • Contribution 4: multiple users’ evaluations of the Discovery Hub results 3 user evaluations Contribution summary
- 111. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Short-term improvements -Facet and collection-levels interactions -Collaborative exploratory search -Post-query re-ranking -New query-means
- 112. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Long-term perspectives - Negative search - Adaptive queries recommendation - Collection-based knowledge creation - On-the-fly distributed data selection - Massive use and commercial success
- 113. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Other achievements 7 other publications in the fields of social networks and web sciences, sciences, including Web Sciences 2012 Winner of the Challenge Jeunes Pousses 2013, in teamSeveral interventions during technological events
- 114. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Other achievements 7 other publications in the fields of social networks and web sciences, sciences, including Web Sciences 2012 Winner of the Challenge Jeunes Pousses 2013, in teamSeveral interventions during technological events
- 115. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Other achievements 7 other publications in the fields of social networks and web sciences, sciences, including Web Sciences 2012 Winner of the Challenge Jeunes Pousses 2013, in teamSeveral interventions during technological events
- 116. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Other achievements 7 other publications in the fields of social networks and web sciences, sciences, including Web Sciences 2012 Winner of the Challenge Jeunes Pousses 2013, in teamSeveral interventions during technological events
- 117. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. • Nicolas Marie, Fabien Gandon. Demonstration of multi-perspective exploratory search with the Discovery Hub web application, ISWC2014, Riva Del Garda, Italy (demo) • Nicolas Marie, Fabien Gandon. Survey of linked data based exploration systems, IESD2014, Riva Del Garda, Italy (long paper) • Nicolas Marie, Fabien Gandon, Alain Giboin, Emilie Palagi. Exploratory search on topics through different perspectives with DBpedia, Semantics 2014, Leipzig, Germany (long paper) • Nicolas Marie, Fabien Gandon, Myriam Ribière, Florentin Rodio. Discovery Hub: on-the-fly linked data exploratory search, I-Semantics 2013, TU Graz, Austria (long paper) • Nicolas Marie, Fabien Gandon, Damien Legrand, Myriam Ribière. Exploratory search on the top of DBpedia chapters with the Discovery Hub application (demo + poster) • Nicolas Marie, Olivier Corby, Fabien Gandon, Myriam Ribière. Composite interests’ exploration thanks to on-the-fly linked data spreading activation, Hypertext 2013, Paris (long paper) 16% acceptance rate ESWC Best demonstration award Thank you ! Questions ?
- 118. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Annexes
- 119. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 120. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. Tomaso Di Noia and al. Linked Open Data to support Content-based Recommender Systems. I-Semantics
- 121. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. [Passant, 2010] [Mirizzi, 2010] Wateilonis, 2010
- 122. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 123. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 124. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. p.223
- 125. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED. p.216
- 126. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 127. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 128. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 129. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 130. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 131. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 132. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 133. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 134. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 135. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 136. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 137. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 138. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 139. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 140. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 141. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 142. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
- 143. COPYRIGHT © 2011 ALCATEL-LUCENT. ALL RIGHTS RESERVED.
Notes de l'éditeur
- (Thank you for the introduction) Prononciation: Degree => digri Distant => distant Retrieve => ritrive Variety => vayarety Engine => enjine Behavior => behaivior Spread => spraide Studied => studid Criteria => cryteria
- This is our starting point. Even if search is very popular today, search engines poorly solve several complex information need. (CLIC) This is the case of exploratory search. Exploratory search refers to open search tasks having a general objective like learning or investigation. During exploratory search the users are generally unfamiliar with the topic explored. (CLIC) The actual search engines are not adapted to this kind of search. They do not support sufficiently the users. The main reason is that the simplicity of the interface and of the interactions they propose act as an informational bottleneck that limit the exploratory search potential.
- This is our starting point. Even if search is very popular today, search engines poorly solve several complex information need. (CLIC) This is the case of exploratory search. Exploratory search refers to open search tasks having a general objective like learning or investigation. During exploratory search the users are generally unfamiliar with the topic explored. (CLIC) The actual search engines are not adapted to this kind of search. They do not support sufficiently the users. The main reason is that the simplicity of the interface and of the interactions they propose act as an informational bottleneck that limit the exploratory search potential.
- This is our starting point. Even if search is very popular today, search engines poorly solve several complex information need. (CLIC) This is the case of exploratory search. Exploratory search refers to open search tasks having a general objective like learning or investigation. During exploratory search the users are generally unfamiliar with the topic explored. (CLIC) The actual search engines are not adapted to this kind of search. They do not support sufficiently the users. The main reason is that the simplicity of the interface and of the interactions they propose act as an informational bottleneck that limit the exploratory search potential.
- At the same times search engines evolve more and more toward semantic search (CLIC) Numerous publications have proven that semantic approaches benefit to search, especially for solving complex queries and needs. A vast deployment of structured data on the web is necessary to enable web-scale semantic search (CLIC) In this context the linked open data initiative is particularly interesting because it is the biggest public source of structured knowledge available today. Each triple of the LOD constitute an arc of a global information and knowledge graph (CLIC) Recently the major search engines such also released proprietary knowledge graphs to empower their own services
- As exploratory search remains an open challenge and as semantic search can help to solve complex information needs it is particularly promising to build exploratory search applications on top of large semantic data sources Exploratory search enjines are called « Human Computer Information Retrieval systems to underline how the human interactions and the users implication are critical for them Consequently the four research questions addressed by this thesis are transversal to information retrieval and human computer interactions: (CLIC) First, how can we discover and rank linked resources to be explored starting from the user topic(s) of interest? (CLIC) Second, how to address remote linked data source for this selection? (CLIC) Third, how to optimize such data based exploration approach at the interaction level? (CLIC) Fourth, how to evaluate such exploratory search systems?
- As exploratory search remains an open challenge and as semantic search can help to solve complex information needs it is particularly promising to build exploratory search applications on top of large semantic data sources Exploratory search enjines are called « Human Computer Information Retrieval systems to underline how the human interactions and the users implication are critical for them Consequently the four research questions addressed by this thesis are transversal to information retrieval and human computer interactions: (CLIC) First, how can we discover and rank linked resources to be explored starting from the user topic(s) of interest? (CLIC) Second, how to address remote linked data source for this selection? (CLIC) Third, how to optimize such data based exploration approach at the interaction level? (CLIC) Fourth, how to evaluate such exploratory search systems?
