Ai for Human Communication
•
1 j'aime•760 vues

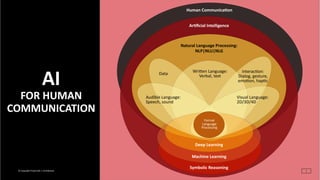
AI for human communication is about recognition, parsing, understanding, and generating natural language. The concept of natural language is evolving. A key focus is the analysis, interpretation, and generation of verbal and written language. Other language focus areas include haptic, sonic, and visual language, data, and interaction.

Recommandé
Recommandé
Contenu connexe
Similaire à Ai for Human Communication
Similaire à Ai for Human Communication (20)
Plus de Mills Davis
Plus de Mills Davis (7)
Dernier
Dernier (20)
Ai for Human Communication
- 2. © Copyright Project10x | Confidential 2 • Lawrence Mills Davis is founder and managing director of Project10X, a research consultancy known for forward-looking industry studies; multi-company innovation and market development programs; and business solution strategy consulting. Mills brings 30 years experience as an industry analyst, business consultant, computer scientist, and entrepreneur. He is the author of more than 50 reports, whitepapers, articles, and industry studies. • Mills researches artificial intelligence technologies and their applications across industries, including cognitive computing, machine learning (ML), deep learning (DL), predictive analytics, symbolic AI reasoning, expert systems (ES), natural language processing (NLP), conversational UI, intelligent assistance (IA), and robotic process automation (RPA), and autonomous multi- agent systems. • For clients seeking to exploit transformative opportunities presented by the rapidly evolving capabilities of artificial intelligence, Mills brings a depth and breadth of expertise to help leaders realize their goals. More than narrow specialization, he brings perspective that combines understanding of business, technology, and creativity. Mills fills roles that include industry research, venture development, and solution envisioning. Lawrence Mills Davis Managing Director Project10X mdavis@project10x.com 202-667-6400 © Copyright Project10x | Confidential
- 3. © Copyright Project10x | Confidential SECTIONS 1. AI for human communication 2. AI for natural language summarization 3. AI for natural language generation 3
- 6. © Copyright Project10x | Confidential This research deck précis information from the Forrester Digital Transformation Conference in May 2017. It compiles selected copy and visuals from conference presentations and recent Forrester research reports. Contents are organized into the following sections: ▪ Digital transfor 6 Overview of AI for human communication •Natural language processing (NLP) is the confluence of artificial intelligence (AI) and linguistics. •A key focus is the analysis, interpretation, and generation of verbal and written language. •Other language focus areas include audible & visual language, data, and interaction. •Formal programming languages enable computers to process natural language and other types of data. •Symbolic reasoning employs rules and logic to frame arguments, make inferences, and draw conclusions. •Machine learning (ML) is a area of AI and NLP that solves problems using statistical techniques, large data sets and probabilistic reasoning. •Deep learning (DL) is a type of machine learning that uses layered artificial neural networks. Deep Learning Machine Learning Human Communica6on Ar6ficial Intelligence Natural Language Processing: NLP|NLU|NLG InteracKon: Dialog, gesture, emoKon, hapKc Audible Language: Speech, sound Visual Language: 2D/3D/4D WriVen Language: Verbal, text Formal Language Processing Symbolic Reasoning Data
- 11. © Copyright Project10x | Confidential Text analytics 11 Text mining is the discovery by computer of new, previously unknown information, by automatically extracting it from different written resources. A key element is the linking together of the extracted information together to form new facts or new hypotheses to be explored further by more conventional means of experimentation. Text analytics is the investigation of concepts, connections, patterns, correlations, and trends discovered in written sources. Text analytics examine linguistic structure and apply statistical, semantic, and machine-learning techniques to discern entities (names, dates, places, terms) and their attributes as well as relationships, concepts, and even sentiments. They extract these 'features' to databases or semantic stores for further analysis, automate classification and processing of source documents, and exploit visualization for exploratory analysis. IM messages, email, call center logs, customer service survey results, claims forms, corporate documents, blogs, message boards, and websites are providing companies with enormous quantities of unstructured data — data that is information-rich but typically difficult to get at in a usable way. Text analytics goes beyond search to turn documents and messages into data. It extends Business Intelligence (BI) and data mining and brings analytical power to content management. Together, these complementary technologies have the potential to turn knowledge management into knowledge analytics.
