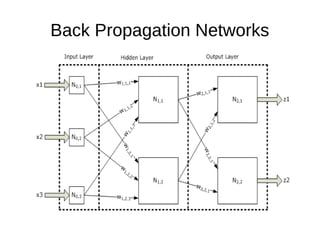
2. Note that:
1. The output of a neuron in a layer goes to all
neurons in the following layer.
2. Each neuron has its own input weights.
3. The weights for the input layer are assumed
to be 1 for each input. In other words, input values
are not changed.
4. The output of the NN is reached by applying
input values to the input layer, passing the output
of each neuron to the following layer as input.
5. The Back Propagation NN must have at least
an input layer and an output layer. It could have
zero or more hidden layers.
25. Practical considerations in implementing the
BP Algorithm
Pattern or Batch mode training: In pattern mode,
present a single pattern, compute error gradient,
then change the network wights accordingly. In
batch mode, collect the values of error gradients,
over an entire epoch, the change the weights
according to the single resultant gradient vector.
Pattern mode training is easier to
implement. In this mode, input patterns are
shuffled from one epoch to the next, thereby
avoid oscillation in weight values and also
improves the speed of convergence of algorithm.
These two modes are equivalent if the learning
rate is kept small.
26.
When to stop training: various criteria-
When absolute value of squared error
averaged over one epoch, falls below pre-
defined threshold value.
By computing the absolute rate of change of
the mean squared error per epoch.
By checking the value of error gradient, as it
shrinks toward zero, wen one approaches a
local or global minimum.
By checking the generalization ability of the
network.
Use a bipolar signal function. It can cause a
significant speed up in the network convergence.
27.
Weight initialization: From some small random
values within some interval [-Є, Є].
same values for all weights may lead to
'network paralysis', where the network learns
nothing.
Very small range may lead to slow learning
in the initial stages.
Incorrect choice of weights may lead to
'network saturation' where weight changes are
negligible over consecutive epochs.
28.
Adjust learning rate: small value of learning rate
-> convergence guaranteed -> but long training
time
Selection of network architecture (no. of layers
and no. of neurons per hidden layers): affects
generalization and approximation ability of the
network.
Network with single hidden layer can
approximate any continuous function, but more
hidden layers are required for higher accuracy.
The no. of nodes should be large enough to
form a decision region as complex as required by
the problem.