- In order to answer these research questions we proposed the following contributions: 0- A state-of-the-art review of the semantic exploration and discovery systems 1- (CLIC) Several exploratory search algorithms optimized for semantic data and linked data in particular. 2- (CLIC) An efficient approach to execute these algorithm at query-time on remote linked data source. 3-(CLIC) novel interaction model optimized for exploratory search and its implementation in the Discovery Hub application. 4-(CLIC) Several users’ evaluations of the proposed algorithms and of some elements of the Discovery Hub interface (CLIC) First, the state-of-the-art-review (3 mins 26)
- In order to answer these research questions we proposed the following contributions: 0- A state-of-the-art review of the semantic exploration and discovery systems 1- (CLIC) Several exploratory search algorithms optimized for semantic data and linked data in particular. 2- (CLIC) An efficient approach to execute these algorithm at query-time on remote linked data source. 3-(CLIC) novel interaction model optimized for exploratory search and its implementation in the Discovery Hub application. 4-(CLIC) Several users’ evaluations of the proposed algorithms and of some elements of the Discovery Hub interface (CLIC) First, the state-of-the-art-review (3 mins 26)
- In order to answer these research questions we proposed the following contributions: 0- A state-of-the-art review of the semantic exploration and discovery systems 1- (CLIC) Several exploratory search algorithms optimized for semantic data and linked data in particular. 2- (CLIC) An efficient approach to execute these algorithm at query-time on remote linked data source. 3-(CLIC) novel interaction model optimized for exploratory search and its implementation in the Discovery Hub application. 4-(CLIC) Several users’ evaluations of the proposed algorithms and of some elements of the Discovery Hub interface (CLIC) First, the state-of-the-art-review (3 mins 26)
- We reviewed the semantic exploration and discovery systems in a broad sense within 3 areas of classification: - Browsers. - Recommenders. - And exploratory search systems (CLIC) Until today there are no popular good practices or strong guidelines to conceive such exploratory search systems. They are very heterogeneous in terms of design and interactions. (CLIC) There is notably a perceptible trade-off between intuitiveness and sophistication.
- We reviewed the semantic exploration and discovery systems in a broad sense within 3 areas of classification: - Browsers. - Recommenders. - And exploratory search systems (CLIC) Until today there are no popular good practices or strong guidelines to conceive such exploratory search systems. They are very heterogeneous in terms of design and interactions. (CLIC) There is notably a perceptible trade-off between intuitiveness and sophistication.
- We reviewed the semantic exploration and discovery systems in a broad sense within 3 areas of classification: - Browsers. - Recommenders. - And exploratory search systems (CLIC) Until today there are no popular good practices or strong guidelines to conceive such exploratory search systems. They are very heterogeneous in terms of design and interactions. (CLIC) There is notably a perceptible trade-off between intuitiveness and sophistication.
- The first important outcome of the state-of-the-art review is this matrix that offers a factual and synthetic view over the systems. It details the most advanced semantic exploration tools regarding a set of criteria related to information retrieval and human computer interaction aspects. This matrix constituted a very good basis to understand the evolution of the research in the field…
- Here is a timeline. During the first development phase of the semantic web (from 2001 to 2007) several types of browsing paradigms were investigated. Text-based browsers inspired by the classic web browsing experience appeared. Visual and faceted browsing approaches were also investigated. The small size and the relative homogeneity of the available datasets at the time were favorable to such approaches. (CLIC) In 2007 the Linked Open Data initiative renewed the research. The quality, the size and the coverage of generic datasets like Dbpedia enabled more sophisticated browsing paradigms. (CLIC) Linked data based recommenders appeared a bit later with the work of Alexandre Passant. The computation was domain-constrained at the beginning. Then cross-domain and lateral approaches were researched. In 2012 and 2013 the 3 major search engines also deployed their entity-recommendation solutions. It was the first deployment of semantic entity recommendation on mainstream services. (CLIC) Some of these recommenders constituted the basis of linked data based exploratory search systems. The research about semantically empowered exploratory search systems increased at the time.
- In this absence of solid evaluations it can be difficult to clearly state what is the advancement of the systems in the field. Our deep systems review allowed us to identify research opportunities both at the exploratory and at the semantic search level. (CLIC) For instance we observed that the results were often pre-stored in the systems. The users can only retrieve results that have been pre-computed. An opportunity is to compute the results at query-time. It can offer more flexibility to the users and allows to cover more exploratory search needs. (CLIC) We also identified that when the systems explain their results, they often only propose a single explanation. The users could benefit from a variety of explanations giving diverse perspectives and unveiling more elements of context. These opportunities constituted an inspération and a guidance for our research.
- In this absence of solid evaluations it can be difficult to clearly state what is the advancement of the systems in the field. Our deep systems review allowed us to identify research opportunities both at the exploratory and at the semantic search level. (CLIC) For instance we observed that the results were often pre-stored in the systems. The users can only retrieve results that have been pre-computed. An opportunity is to compute the results at query-time. It can offer more flexibility to the users and allows to cover more exploratory search needs. (CLIC) We also identified that when the systems explain their results, they often only propose a single explanation. The users could benefit from a variety of explanations giving diverse perspectives and unveiling more elements of context. These opportunities constituted an inspération and a guidance for our research.
- 7 mins 50 I will describe our first contribution now , the exploratory search algorithms
- The challenges We had to turn the linked data complexity into an opportunity by designing algorithms that rely on the graph richness to select relevant results to explore. Another challenge was to design advanced querying variants to support complex exploratory search needs.
