Self-learning Intrusion Prevention Systems.
•
0 j'aime•18 vues

Self-learning Intrusion Prevention Systems.

Recommandé
Recommandé
Contenu connexe
Similaire à Self-learning Intrusion Prevention Systems.
Similaire à Self-learning Intrusion Prevention Systems. (20)
Plus de Kim Hammar
Plus de Kim Hammar (16)
Dernier
Dernier (20)
Self-learning Intrusion Prevention Systems.
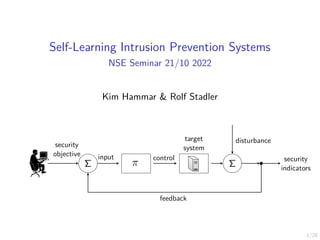
- 1. 1/28 Self-Learning Intrusion Prevention Systems NSE Seminar 21/10 2022 Kim Hammar & Rolf Stadler π Σ Σ security objective feedback control input target system security indicators disturbance
- 2. 2/28 Use Case: Intrusion Prevention I A Defender owns an infrastructure I Consists of connected components I Components run network services I Defender defends the infrastructure by monitoring and active defense I Has partial observability I An Attacker seeks to intrude on the infrastructure I Has a partial view of the infrastructure I Wants to compromise specific components I Attacks by reconnaissance, exploitation and pivoting Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 3. 3/28 Challenges: Evolving and Automated Attacks I Challenges I Evolving & automated attacks I Complex infrastructures Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 4. 3/28 Goal: Automation and Learning I Challenges I Evolving & automated attacks I Complex infrastructures I Our Goal: I Automate security tasks I Adapt to changing attack methods Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 5. 3/28 Approach: Self-Learning Security Systems I Challenges I Evolving & automated attacks I Complex infrastructures I Our Goal: I Automate security tasks I Adapt to changing attack methods I Our Approach: Self-Learning Systems: I real-time telemetry I stream processing I theories from control/game/decision theory I computational methods (e.g. dynamic programming & reinforcement learning) I automated network management (SDN, NFV, etc.) Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 6. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 7. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 8. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 9. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 10. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 11. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 12. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 13. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins
- 14. 4/28 The Intrusion Prevention Problem 20 40 60 80 100 120 140 160 180 200 0.5 1 t b 20 40 60 80 100 120 140 160 180 200 50 100 150 200 t Alerts 20 40 60 80 100 120 140 160 180 200 5 10 15 t Logins When to take a defensive action? Which action to take?
- 15. 5/28 Self-learning Intrusion Prevention: Current Landscape Levels of security automation No automation. Manual detection. Manual prevention. No alerts. No automatic responses. Lack of tools. 1980s 1990s 2000s-Now Research Operator assistance. Manual detection. Manual prevention. Audit logs. Security tools. Partial automation. System has automated functions for detection/prevention but requires manual updating and configuration. Intrusion detection systems. Intrusion prevention systems. High automation. System automatically updates itself. Automated attack detection. Automated attack mitigation.
- 16. 6/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 17. 6/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 18. 6/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 19. 6/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 20. 6/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 21. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 22. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 23. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 24. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 25. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 26. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 27. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 28. 7/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 29. 8/28 Creating a Digital Twin of the Target Infrastructure s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 30. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 31. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 32. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 33. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 34. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 35. 9/28 Creating a Digital Twin of the Target Infrastructure I Emulate hosts with docker containers I Emulate IPS and vulnerabilities with software I Network isolation and traffic shaping through NetEm in the Linux kernel I Enforce resource constraints using cgroups. I Emulate client arrivals with Poisson process I Internal connections are full-duplex & loss-less with bit capacities of 1000 Mbit/s I External connections are full-duplex with bit capacities of 100 Mbit/s & 0.1% packet loss in normal operation and random bursts of 1% packet loss Attacker Clients . . . Defender 1 IPS 1 alerts Gateway 7 8 9 10 11 6 5 4 3 2 12 13 14 15 16 17 18 19 21 23 20 22 24 25 26 27 28 29 30 31
- 36. 9/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 37. 10/28 System Identification ˆ f O (o t |0) Probability distribution of # IPS alerts weighted by priority ot 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 ˆ f O (o t |1) Fitted model Distribution st = 0 Distribution st = 1 I The distribution fO of defender observations (system metrics) is unknown. I We fit a Gaussian mixture distribution ˆ fO as an estimate of fO in the target infrastructure. I For each state s, we obtain the conditional distribution ˆ fO|s through expectation-maximization.
