Lecture 3 RE NFA DFA
•
8 likes•4,409 views

This document discusses lexical analysis in compilers. It begins with an outline of the topics to be covered, including lexical analysis, regular expressions, finite state automata, and the process of converting regular expressions to deterministic finite automata (DFAs). It then provides more details on each phase of a compiler and the role of lexical analysis. Key aspects of lexical analysis like tokenizing source code and classifying tokens are explained. The document also covers implementation of regular expressions using non-deterministic finite automata (NFAs) and their conversion to equivalent DFAs using techniques like epsilon-closure and transition tables.

Recommended
More Related Content
What's hot
What's hot (20)
Similar to Lecture 3 RE NFA DFA
Similar to Lecture 3 RE NFA DFA (20)
Recently uploaded
Recently uploaded (20)
Lecture 3 RE NFA DFA
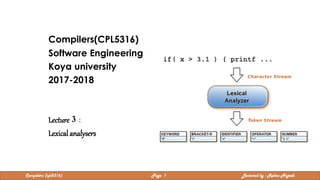
- 1. Compilers(CPL5316) Software Engineering Koya university 2017-2018 Lecture 3 : Lexical analysers Compilers (cpl5316) Page 1 Lectured by : Rebaz Najeeb
- 2. Outline Lexical analysis Implementation of Regular Expression RE NFA DFA Tables Non-deterministic Finite Automata (NFA) Converting a RE to NFA Deterministic Finite Automata ( DFA) Converting NFA to DFA Converting RE to DFA directly Compilers (cpl5316) Page 2 Lectured by : Rebaz Najeeb
- 3. Compiler phases 1. Lexical analysis 2. Parsing 3. Semantic analysis 4. Optimization 5. Code Generation Compilers (cpl5316) Page 3 Lectured by : Rebaz Najeeb Source code Target code
- 4. Lexical analysis Compilers (cpl5316) Page 4 Lectured by : Rebaz Najeeb Lexical analysis: reads the input characters of the source program as taken from preprocessors , and group them into lexemes, and produce as output a sequence of tokens for each lexeme in the source program. Roles of lexical analyzer Breaks source program into small lexical units , and produces tokens Remove white space and comments If there is any invalid token, it generates an error
- 5. Dividing source code Human format Lexical analyzer format • Divide the program into lexical units Compilers (cpl5316) Page 5 Lectured by : Rebaz Najeeb if (i==3) X=0; else X=1; tif (i==3)nttX=0;ntelsenttX=1; tif (i==3)nttX=0;ntelsenttX=1;
- 6. Grouping (classifying)lexemes • In English • Verb , Noun, Adj, Adv. • In Programming language • Keywords, Identifier, operators, assignment, semicolon • Token = <token name , attribute value> • Example of creating class token int a = 3; <keyword, int> <identifier, a> <assignment,=> <constant, 3> <symbol,;> Token class Compilers (cpl5316) Page 6 Lectured by : Rebaz Najeeb
- 7. Token classes • Token classes correspond to set of strings, such as followings • Identifiers : String of letters or digits start with letters • Identifier = (letter)(letter | digit)* • Integers : non-empty digit of strings. • integers= (sign)?(digit)+ • Keywords : fixed set of reserved words • Else , if , for , while , do. • Whitespace : blanks, newlines, tabs Compilers (cpl5316) Page 7 Lectured by : Rebaz Najeeb
- 8. Lexical analyzer Compilers (cpl5316) Page 8 Lectured by : Rebaz Najeeb a= 3; <id,a> <op,=> <int,3> <symb,;> <Class, String> tif (i==3)nttX=0;ntelsenttX=1;
- 9. Regular expression letter = [a – z] or [A – Z] digit = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 or [0-9] sign = [ + | - ] Decimal = (sign)?(digit)+ Identifier = (letter)(letter | digit)* Float = (sign)? (digit)+ (.digit)* Odd number ? Alphabets {0,1} Email ? Website URL? Compilers (cpl5316) Page 10 Lectured by : Rebaz Najeeb
- 10. Observation • Many regular expressions can have exactly the same meaning • 0* == 0+ 0* == ɛ + 0* • Meaning function is many-to-one • 0 1 2 3 4 5 • 0 1 10 11 100 101 • I II III IV V Compilers (cpl5316) Page 11 Lectured by : Rebaz Najeeb Syntax Semantic optimization Ambiguity
- 11. Finite state automata (FSA) ⌐ There are two main kinds of finite state automata: i. NFAs (Non-Deterministic Finite Automata): at a particular state , a unique path may not be determined for each input alphabet. ii. DFAs (Deterministic Finite Automata) : at a particular state , a unique path determined for each input alphabet. ⌐ For every nondeterministic automata, there is an equivalent deterministic automata. Computations && Compilers (CS33) # 11 Lectured by : Rebaz NajeebComputations && Compilers (CS33) # 11 Lectured by : Rebaz Najeeb q0 q1 q2 q3 q4 a b c a e e c – The above NFA is equivalent to the regular expression /ab*ca?/.