- We chose to base our computation on spreading activation. It was chosen for several reasons: - It is a well-tried algorithm. - It is a connectionnist algorithm, it can ritrive results from minimal inputs - It was shown that it can be improved by semantics. - It is fast; some recent work proved that is can be executed as a distributed process
- More precisely what is the functioning of spreading activation? First we put an activation value on the resource of interest, the node Claude Monet for instance, and then this value is propagated iteratively to the neighbors. The activation values distributed to the neighbors depend on the implementation objective. A variety of weights and heuristics are generally used to influence the algorithm results. At the next iteration all the node being activated will propagate again their value, and so on. When a stop condition is reached (maximum number of iteration for instance), the propagation process stops and the most activated nodes constitute the results.
- More precisely what is the functioning of spreading activation? First we put an activation value on the resource of interest, the node Claude Monet for instance, and then this value is propagated iteratively to the neighbors. The activation values distributed to the neighbors depend on the implementation objective. A variety of weights and heuristics are generally used to influence the algorithm results. At the next iteration all the node being activated will propagate again their value, and so on. When a stop condition is reached (maximum number of iteration for instance), the propagation process stops and the most activated nodes constitute the results.
- We proposed our own semantic adaptation that aims to finely consider the graph semantics in order to improve the results . (CLIC) For this we introduced the semantic weighting function w(i,o) which has two objectives: (CLIC) -First, it filters the nodes eligible to activation. In other words, it concentrates the activation on relevant parts of the graph only. -Second, it favors the nodes that are semantically similar to the topic of interest (CLIC) I will describe in details these two aspects now
- First the filtering effect. The algorithm identifies the class-propagation domain which filters the nodes eligible to activation according to their types. (CLIC) The class propagation domain CPD is based on the idea that informative types are prevalent in the neighborhood of the activation origin. For instance Claude Monet is related to a lot of museums, so the type museum might be very informative when considering Monet. The CPD computation occurs in several steps: (CLIC) - First, the deepest type of each neighbors is identified (CLIC) - Second, their prevalence in the neighborhood is computed (CLIC) - Third, the least prevalent types are excluded from the CPD according to a minimum prevalence value
- First the filtering effect. The algorithm identifies the class-propagation domain which filters the nodes eligible to activation according to their types. (CLIC) The class propagation domain CPD is based on the idea that informative types are prevalent in the neighborhood of the activation origin. For instance Claude Monet is related to a lot of museums, so the type museum might be very informative when considering Monet. The CPD computation occurs in several steps: (CLIC) - First, the deepest type of each neighbors is identified (CLIC) - Second, their prevalence in the neighborhood is computed (CLIC) - Third, the least prevalent types are excluded from the CPD according to a minimum prevalence value
- First the filtering effect. The algorithm identifies the class-propagation domain which filters the nodes eligible to activation according to their types. (CLIC) The class propagation domain CPD is based on the idea that informative types are prevalent in the neighborhood of the activation origin. For instance Claude Monet is related to a lot of museums, so the type museum might be very informative when considering Monet. The CPD computation occurs in several steps: (CLIC) - First, the deepest type of each neighbors is identified (CLIC) - Second, their prevalence in the neighborhood is computed (CLIC) - Third, the least prevalent types are excluded from the CPD according to a minimum prevalence value
- First the filtering effect. The algorithm identifies the class-propagation domain which filters the nodes eligible to activation according to their types. (CLIC) The class propagation domain CPD is based on the idea that informative types are prevalent in the neighborhood of the activation origin. For instance Claude Monet is related to a lot of museums, so the type museum might be very informative when considering Monet. The CPD computation occurs in several steps: (CLIC) - First, the deepest type of each neighbors is identified (CLIC) - Second, their prevalence in the neighborhood is computed (CLIC) - Third, the least prevalent types are excluded from the CPD according to a minimum prevalence value
- So the propagation will spread only to the museum and to the artists instances. Consequently the mountain instance on the right won’t be activated It is important to notice that the class propagation domain is instance-specific. It can be significantly different for 2 painters for example
- So the propagation will spread only to the museum and to the artists instances. Consequently the mountain instance on the right won’t be activated It is important to notice that the class propagation domain is instance-specific. It can be significantly different for 2 painters for example
- The algorithm also favors the nodes that are similar to the activation origin using a triple-based similarity measure. Here Monet and this painter share 3 common characteristics. So the latter will receive a bonus of 3 during the propagation. The similarity feature is very simple because it has to be cheap enough to be computed on run-time between the origin and its neighbors. ….Thanks to these two semantic-based operations (filtering and similarity) our algorithm ritrive a mix of results that are very similar and related to the topics of interest.
- The algorithm also favors the nodes that are similar to the activation origin using a triple-based similarity measure. Here Monet and this painter share 3 common characteristics. So the latter will receive a bonus of 3 during the propagation. The similarity feature is very simple because it has to be cheap enough to be computed on run-time between the origin and its neighbors. ….Thanks to these two semantic-based operations (filtering and similarity) our algorithm ritrive a mix of results that are very similar and related to the topics of interest.
- Now polycentric queries. Polycentric queries refer to as queries implying more than one initial stimulation We propose to leverage the linked nature of the LOD to identify relevant knowledge at the crossroad of several interests For instance exploring results and make discoveries related both to The Beatles and to the film director Ken Lach, because they might be implicitly related together to other interesting artists (CLIC) Or between Ken Lach and Margaret Thatcher because Ken Loach is known for his political engagements.
- Now polycentric queries. Polycentric queries refer to as queries implying more than one initial stimulation We propose to leverage the linked nature of the LOD to identify relevant knowledge at the crossroad of several interests For instance exploring results and make discoveries related both to The Beatles and to the film director Ken Lach, because they might be implicitly related together to other interesting artists (CLIC) Or between Ken Lach and Margaret Thatcher because Ken Loach is known for his political engagements.