- 38. 10/28 Our Approach for Automated Network Security s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation System Target Infrastructure Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation System Reinforcement Learning & Generalization Strategy evaluation & Model estimation Automation & Self-learning systems
- 39. 11/28 The Simulation System I We model the evolution of the system with a discrete-time dynamical system. I We assume a Markovian system with stochastic dynamics and partial observability. Stochastic System (Markov) Noisy Sensor Optimal filter Controller action at observation ot state st belief bt
- 40. 11/28 The Simulation System I We model the evolution of the system with a discrete-time dynamical system. I We assume a Markovian system with stochastic dynamics and partial observability. I A Partially Observed Markov Decision Process (POMDP) I If attacker is static. I A Partially Observed Stochastic Game (POSG) I If attacker is dynamic. Stochastic System (Markov) Noisy Sensor Optimal filter Controller Attacker action a (1) t action a (2) t observation ot state st belief bt
- 41. 11/28 The Simulation System I We model the evolution of the system with a discrete-time dynamical system. I We assume a Markovian system with stochastic dynamics and partial observability. I A Partially Observed Markov Decision Process (POMDP) I If attacker is static. I A Partially Observed Stochastic Game (POSG) I If attacker is dynamic. Stochastic System (Markov) Noisy Sensor Optimal filter Controller Attacker action a (1) t action a (2) t observation ot state st belief bt I Compute/learn control strategies: Stochastic approximation (RL), dynamic programming, linear programming, etc.
- 42. 12/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 43. 12/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 44. 12/28 Related Work on Self-Learning Security Systems External validity Use case/ control/ learning complexity Goal Georgia et al. 2000. (Next generation intrusion detection: reinforcement learning) Xu et al. 2005. (An RL approach to host-based intrusion detection) Servin et al. 2008. (Multi-agent RL for intrusion detection)
- 45. 12/28 Related Work on Self-Learning Security Systems External validity Use case/ control/ learning complexity Goal Georgia et al. 2000. (Next generation intrusion detection: reinforcement learning) Xu et al. 2005. (An RL approach to host-based intrusion detection) Servin et al. 2008. (Multi-agent RL for intrusion detection) Malialis et al. 2013. (Decentralized RL response to DDoS attacks) Zhu et al. 2019. (Adaptive Honeypot engagement) Apruzzese et al. 2020. (Deep RL to evade botnets)
- 46. 12/28 Related Work on Self-Learning Security Systems External validity Use case/ control/ learning complexity Goal Georgia et al. 2000. (Next generation intrusion detection: reinforcement learning) Xu et al. 2005. (An RL approach to host-based intrusion detection) Servin et al. 2008. (Multi-agent RL for intrusion detection) Malialis et al. 2013. (Decentralized RL response to DDoS attacks) Zhu et al. 2019. (Adaptive Honeypot engagement) Apruzzese et al. 2020. (Deep RL to evade botnets) Xiao et al. 2021. (RL approach to APT) etc. 2022.
- 47. 12/28 Related Work on Self-Learning Security Systems External validity Use case/ control/ learning complexity Goal Georgia et al. 2000. (Next generation intrusion detection: reinforcement learning) Xu et al. 2005. (An RL approach to host-based intrusion detection) Servin et al. 2008. (Multi-agent RL for intrusion detection) Malialis et al. 2013. (Decentralized RL response to DDoS attacks) Zhu et al. 2019. (Adaptive Honeypot engagement) Apruzzese et al. 2020. (Deep RL to evade botnets) Xiao et al. 2021. (RL approach to APT) etc. 2022.
- 48. 12/28 Related Work on Self-Learning Security Systems External validity Use case/ control/ learning complexity Goal Georgia et al. 2000. (Next generation intrusion detection: reinforcement learning) Xu et al. 2005. (An RL approach to host-based intrusion detection) Servin et al. 2008. (Multi-agent RL for intrusion detection) Malialis et al. 2013. (Decentralized RL response to DDoS attacks) Zhu et al. 2019. (Adaptive Honeypot engagement) Apruzzese et al. 2020. (Deep RL to evade botnets) Xiao et al. 2021. (RL approach to APT) etc. 2022. Our work 2020-2022 only 2 actions 3 states!