- 12. NFAs (Non-Deterministic Finite Automata) ⌐ In a nondeterministic finite automaton (NFA), for each state there can be zero, one, two, or more transitions corresponding to a particular symbol. ⌐ Only NFA state automaton can have an e transition. ⌐ the procedure is like: RE NFA DFA Tables Computations && Compilers (CS33) # 12 Lectured by : Rebaz Najeeb
- 13. Implementation of RE Compilers (cpl5316) Page 12 Lectured by : Rebaz Najeeb
- 14. RE to NFA using Thomson’s Construction Compilers (cpl5316) Page 13 Lectured by : Rebaz Najeeb a b a: b: (a | b) a b e e e e e e e e a b e e e (a|b) * e e e e e e a b e e e a(a|b) *a (a|b)* a
- 15. NFA example 1 ∑={a,b} Computations && Compilers (CS33) # 15 Lectured by : Rebaz Najeeb S0 S1 S2 S3
- 16. NFA example 2 ⌐ ∑={0,1} , Construct DFA to accept 00(0+1)* Computations && Compilers (CS33) # 16 Lectured by : Rebaz Najeeb p 0 0 0 1 s q s p q 0 0 1 Ǿ 1 0,1 0, 1 NFA DFA
- 17. Converting NFA to DFA Computations && Compilers (CS33) # 17 Lectured by : Rebaz Najeeb e e e e a b e e a0 1 3 5 2 4 7 86 e S0 = e-closure({0}) = {0,1,2,4,7} S0 into DS as an unmarked state mark S0 e-closure(move(S0,a)) = e-closure({3,8}) = {1,2,3,4,6,7,8} = S1 S1 into DS e-closure(move(S0,b)) = e-closure({5}) = {1,2,4,5,6,7} = S2 S2 into DS transfunc[S0,a] S1 transfunc[S0,b] S2 mark S1 e-closure(move(S1,a)) = e-closure({3,8}) = {1,2,3,4,6,7,8} = S1 e-closure(move(S1,b)) = e-closure({5}) = {1,2,4,5,6,7} = S2 transfunc[S1,a] S1 transfunc[S1,b] S2 mark S2 e-closure(move(S2,a)) = e-closure({3,8}) = {1,2,3,4,6,7,8} = S1 e-closure(move(S2,b)) = e-closure({5}) = {1,2,4,5,6,7} = S2 transfunc[S2,a] S1 transfunc[S2,b] S2 1- Creating start state with e-closure({0} 2- Move start state with input alphabets Then find e-closure({new set } 3- Repeat the procedure until there will be No more moves with input alphabets
- 18. Converting NFA to DFA Computations && Compilers (CS33) # 18 Lectured by : Rebaz Najeeb b a a b b 3 a 2 1
- 19. Converting NFA to DFA using table Computations && Compilers (CS33) # 19 Lectured by : Rebaz Najeeb
- 20. NFA to DFA with table ⌐ ∑={a,b} , L=any String starts with a 1- Generate NFA. 2- Convert NFA to DFA using table. What if L=any string ends with a ? Computations && Compilers (CS33) # 20 Lectured by : Rebaz Najeeb
- 21. RE to DFA directly steps Compilers (cpl5316) Page 17 Lectured by : Rebaz Najeeb Create augmented RegEx and number the alphabets Create annotated syntax tree and Label the tree Find firstPos and Lastpos Then followPos Derive DFA from followPos Table 1- 2- 3- 4-
- 22. RE to DFA directly We may convert a regular expression into a DFA (without creating a NFA first). 1. First we augment the given regular expression by concatenating it with a special symbol #. r → (r)# augmented regular expression 2. Then, construct a syntax tree from the augmented regular expression (r)# 3. Leaves in a syntax tree are labeled by an alphabet symbols (plus # ) or by the empty string, and inner nodes will be the operators in the augmented regular expression. 4. Then each alphabet symbol (plus #) will be numbered (position numbers). 5. Finally, compute four functions: nullable, firstpos, lastpos and followpos. Compilers (cpl5316) Page 17 Lectured by : Rebaz Najeeb
- 23. Building syntax tree • Example (a|b)*abb Compilers (cpl5316) Page 18 Lectured by : Rebaz Najeeb (a|b)*abb# a b 21 * a 3 b 4 b 5 # 6 position number (for leafs) Concatenation Or Cat-nodes Closure Or Star Alternation Or Union augmented regular expression 1 2 3 4 5 6 Step 1 Step 2