- In the case of polycentric queries the class-propagation domain is computed according to the neighborhoods of all the resources composing the query. (CLIC) For instance Movies, Office Holder, Political Party for Ken Loach and Margaret Thatcher. (CLIC) Bands, movies, music genre in the case of Ken Loach and The Beatles. Then the topics of interest are stimulated. (CLIC) The corresponding propagations evolve independently and only the nodes that are activated by the all these independent propagations constitute the polycentric results. The activation values of the nodes are divided by the logarithm of their degree in order to minimize the presence of highly connected and uninformative nodes such as countries for instance
- Our algorithms provide an automated results selection but they can also hide potentially interesting results for some queries. To mitigate this problem we proposed several variants which allow the exploration of topics through multiple perspectives. (CLIC) For this we formalized: - The criteria of interest specification variant - And the controlled randomness injection variant
- Our algorithms provide an automated results selection but they can also hide potentially interesting results for some queries. To mitigate this problem we proposed several variants which allow the exploration of topics through multiple perspectives. (CLIC) For this we formalized: - The criteria of interest specification variant - And the controlled randomness injection variant
- The criteria of interest specification modifies the similarity functionality (CLIC) of the basis algorithm by turning the similarity vectors into variables. For instance the users can selectively choose their criteria of interest (CLIC) through an interface implementing this algorithm. For example here the user specified that he is interested in Claude Monet because he was an impressionist but not because he was French.
- The criteria of interest specification modifies the similarity functionality (CLIC) of the basis algorithm by turning the similarity vectors into variables. For instance the users can selectively choose their criteria of interest (CLIC) through an interface implementing this algorithm. For example here the user specified that he is interested in Claude Monet because he was an impressionist but not because he was French.
- The goal of the randomness injection is to unveil surprising results. It can be particularly interesting for experts that want to discover peripheral knowledge about a topic. (CLIC) We experimented a formula where the nodes’ activation is randomized in proportion of a randomization value chosen by the users.
- The goal of the randomness injection is to unveil surprising results. It can be particularly interesting for experts that want to discover peripheral knowledge about a topic. (CLIC) We experimented a formula where the nodes’ activation is randomized in proportion of a randomization value chosen by the users.
- 16 mins 50 Second contribution: the execution of the algorithms on distant linked datasets
- We based our implementation on two paradigmatic design choices: - First the framework computes the result using distant linked dataset. - Second the framework computes the results at query-time A strong motivation is that this approach gives a very high flexibility in terms of data selection and querying. It allows to tune the algorithm to fit the user information need before to launch it on a targeted linked dataset.
- In order to achieve this computation in real-time from remote datasets we apply the algorithm only on a small and carefully selected subset of the targeted linked data graph. When the topic of interest is selected the framework send a local INSERT query containing a service operator to the targeted SPARQL endpoint in order to retrieve its neighborhood and to store it in a local Kgram triple store. The semantic spreading activation is applied only this extraction. Then at the next iteration the framework loads the neighborhoods of the most activated nodes and so on. A subgraph is incrementally imported in accordance with the activation procedure. For each query it is done until a triples limit is reached. This limit is extensively discussed in few slides.
- But first some information about the settings of the implementation. - The propagation spreads in both directions, because the property orientation is arbitrary and depends on a modeling choice. Relying on the existing literature we use the DBpedia categories to compute the similarity The main dataset we used is Dbpedia 3.7. It contains 270 million triples and 3.4 million resources
- The software architecture and the incremental import technique we propose confronted us with a triangular trade-off between the size of the import, the response-time and the results quality. Spreading activation is a connectionnist and iterative approach, it needs to process a sufficient amount of connections, during a sufficient number of iterations to produce a relevant result. Our objective was to make a valuable approximation by preserving the result quality while minimizing as much as possible the number of triples imported and the number of iterations performed per query.
- To lower the cost of our analyses we studied the behavior of the algorithm by using a representative selection of 100.000 queries. We computed this subset thanks to a random walker because according to the literature it is the best method to sample a large graph.
- The first parameter we studid was the average number of iterations needed for the algorithm to converge. For this we had to lock the other parameter, the number of triples processed. We set it to 10.000 because it is the most common triples limit the SPARQL endpoint allows to retrieve in one query. Nonetheless we can not replicate a very large part of a distant graph due to the transfer cost it implies We observed the convergence of the algorithm. It is visible here that after 6 iterations the top 100 result list is almost completely stable in term of composition. (CLIC) We also observed the stability of the ranks thanks to a Kendall Tau coefficient. The ranks are also almost stable after 6 iterations.
- The first parameter we studid was the average number of iterations needed for the algorithm to converge. For this we had to lock the other parameter, the number of triples processed. We set it to 10.000 because it is the most common triples limit the SPARQL endpoint allows to retrieve in one query. Nonetheless we can not replicate a very large part of a distant graph due to the transfer cost it implies We observed the convergence of the algorithm. It is visible here that after 6 iterations the top 100 result list is almost completely stable in term of composition. (CLIC) We also observed the stability of the ranks thanks to a Kendall Tau coefficient. The ranks are also almost stable after 6 iterations.
- In order to studi the amount of triples processed per query. We ran again the test-queries but this time we tested the influence of the import size. We launched the query with import size from 2.000 to 20.000 by increment of 2000 triples. We used6 iterations, according to our previous finding First result, we observe here that the response-time is linear according to the number of triples imported. (CLIC) Here you can observe the variation of the top hundred from one loading limit to another, we see that after 6.000 it start to linear. In other words it starts to be expensive to improve the results by processing more triples regarding the effect on the results. (CLIC) we can make the same observation for the rank variation thanks to the application of a Kendall-Tau. …Based on these analyses we use now the triples limit of 6.000 triples and 6 as the maximum number of iterations. These parameters are used in the Discovery Hub application
- In order to studi the amount of triples processed per query. We ran again the test-queries but this time we tested the influence of the import size. We launched the query with import size from 2.000 to 20.000 by increment of 2000 triples. We used6 iterations, according to our previous finding First result, we observe here that the response-time is linear according to the number of triples imported. (CLIC) Here you can observe the variation of the top hundred from one loading limit to another, we see that after 6.000 it start to linear. In other words it starts to be expensive to improve the results by processing more triples regarding the effect on the results. (CLIC) we can make the same observation for the rank variation thanks to the application of a Kendall-Tau. …Based on these analyses we use now the triples limit of 6.000 triples and 6 as the maximum number of iterations. These parameters are used in the Discovery Hub application
- Now, how do we apply the polycentric queries on a remote linked data source. The first operation is to identify a path between the resources combined (CLIC) For this we use SPARQL queries. (CLIC) At the beginning we perfom an undirected path query. If it fails we perform directed path queries in both senses. Since one or several paths are identified they are imported in the local Kgram triple store, and the propagation starts. Then the import is extended according to the activation values at the polycentric level (CLIC) We studied the polycentric algorithm and it also converges in 6 iterations, it is not a surprise as the polycentric formula is mainly based on the monocentric one.