- 49. 13/28 1: Intrusion Prevention through Optimal Stopping1 I Intrusion Prevention as an Optimal Stopping Problem: I A stochastic process (st)T t=1 is observed sequentially I Two options per t: (i) continue to observe; or (ii) stop I Find the optimal stopping time τ∗ : τ∗ = arg max τ Eτ " τ−1 X t=1 γt−1 RC st st+1 + γτ−1 RS sτ sτ # where RS ss0 & RC ss0 are the stop/continue rewards I Stop action = Defensive action Intrusion event time-step t = 1 Intrusion ongoing t t = T Early stopping times Stopping times that interrupt the intrusion Episode 1 Kim Hammar and Rolf Stadler. “Learning Intrusion Prevention Policies through Optimal Stopping”. In: International Conference on Network and Service Management (CNSM 2021). http://dl.ifip.org/db/conf/cnsm/cnsm2021/1570732932.pdf. Izmir, Turkey, 2021.
- 50. 14/28 1: Intrusion Prevention through Optimal Stopping2 Stochastic System (Markov) Noisy Sensor Optimal filter Stopping strategy at ∈ {S, C} IPS alerts ot state st belief bt ∈ [0, 1] I States: Intrusion st ∈ {0, 1}, terminal ∅. I Observations: I Number of IPS Alerts ot ∈ O I ot is drawn from r.v. O ∼ fO(·|st). I Based on history ht of observations, the defender can compute the belief bt(st) = P[st|ht]. I Actions: A1 = A2 = {S, C} I Rewards: security and service. I Transition probabilities: Follows from game dynamics. 2 Kim Hammar and Rolf Stadler. “Learning Intrusion Prevention Policies through Optimal Stopping”. In: International Conference on Network and Service Management (CNSM 2021). http://dl.ifip.org/db/conf/cnsm/cnsm2021/1570732932.pdf. Izmir, Turkey, 2021.
- 51. 14/28 Convex Stopping set with Threshold α∗ 1 ∈ B b(1) 0 1 belief space B = [0, 1]
- 52. 14/28 Convex Stopping set with Threshold α∗ 1 ∈ B b(1) 0 1 belief space B = [0, 1] S1 α∗ 1
- 53. 15/28 Bang-Bang Controller with Threshold α∗ 1 ∈ B 0 1 2 1 ak = π∗ k(b) b∗ 1 threshold b (belief) continue stop
- 54. 16/28 Learning Curves in Simulation and Emulation 0 50 100 Novice Reward per episode 0 50 100 Episode length (steps) 0.0 0.5 1.0 P[intrusion interrupted] 0.0 0.5 1.0 1.5 P[early stopping] 5 10 Duration of intrusion −50 0 50 100 experienced 0 50 100 150 0.0 0.5 1.0 0.0 0.5 1.0 1.5 0 5 10 0 20 40 60 training time (min) −50 0 50 100 expert 0 20 40 60 training time (min) 0 50 100 150 0 20 40 60 training time (min) 0.0 0.5 1.0 0 20 40 60 training time (min) 0.0 0.5 1.0 1.5 2.0 0 20 40 60 training time (min) 0 5 10 15 20 πθ,l simulation πθ,l emulation (∆x + ∆y) ≥ 1 baseline Snort IPS upper bound
- 55. 17/28 2: Intrusion Prevention through Optimal Multiple Stopping3 I Intrusion Prevention through Multiple Optimal Stopping: I Maximize reward of stopping times τL, τL−1, . . . , τ1: π∗ l ∈ arg max πl Eπl " τL−1 X t=1 γt−1 RC st ,st+1,L + γτL−1 RS sτL ,sτL+1,L + . . . + τ1−1 X t=τ2+1 γt−1 RC st ,st+1,1 + γτ1−1 RS sτ1 ,sτ1+1,1 # I Each stopping time = one defensive action 0 1 ∅ t ≥ 1 lt > 0 t ≥ 2 lt > 0 intrusion starts Qt = 1 final stop lt = 0 intrusion prevented lt = 0 3 Kim Hammar and Rolf Stadler. “Intrusion Prevention Through Optimal Stopping”. In: IEEE Transactions on Network and Service Management 19.3 (2022), pp. 2333–2348. doi: 10.1109/TNSM.2022.3176781.