- 24. Functions • There are four functions have to be computed from syntax tree 1. Nullable(n): is true for a syntax tree node n if the subexpression represented by n has ԑ in its languages. 2. Firstpos(n): is the set of the positions in the subtree that correspond to the first symbols of strings generated by the sub-expression rooted by n. 3. Lastpos(n): is the set of the positions in the subtree that correspond to the last symbols of strings generated by the sub-expression rooted by n. 4. Followpos(i): is the set of positions that can follow the position i in the tree in the strings generated by the augmented regular expression. Compilers (cpl5316) Page 19 Lectured by : Rebaz Najeeb
- 25. Computing (Nullable, Firstpos, Lastpos) Compilers (cpl5316) Page 21 Lectured by : Rebaz Najeeb
- 26. Example of the functions ҂ (a|b)* a ҂ nullable(n)=false ҂ firstpos(n)={1,2,3} ҂ lastpos(n)={3} ҂ followpos(1)={1,2,3} Compilers (cpl5316) Page 20 Lectured by : Rebaz Najeeb n 1 2 3
- 27. Annotated syntax tree Compilers (cpl5316) Page 22 Lectured by : Rebaz Najeeb {6}{1, 2, 3} {5}{1, 2, 3} {4}{1, 2, 3} {3}{1, 2, 3} {1, 2}{1, 2} * {1, 2}{1, 2} | {1}{1} a {2}{2} b {3}{3} a {4}{4} b {5}{5} b {6}{6} # nullable firstpos lastpos 1 2 3 4 5 6 (a|b)*abb# 1 2 3 4 5 6 Step 3 - A
- 28. Finding FollowPos Followpos can be computed as following • (rule 1) if n is a cat-node c1 c2 for every position i in lastpos(c1), then all positions in firstpos(c2) are in followpos(i) • (rule 2) if n is a star-node if i is a position in lastpos(n), then all positions in firstpos(n) are in followpos(i) Compilers (cpl5316) Page 23 Lectured by : Rebaz Najeeb C1 C2F(C1) F(C2) L(C2)L(C1) followpos *F(n) L(n) followpos
- 29. Followpos example • Applying rule 1 • followpos(1) incl.{3} • followpos(2) incl.{3} • followpos(3) incl.{4} • followpos(4) incl.{5} • followpos(5) incl.{6} • Applying rule 2 • followpos(1) incl.{1,2} • followpos(2) incl.{1,2} Compilers (cpl5316) Page 24 Lectured by : Rebaz Najeeb {6}{1, 2, 3} {5}{1, 2, 3} {4}{1, 2, 3} {3}{1, 2, 3} {1, 2}{1, 2} * {1, 2}{1, 2} | {1}{1} a {2}{2} b {3}{3} a {4}{4} b {5}{5} b {6}{6} # 1 2 3 4 5 6 (a|b)*abb#1 2 3 4 5 6 Step 3- B
- 30. A=firstpos(n0)={1,2,3} Move[A,a]= followpos(1) U followpos(3)= {1,2,3,4}=B o Move[A,b]= followpos(2)={1,2,3}=A o Move[B,a]= followpos(1) U followpos(3)=B o Move[B,b]= followpos(2) U followpos(4)={1,2,3,5}=C RE to DFA Compilers (cpl5316) Page 26 Lectured by : Rebaz Najeeb 1,2,3 start a 1,2, 3,4 1,2, 3,6 1,2, 3,5 b b b b a a a Node followpos 1 {1, 2, 3} 2 {1, 2, 3} 3 {4} 4 {5} 5 {6} 6 - (a|b)*abb# 1 2 3 4 5 6 Step 4
- 31. Minimizing Number of States of a DFA Compilers (cpl5316) Page 27 Lectured by : Rebaz Najeeb • partition the set of states into two groups: – G1 : set of accepting states – G2 : set of non-accepting states • For each new group G – partition G into subgroups such that states s1 and s2 are in the same group iff for all input symbols a, states s1 and s2 have transitions to states in the same group. • Start state of the minimized DFA is the group containing the start state of the original DFA. • Accepting states of the minimized DFA are the groups containing the accepting states of the original DFA.
- 32. Minimizing DFA - example Compilers (cpl5316) Page 28 Lectured by : Rebaz Najeeb b a a b b 3 a 2 1 G1 = {2} G2 = {1,3} G2 cannot be partitioned because move(1,a)=2 move(3,a)=2 move(1,b)=3 move(2,b)=3 So, the minimized DFA (with minimum states) {1,3} a a b b {2}
- 33. Compilers (cpl5316) Page 29 Lectured by : Rebaz Najeeb