- As mentioned in the manuscript we did not studied the cryteria variant, because it is very close to the monocentric algorithm. However you can observe here the results of 3 queries having different cryteria of interest specified. The first one is the basis one, no criteria are specified. The second favors the french categories but not the impressionnist one. The third one favors the non French impressionists. The American impressionist painters are particularly well represented in this list. All these results sets are related to Monet but constitute different perspectives, different ensembles. The randomized algorithm was not studid because it is divergent by nature and because we precisely want to disturb the algorithm behavior.
- A major interest of the proposed software architecture is the ability we have to switch from one data source to another. (CLIC) In the Dbpedia context we can use the local Dbpedia chapters, the german, the french, the italian ones for exemple. (CLIC) We compared the results of more than 700 hundred queries of the Discovery Hub query-log that were described in the 5 biggest Dbpedia chapters. This experiment showed that the results for equivalent queries obtained using these chapters were very different from the ones we obtained when using the English one. In other words the DBpedia chapters constitute cultural prisms on resources. This aspect can be leveraged in the applications. (CLIC)
- A major interest of the proposed software architecture is the ability we have to switch from one data source to another. (CLIC) In the Dbpedia context we can use the local Dbpedia chapters, the german, the french, the italian ones for exemple. (CLIC) We compared the results of more than 700 hundred queries of the Discovery Hub query-log that were described in the 5 biggest Dbpedia chapters. This experiment showed that the results for equivalent queries obtained using these chapters were very different from the ones we obtained when using the English one. In other words the DBpedia chapters constitute cultural prisms on resources. This aspect can be leveraged in the applications. (CLIC)
- A major interest of the proposed software architecture is the ability we have to switch from one data source to another. (CLIC) In the Dbpedia context we can use the local Dbpedia chapters, the german, the french, the italian ones for exemple. (CLIC) We compared the results of more than 700 hundred queries of the Discovery Hub query-log that were described in the 5 biggest Dbpedia chapters. This experiment showed that the results for equivalent queries obtained using these chapters were very different from the ones we obtained when using the English one. In other words the DBpedia chapters constitute cultural prisms on resources. This aspect can be leveraged in the applications. (CLIC)
- The last analysis we did was to apply the monocentric algorithm on graphs randomly generated. We wanted to discover what were the graph characteristics impacting the algorithm behavior. The objective was to discuss the applicability of the algorithm outside the Dbpedia context So we generated random graphs by making varying some charactestics like the degree or the diameter. We fixed the boundary of our analysis by observing the metrics of the KONECT network collections. It informed us on the diameters or the average degree of real-world graphs for instance. (CLIC) As we suspected, the main finding of these analyses is that the graph diameter is responsible for the convergence speed. It explains why the algorithm converge in approximately 6 iterations on Dbpedia, because Dbpedia has a diameter of 6.
- The last analysis we did was to apply the monocentric algorithm on graphs randomly generated. We wanted to discover what were the graph characteristics impacting the algorithm behavior. The objective was to discuss the applicability of the algorithm outside the Dbpedia context So we generated random graphs by making varying some charactestics like the degree or the diameter. We fixed the boundary of our analysis by observing the metrics of the KONECT network collections. It informed us on the diameters or the average degree of real-world graphs for instance. (CLIC) As we suspected, the main finding of these analyses is that the graph diameter is responsible for the convergence speed. It explains why the algorithm converge in approximately 6 iterations on Dbpedia, because Dbpedia has a diameter of 6.
- 27 mins 10 Third contribution: the Discovery Hub application
- The human-computer interactions quality is critical for the exploratory search systems. Our challenge was to build an intuitive and supportive interface to explore the algorithm results For this we developed the Discovery Hub web application
- The interface was built by Damien Legrand during two internships. (CLIC) To build the application we relied on the experience we gained with a first version, that constituted a very useful draft We used the opportunities we identified from the litterature We received the help of human computer interaction researchers We benefited from the users feedbacks obtained during several evaluations that I will present later -We spent also times to design the specifications thanks to a functional modeling process
- The interface was built by Damien Legrand during two internships. (CLIC) To build the application we relied on the experience we gained with a first version, that constituted a very useful draft We used the opportunities we identified from the litterature We received the help of human computer interaction researchers We benefited from the users feedbacks obtained during several evaluations that I will present later -We spent also times to design the specifications thanks to a functional modeling process
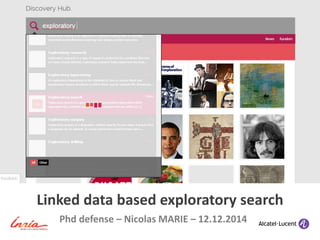
- I will present you the application now thanks to a screencast (CLIC) Discovery Hub is online and stable now. During the first users’ connection we display a small tutorial that explains the objective of the application and how to use it. Some explanations are also permanently displayed on the homepage The large search bar on top constitute the applicaion call-to-action « start your exploration here ». It use the Dbpedia lookup API to propose rapid entity selection. In this case the user will compose criteria specficied query. He indicates that alumni of the Beaux Art school and French painters are interesting facets of Monet The results are shown in a very visual display and the pictures serve as previews. They inform on the results nature. The result list page offers vertival and horizontal scrolling, it consequently display several hundred results. The results are organized by their CPD types, and these CPD types are leveraged to support faceted browsing The single results are presented in the form of pop-ups, that allows to switch easily from the lists to a single result and inversely. They propose structured data about the entity, that can be used to browse the Dbpedia space… in a classic semantic browsing manner. Type-specific third party content are proposed... As well as memory features that allow to save results of interest in the user profile. The popup also allow the users to pivot during search by using the « run an exploration » button. This is very useful during exploratory search because it supports an orienteering behavior. Three explanations are implemented in Discovery Hub, the first one shows the common characteristics of the resources, the second identifies the cross-references in their respective Wikipedia pages, the third is in a form of a graph, more complex to understand but it unveils elements of context. It can be particularly helpful in the case of polycentric queries where it helps to understand the complex connections between a set of resources. We will see it in action now for explaining a composite query. This screencast ends by showing an example of polycentric query.