- 56. 18/28 Structural Result: Optimal Multi-Threshold Policy & Nested Stopping Sets b(1) 0 1 belief space B = [0, 1]
- 57. 18/28 Structural Result: Optimal Multi-Threshold Policy & Nested Stopping Sets b(1) 0 1 belief space B = [0, 1] S1 α∗ 1
- 58. 18/28 Structural Result: Optimal Multi-Threshold Policy & Nested Stopping Sets b(1) 0 1 belief space B = [0, 1] S1 S2 α∗ 1 α∗ 2
- 59. 18/28 Structural Result: Optimal Multi-Threshold Policy & Nested Stopping Sets b(1) 0 1 belief space B = [0, 1] S1 S2 . . . SL α∗ 1 α∗ 2 α∗ L . . .
- 60. 19/28 Comparison against State-of-the-art Algorithms 0 10 20 30 40 50 60 training time (min) 0 50 100 Reward per episode against Novice 0 10 20 30 40 50 60 training time (min) Reward per episode against Experienced 0 10 20 30 40 50 60 training time (min) Reward per episode against Expert PPO ThresholdSPSA Shiryaev’s Algorithm (α = 0.75) HSVI upper bound
- 61. 20/28 3: Intrusion Prevention through Optimal Multiple Stopping and Game-Play4 I Optimal stopping (Dynkin) game: I Dynamic attacker I Stop actions of the defender determine when to take defensive actions I Goal: find Nash Equilibrium (NE) strategies and game value J1(π1,l , π2,l ) = E(π1,l ,π2,l ) " T X t=1 γt−1 Rlt (st, at) # B1(π2,l ) = arg max π1,l ∈Π1 J1(π1,l , π2,l ) B2(π1,l ) = arg min π2,l ∈Π2 J1(π1,l , π2,l ) (π∗ 1,l , π∗ 2,l ) ∈ B1(π∗ 2,l ) × B2(π∗ 1,l ) NE π̃2,l ∈ B2(π1,l ) π2,l π1,l π̃1,l ∈ B1(π2,l ) π̃0 2,l ∈ B2(π0 1,l ) π0 2,l π0 1,l π̃0 1,l ∈ B1(π0 2,l ) . . . π∗ 2,l ∈ B2(π∗ 1,l ) π∗ 1,l ∈ B1(π∗ 2,l ) 4 Kim Hammar and Rolf Stadler. “Learning Security Strategies through Game Play and Optimal Stopping”. In: Proceedings of the ML4Cyber workshop, ICML 2022, Baltimore, USA, July 17-23, 2022. PMLR, 2022.
- 62. 21/28 Structure of Best Response Strategies b(1) Defender 0 1
- 63. 21/28 Structure of Best Response Strategies b(1) Defender 0 1 S (1) 1 α̃1
- 64. 21/28 Structure of Best Response Strategies b(1) Defender 0 1 S (1) 1 S (1) 2 α̃1 α̃2
- 65. 21/28 Structure of Best Response Strategies b(1) Defender 0 1 S (1) 1 S (1) 2 . . . S (1) L α̃1 α̃2 α̃L . . .
- 66. 21/28 Structure of Best Response Strategies b(1) Defender 0 1 S (1) 1,π2,l S (1) 2,π2,l . . . S (1) L,π2,l α̃1 α̃2 α̃L . . . b(1) Attacker 0 1 S (2) 1,1,π1,l S (2) 1,L,π1,l β̃1,1 β̃1,L β̃0,1 . . . β̃0,L . . . S (2) 0,1,π1,l S (2) 0,L,π1,l
- 67. 22/28 Converge Rates and Comparison with State-of-the-art Algorithms 0 10 20 30 40 50 60 running time (min) 0 2 4 Exploitability 0 10 20 30 40 50 60 running time (min) 0 250 500 750 Approximation error (gap) 55.0 57.5 60.0 7.5 10.0 T-FP NFSP HSVI
- 68. 23/28 4: Learning in Dynamic IT Environments5 Policy Learning Agent Environment System Identification s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Digital Twin and Attack Scenarios Target System Model M Traces h1, h2, . . . Policy π Configuration I and change events Policy π Policy evaluation & Data collection Automated security policy 5 Kim Hammar and Rolf Stadler. “An Online Framework for Adapting Security Policies in Dynamic IT Environments”. In: International Conference on Network and Service Management (CNSM 2022). Thessaloniki, Greece, 2022.