- As mentioned before the experience we gained with the first Discovery Hub version helped us a lot to build the actual version of the application. (CLIC) Some examples of improvement include the tutorial on the homepage that did not exist in the first version. (CLIC) And the unification of the multiple search bars we had in the first version in a unique one and very visible one.
- As mentioned before the experience we gained with the first Discovery Hub version helped us a lot to build the actual version of the application. (CLIC) Some examples of improvement include the tutorial on the homepage that did not exist in the first version. (CLIC) And the unification of the multiple search bars we had in the first version in a unique one and very visible one.
- There is currently a new evaluation protocol that is experimented by Emilie Paladji and Alain Giboin. It is based on a fine modeling and analysis of the users exploratory search behavior. So it will also help to improve again the interface by obtaining a better understanding of their exploration strategies and their needs
- 32 mins 35 Fourth contribution: the results evaluation
- Evaluating exploratory search is difficult because it is a high-level activity that cannot be reduced to easily measurable tasks. There is no commonly admitted best practices to design the evaluation protocols. Discovery Hub implement multiple algorithms. Our evaluations were focused on the users’ perception about the algorithm results (Three distinct evaluations covered the monocentric, polycentric and advanced algorithm variants.)
- We evaluated first the mono-centric algorithm. We compared our spreading activation results against the semantic vector space model algorithm implemented in the MORE Dbpedia movies recommender. (CLIC) We used the Limesurvey application to build a neutral interface and to execute the test, because the Discovery Hub interface did not exist at the time. (CLIC) 5 movies were randomly selected in the “50 films to see before you die” list to serve as cases, these ones We generated the top 20 movie’ results using the 2 algorithms and we randomized them in 5 single lists for the evaluation. (43)
- We tested 3 hypotheses: - Our Monocentric Spreading Activation Algorithm MSSA algorithm gives results at least as relevant as the sVSM one - The SSA algorithm has less degradation than the sVSM one. - There is a greater chance that the results are less relevant but newer to users at the end of the lists. 15 participants rated the results according to their similarity and their novelty thanks to the following questions: - With the film A, I think I will live a similar cinematographic experience as with the film B ? - You and A ? Seen, Known but not seen, Not known, to evaluate its novelty to the user
- We obtained 4.000 ratings that allowed us to verifiy our hypotheses. (CLIC) To verify the hypothesis 1 we observed the difference between the 2 algorithms overall relevance scores. The relevance score is better for SSA, this hypothesis is verified. (CLIC) To verify the hypothesis 2, we observed the difference between the 2 algorithms relevance scores at the end of the result list from the rank 11 to 20. Again the relevance score is better for our algorithm, this hypothesis is also verified. (CLIC) To verify the hypothesis 3, we compared both the relevance and the discovery scores of the 2 two algorithms at the beginning and at the end of the results lists. The results are perceived less relevant in the second half of the list but have a higher discovery score. This hypothesis is verified.
- We obtained 4.000 ratings that allowed us to verifiy our hypotheses. (CLIC) To verify the hypothesis 1 we observed the difference between the 2 algorithms overall relevance scores. The relevance score is better for SSA, this hypothesis is verified. (CLIC) To verify the hypothesis 2, we observed the difference between the 2 algorithms relevance scores at the end of the result list from the rank 11 to 20. Again the relevance score is better for our algorithm, this hypothesis is also verified. (CLIC) To verify the hypothesis 3, we compared both the relevance and the discovery scores of the 2 two algorithms at the beginning and at the end of the results lists. The results are perceived less relevant in the second half of the list but have a higher discovery score. This hypothesis is verified.
- We obtained 4.000 ratings that allowed us to verifiy our hypotheses. (CLIC) To verify the hypothesis 1 we observed the difference between the 2 algorithms overall relevance scores. The relevance score is better for SSA, this hypothesis is verified. (CLIC) To verify the hypothesis 2, we observed the difference between the 2 algorithms relevance scores at the end of the result list from the rank 11 to 20. Again the relevance score is better for our algorithm, this hypothesis is also verified. (CLIC) To verify the hypothesis 3, we compared both the relevance and the discovery scores of the 2 two algorithms at the beginning and at the end of the results lists. The results are perceived less relevant in the second half of the list but have a higher discovery score. This hypothesis is verified.
- We obtained 4.000 ratings that allowed us to verifiy our hypotheses. (CLIC) To verify the hypothesis 1 we observed the difference between the 2 algorithms overall relevance scores. The relevance score is better for SSA, this hypothesis is verified. (CLIC) To verify the hypothesis 2, we observed the difference between the 2 algorithms relevance scores at the end of the result list from the rank 11 to 20. Again the relevance score is better for our algorithm, this hypothesis is also verified. (CLIC) To verify the hypothesis 3, we compared both the relevance and the discovery scores of the 2 two algorithms at the beginning and at the end of the results lists. The results are perceived less relevant in the second half of the list but have a higher discovery score. This hypothesis is verified.
- When the Discovery Hub interface was developed we evaluated the influence of the explanation functionalities over the users’ judgment. For this we asked to the participants to evaluate again 20 results using the explanation functionalities. These 20 results were selected randomly among the movies that were poorly evaluated during the first round. As you can see the relevance score was significantly better when the users received the help of the explanations, consequently this hypothesis is verified.
- Now the evaluation of the polycentric algorithm. We asked to 12 participants to rate the top 10 results of 2 composite queries that were generated thanks to their Facebook likes. By using such Facebook likes we wanted to simulate real composite queries. We matched the likes with Dbpedia resources thanks to a small script. (CLIC COMP) For each participant we generated 2 random combinations. We tested the following hypotheses: - (CLIC) Hypothesis 5, the composite-query results are interesting to the users - (CLIC) Hypothesis 6, a consequent proportion of the results are unexpected; so they favor discoveries (ONE CLIC) For this we asked 2 questions for each result: one covering the interestingness and one covering the unexpectedness.