- 69. 24/28 4: Learning in Dynamic IT Environments6 Algorithm 1: High-level execution of the framework Input: emulator: method to create digital twin ϕ: system identification algorithm φ: policy learning algorithm 1 Algorithm (emulator, ϕ, φ) 2 do in parallel 3 DigitalTwin(emulator) 4 SystemIdProcess(ϕ) 5 LearningProcess(φ) 6 end 1 Procedure DigitalTwin(emulator) 2 Loop 3 π ← ReceiveFromLearningProcess() 4 ht ← CollectTrace(π) 5 SendToSystemIdProcess(ht) 6 UpdateDigitalTwin(emulator) 7 EndLoop 1 Procedure SystemIdProcess(ϕ) 2 Loop 3 h1, h2, . . . ← ReceiveFromDigitalTwin() 4 M ← ϕ(h1, h2, . . .) // estimate model 5 SendToLearningProcess(M) 6 EndLoop 1 Procedure LearningProcess(φ) 2 Loop 3 M ← ReceiveFromSystemIdProcess() 4 π ← φ(M) // learn policy π 5 SendToDigitalTwin(π) 6 EndLoop 6 Kim Hammar and Rolf Stadler. “An Online Framework for Adapting Security Policies in Dynamic IT Environments”. In: International Conference on Network and Service Management (CNSM 2022). Thessaloniki, Greece, 2022.
- 70. 25/28 Learning in Dynamic IT Environments7 200 400 600 # clients 5000 10000 E[ Ẑ] 0 10 20 30 40 50 execution time (hours) 0 20 Avg reward E h Ẑt,O|1 i E h Ẑt,O|0 i E h Ẑ [10] t,O|1 i E h Ẑ [10] t,O|0 i upper bound Our framework [10] Results from running our framework for 50 hours in the digital twin/emulation. 7 Kim Hammar and Rolf Stadler. “An Online Framework for Adapting Security Policies in Dynamic IT Environments”. In: International Conference on Network and Service Management (CNSM 2022). Thessaloniki, Greece, 2022.
- 71. 26/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 72. 26/28 Outline I Use Case & Motivation: I Use case: Intrusion prevention I Self-learning security systems: current landscape I Our Approach I Network emulation and digital twin I Stochastic game simulation and reinforcement learning I Summary of results so far I Comparison with related work I Intrusion prevention through optimal multiple stopping I Dynkin games and learning in dynamic environments I System for policy validation I Outlook on future work I Extend use case I Rollout-based methods I Conclusions I Takeaways
- 73. 27/28 Current and Future Work Time st st+1 st+2 st+3 . . . rt+1 rt+2 rt+3 rrT 1. Extend use case I Additional defender actions I Utilize SDN controller and NFV-based defenses I Increase observation space and attacker model I More heterogeneous client population 2. Extend solution framework I Model-predictive control I Rollout-based techniques I Extend system identification algorithm 3. Extend theoretical results I Exploit symmetries and causal structure I Utilize theory to improve sample efficiency I Decompose solution framework hierarchically
- 74. 28/28 Conclusions I We develop a method to automatically learn security strategies. I We apply the method to an intrusion prevention use case. I We design a solution framework guided by the theory of optimal stopping. I We present several theoretical results on the structure of the optimal solution. I We show numerical results in a realistic emulation environment. s1,1 s1,2 s1,3 . . . s1,n s2,1 s2,2 s2,3 . . . s2,n . . . . . . . . . . . . . . . Emulation Target System Model Creation & System Identification Strategy Mapping π Selective Replication Strategy Implementation π Simulation & Learning