- The results: - 61% of queries received a relevance score over the mean. - (CLIC) 65% of the results were rated unexpected…and (CLIC) 35% of the results were rated unexpected and relevant at the same time. (CLIC) So the hypothesis 5 and 6 are verified.
- During these two evaluations (monocentric and polycentric) we also asked the participants to give their opinion about the helpfulness of the explanation features. The explanations are evaluated differently according to the type of query considered, mono-centric or polycentric ones. It shows the importance of implementing several types of explanations. (CLIC) For instance the graph-based explanation received a very large approval from the users for understanding the polycentric queries results because it helps to understand complex relations between multiple resources.
- The last evaluation concerned the advanced querying modes. In this case we compared the results for 4 algorithm variants: - The basis algorithm - The criteria specification variant, - The half randomized and the fully randomized algorithm First the 16 participants selected their 4 favorite topics in a list of 20 random Discovery Hub queries. We kept the 2 most frequently cited topics: information visualization and the singer Serge Gainsbourg. We also asked the participants to specify their criteria of interestin order to generate the criteria specification results. The top 10 results for each algorithm variant were generated and they were randomized in a single list per user.
- We tested 4 hypotheses: - The users who specify their criteria of interest find the results of the search more relevant - The users who specify their criteria of interest do not find the results less novel - The stronger is the level of randomness the more surprising the results are for the users. - Even if the level of surprise is high, the majority of the top results are still relevant to the users. (CLIC) For each of the results 4 Likert questions were asked to the users: - Is the result in itself is surprising? - Is the relation between the result and the query is surprising? - Is the result interesting? - Is the result too distant from the topic searched?
- We tested 4 hypotheses: - The users who specify their criteria of interest find the results of the search more relevant - The users who specify their criteria of interest do not find the results less novel - The stronger is the level of randomness the more surprising the results are for the users. - Even if the level of surprise is high, the majority of the top results are still relevant to the users. (CLIC) For each of the results 4 Likert questions were asked to the users: - Is the result in itself is surprising? - Is the relation between the result and the query is surprising? - Is the result interesting? - Is the result too distant from the topic searched?
- 41 mins 35 I will conclude now
- I will start by giving a quick summary of our contributions (CLIC) To answer the first research question (ATTENTION CLIC) we proposed the formalization of a core semantic spreading activation algorithm and several variants offering multi-perspective exploration capabilities.
- I will start by giving a quick summary of our contributions (CLIC) To answer the first research question (ATTENTION CLIC) we proposed the formalization of a core semantic spreading activation algorithm and several variants offering multi-perspective exploration capabilities.
- To answer the second research question (ATTENTION CLIC) we executed the algorithm at query-time on distant linked dataset by coupling the spreading activation procedure to a remote linked data importation technique (CLIC - CLIC)
- To answer the third research question (CLIC) we designed the Discovery Hub web application, which offer a rich variety of functionalities in a modern interface. (CLIC – CLIC)
- To answer the fourth research question (CLIC) we designed and executed three new evaluation protocols that relied exclusively on users’ judgment.
- We also identified several short-term and long-term perspectives. First the short-term improvements. - Set-levels interactions: the idea is to propose visualization or actions based on set of resources like facets and collections: for instance generating a playlist from a music collections - Collaborative exploratory search: it is particularly interesting to gather the points of view and expertise of several exploratory searchers to achieve a deeper exploration on a topic - Post-query re-ranking mechanisms: it refers to be able to re-rank the results once they are retrieved, for instance augment the importance of a similarity cryteria. New query-means: the idea is to trigger Discovery Hub from other inputs than entity lookups, such as check-in or music identification application to offer frictionless exploration capabilities
- Now the long term improvements, that necessitate more research: Negative search: the idea behind negative search is to exclude elements or pattern of knowledge during the processing, for instance ritrive results that are related to Monet but not to another painter Adaptive queries recommendation: it is about creating a system of query recommendations to help the users to explore topics from a various relevant perspective that are automatically identified Collection-based knowledge creation: the collections can be turned into active information assets to generate massive polycentric queries, but it need a specific algorithm to be fast enough On-the-fly distributed data selection: the idea is to dynamically select and combine the best data available in the whole LOD cloud to better satisfy exploratory search needs, it is a difficult research questions Massive use and commercial success concerns the research but also the market, it refers to the emergence of popular and widely-used applications
- This thesis was executed under an industrial contract so I also participated in various initiatives related to the industrial and entrepreneurship technology ecosystem. It includes a startup challenge (that we won by proposing a commercial adaptation of Discovery Hub), the opening ceremony of the French DBpedia chapter, the Bell Labs Open days and the INRIA-Industry meeting.
- This thesis was executed under an industrial contract so I also participated in various initiatives related to the industrial and entrepreneurship technology ecosystem. It includes a startup challenge (that we won by proposing a commercial adaptation of Discovery Hub), the opening ceremony of the French DBpedia chapter, the Bell Labs Open days and the INRIA-Industry meeting.
- This thesis was executed under an industrial contract so I also participated in various initiatives related to the industrial and entrepreneurship technology ecosystem. It includes a startup challenge (that we won by proposing a commercial adaptation of Discovery Hub), the opening ceremony of the French DBpedia chapter, the Bell Labs Open days and the INRIA-Industry meeting.
- This thesis was executed under an industrial contract so I also participated in various initiatives related to the industrial and entrepreneurship technology ecosystem. It includes a startup challenge (that we won by proposing a commercial adaptation of Discovery Hub), the opening ceremony of the French DBpedia chapter, the Bell Labs Open days and the INRIA-Industry meeting.
- Finally, the research work about Discovery Hub resulted in 6 publications in international conferences having a partial or complete focus on semantic web research. It notably includes long papers at SEMANTICS, I-Semantics and Hypertext 2013. Discovery Hub also won a best demonstration award at ESWC2013. During the period of this thesis I also participated to 7 other publications in the fields of social network and web sciences That concludes the presentation; I will be pleased to answer your questions. Thank you for your attention
- Graph RDF Guy => each triple represents an arc, everything is transformed into an arc, even the resources are transformed in triples, personally I only know the semantics of the vocabulary RDF, so it is difficult to answer with an higher level of abstraction Randomness Guy & Harald, the randomness was experimental. We learnt that there is a better trade off between relevance and surprise with a randomization level of 0.5. We might explore more clever randomization procedure like similarity and CPD, possible to quantify the influence by comparing to the basis algorithm. But need to evaluate with users also, so expensive => Randomness convergence: No pb: De plus ajouter de l’aléatoire rend les résultats non déterministes, ce qui permet à l’utilisateur de rejouer la requête plusieurs fois pour découvrir de nouvelles connaissances, utile pour les experts tau_b can be usefully approximated by a normal distribution ? No because we did not have a sufficient amount of data for this. Relied on the expertise of Florentin Rodio, which was a specialist, it was a tool that perfectly allowed us to observe the algorithm behavior Guy variance => average degree, edge density and edge variance density=graphSize2/(numberOfNodes*(numberOfNodes-1)); Page 199, you mention extending spreading activation to keyword search is a tedious problem. Can you develop you ridea on this? What (difficult) issues does it raise? => La difficulté principale concerne l’identification des « seeds » nœuds stimulés à partir des mots clés exprimés par l’utilisateur VS direct mapping with lookup. ce problème a déjà été traité avec succès dans la littérature (par Daniel Schwabe entre autre): A hybrid approach for searching in the semantic web, they use the amount of results retrieved by classic search engines to determine the amount of activation for each term that can be matched to a node of the graph used to performed the spreading activation Harald consideration other strategies, +++++
- Analyse random graph guy: « At first sight, this looks suspicious, as we would expect the semantic to be anything but random.” “This however is a dangerous path to follow since graphs in KONECT show quite a variety of different features. Some are ordinary non-directed simple graphs, some are bipartite, some are directed, some are acyclic directed graphs, etc. “ Justement je dis bien qu’on ne teste la sémantique, que ce sont des considérations d’ordre structurelles. Pour moi c’est totalement cohérent de faire varier les caractéristiques de graphes random pour observer comment se comporte l’algo. Je me suis servi des métriques des graphes KONECT (qui constituent une des plus grandes collection en la matière) pour justifier certaines bornes de mon analyse, montrer que l’on couvrait des plages de degrés, diamètres, etc. qui sont réalistes car correspondant à celle de la majorité des graphes « naturels »,
- Harald relation between facets: so in Dbpedia the categories are linked according to the relations broader and narrower. So there are several possibilities: Include all the sub-categories, but we have to check that it can be done on run-time. Utilizing the super-categories is not a good idea, see the paper (p 142 thesis) Another possibility is to run a similarity computation, using the depth of categories on the whole category hierachy but it breaks our « run-time » requirement
- The objective was to choose the simplest but still efficient way to compute a similarity measure. The Dbpedia categories were chosen because it has been shown in the literature that it has a very positive influence on the similarity measure computation. Almost 100% of the resources have categories attached. Another interesting point is that some categories gather resources of several types so it is positive for cross-recommendation. More complex similarity measure can hardly be computed on run-time. For ex. Passant / Mirizzi.
- The second important point to take into consideration is that similarity and relatedness strongly overlap when considering linked data graphs. So some knowledge that is not processed when computing the similarity measure might be used in a structural way by the spreading activation algorithm. It can be considered as a compensation of the simplicity of the similarity measure.
- Argument for using several local DBpedia chapters but only the English chapter is used. It is very different to use the local chapter independently than to mix several chapters at the same time due to the connectionist nature of the algorithm. The functionality is not available today but on the first version it was possible to query a chosen Dbpedia language. If we mix several linked data source at the same time we have to check that there is no distortion in the algorithm behavior. Our algorithm will tend to favor the sources that has the best semantic coverage. Or to favor the less connected graph because we divide the activation values by the digri (fan out effect). So it merge several linked data graph we do not know how the algorithm will behave and if it favors a data source or not. I also did experimental analysis, and behavior was the same but it converged more quickly. I removed this from the thesis manuscript because at the end I thought that it was too immature to be included. It is in the perspective linked data based dynamic selection. Sophisticated balancing strategies need to be researched.
- In Table 8.2, perhaps there a correlation between the queried categories and the total number of instances in these categories (are there just more instances for more common queries anyway?). Not only due to prevalence: Several rare categories of cultural items are very popular e.g. Ivor_Novello_Award_winners.
- I am not sure is Hypothesis 10 useful in itself (it seems obvious), and perhaps it should have been combined with Hypothesis 11 (but this was not validated). Hypothesis 10: The stronger is the level of randomness the more surprising the results are for the users. Hypothesis 11: Even if the level of surprise is high, the majority of the top results are still relevant to the users. Ce point avait déjà été constaté et nous avions ajouté la notion d’intersection entre les résultats pertinents et surprenant, voir « The intersection of the results both evaluated as very interesting and very surprising is also in favor of the 0.5 randomness value. Indeed, their percentage reaches only 3.3% for the randomness value of 1 versus 7.5% for the 0.5 value and approximately 4.5% for the other algorithms. Lower levels of randomness should be used to obtain a better trade-off between relevance and surprise p.217.” A reformuler sous une hypothèse basée sur ce trade-off ? Plus difficile à formuler
- As well as improvements, it would be interesting to hear the candidate’s perspective on application to other related areas beyond exploratory search (if there is potential here, e.g. recommendation, etc.). Je vais le faire, d’autant plus que j’ai des idées intéressantes suite aux entretiens que j’ai déjà efectué To my opinion there is a significant difference as recommenders might optimize the precision and ESS the recall (orienteering) because recommenders = minimal interactions should show the brest results first. However it can be interesting to use the algorithm as a basis notably to retrive diverse results (e.g. 1 top results of each class). It can also be interesting to use the composite queries, I know that Benjamin Heitmann did it. Sépage / Seevl: commercial applications