- 13. © Copyright Project10x | Confidential Speech I/O vs NLP vs NLU NLP NLU syntactic parsing machine translation named entity recognition (NER) part-of-speech tagging (POS) semantic parsing relation extraction sentiment analysis coreference resolution dialogue agents paraphrase & natural language inference text-to- speech (TTS) summarization automatic speech recognition (ASR) text categorization question answering (QA) Speech I/O 13© Copyright Project10x | Confidential
- 17. © Copyright Project10x | Confidential 17 Source: NarraKve Science Explainable AI (XAI) New machine-learning systems will have the ability to explain their rationale, characterize their strengths and weaknesses, and convey an understanding of how they will behave in the future. State-of-the-art human- computer interface techniques will translate models into understandable and useful explanation dialogues for the end user. Source: DARPA New learning process Training data Explainable model Explanation interface This is a cat: • It has fur, whiskers, and claws. • It has this feature: • I understand why/why not • I know when it will succeed/fail
- 19. © Copyright Project10x | Confidential Source: Robert Horn Source: Robert Horn Visual Language The integration of words, images, and shapes into a single communication unit. • Words are essential to visual language. They give conceptual shape, and supply the capacity to name, define, and classify elements, and to discuss abstractions. • Images are what we first think of when we think of visual language. But, without words and/or shapes, images are only conventional visual art. • Shapes differ from images. They are more abstract. We combine them with words to form diagramming systems. Shapes and their integration with words and/or images is an essential part of visual language. 19
- 21. © Copyright Project10x | Confidential Toward understanding diagrams using recurrent networks and deep learning 21 Source: AI2 Diagrams are rich and diverse. The top row depicts inter class variability of visual illustrations. The bottom row shows intra-class variation for the water cycle category. LSTM1 LSTM1 LSTM1 LSTM1 LSTM2 LSTM2 LSTM2 LSTM2 c0 c1 c2 cT [xycand, scorecand, overlapcand, … scorerel , seenrel … ] Candidate Relationships Diagram Parse Graph Stacked LSTM Network Relationship Feature Vector FC1 FC2 FC1 FC2 FC1 FC2 FC1 FC2 FC3 FC3 FC3 FC3 Add No change Add Final Fully Connected Fully Connected Architecture for inferring DPGs from diagrams. The LSTM based network exploits global constraints such as overlap, coverage, and layout to select a subset of relations amongst thousands of candidates to construct a DPG. The diagram depicts The life cycle of a) frog 0.924 b) bird 0.02 c) insecticide 0.054 d) insect 0.002 How many stages of Growth does the diagram Feature? a) 4 0.924 b) 2 0.02 c) 3 0.054 d) 1 0.002 What comes before Second feed? a) digestion 0.0 b) First feed 0.15 c) indigestion 0.0 d) oviposition 0.85 Sample question answering results. Left column is the diagram. The second column shows the answer chosen and the third column shows the nodes and edges in the DPG that Dqa-Net decided to attend to (indicated by red highlights). Diagrams represent complex concepts, relationships and events, often when it would be difficult to portray the same information with natural images. Diagram Parse Graphs (DPG) model the structure of diagrams. RNN+LSTM-based syntactic parsing of diagrams learns to infer DPGs. Adding a DPG-based attention model enables semantic interpretation and reasoning for diagram question answering.
- 22. © Copyright Project10x | Confidential 22 Computer vision • The ability of computers to idenKfy objects, scenes, and acKviKes in unconstrained (that is, naturalisKc) visual environments. • Computer vision has been transformed by the rise of deep learning. • The confluence of large-scale computing, especially on GPUs, the availability of large datasets, especially via the internet, and refinements of neural network algorithms has led to dramatic improvements. • Computers are able to perform some (narrowly defined) visual classification tasks better than people. A current research focus is automatic image and video captioning. © Copyright Project10x | Confidential
- 23. © Copyright Project10x | Confidential Image annotation and captioning using deep learning a man riding a motorcycle on a city street a plate of food with meat and vegetables 23
- 26. © Copyright Project10x | Confidential Natural Language Genera6on Natural language generation (NLG) is the process of producing meaningful phrases and sentences in the form of natural language from some internal representation, and involves: • Text planning − It includes retrieving the relevant content from knowledge base. • Sentence planning − It includes choosing required words, forming meaningful phrases, setting tone of the sentence. • Text realization − It is mapping sentence plan into sentence (or visualization) structure, followed by text-to-speech processing and/or visualization rendering. • The output may be provided in any natural language, such as English, French, Chinese or Tagalog, and may be combined with graphical elements to provide a mulKmodal presentaKon. • For example, the log files of technical monitoring devices can be analyzed for unexpected events and transformed into alert-driven messages; or numerical Kme-series data from hospital paKent monitors can be rendered as hand-over reports describing trends and events for medical staff starKng a new shi{. 26
- 27. © Copyright Project10x | Confidential 27 Source: NarraKve Science Deep learning for story telling
- 28. © Copyright Project10x | Confidential Summarization, and algorithms to make text quantifiable, allow us to derive insights from Large amounts of unstructured text data. Unstructured text has been slower to yield to the kinds of analysis that many businesses are starting to take for granted. We are beginning to gain the ability to do remarkable things with unstructured text data. First, the use of neural networks and deep learning for text offers the ability to build models that go beyond just counting words to actually representing the concepts and meaning in text quantitatively. These examples start simple and eventually demonstrate the breakthrough capabilities realized by the application of sentence embedding and recurrent neural networks to capturing the semantic meaning of text. 28 Source: NarraKve Science Toward multi-modal deep learning and language generation
- 37. © Copyright Project10x | Confidential INTRODUCTION The sections of this research deck generally follow the order of the Fast Forward Labs Summarization report. Also, we include slides that provide tutorial information, drill-down on technical topics, and other material that expands upon themes of the report. • Automated summarization — This section introduces summarization, genres of summary, basic concepts of summarization systems, and the spectrum of text summarization techniques • Automated summarization using statistical heuristics for sentence extraction — This section summarizes the first POC discussed in the FFL report. • Automated summarization using unstructured machine learning to model topics — This section overviews the topic modeling approach in POC-2. It then drills down to provide additional information about topic modeling, document- term matrix, semantic relatedness and TF•IDF, probabilistic topic models, convolutional neural networks, topic modeling algorithms, latent semantic analysis, latent Dirichlet allocation, advanced topic modeling techniques, and topic- modeled multi-document summarization. • Automated summarization using recurrent neural networks to predict sentences — This section overviews three different POCs that utilize word and sentence embeddings and different types of neural networks to extract or generate summary sentences. It then drills down to discuss semantic hashing, word embeddings, skip- thoughts, feedforward networks, recurrent neural networks, long short term memory, sequence-to-sequence language translation, deep learning for abstractive text summarization, and prior semantic knowledge. • NLP technology providers — Coverage not part of this deck. 37
- 38. © Copyright Project10x | Confidential TOPICS 1. Automated summarization 2. Automated summarization using statistical heuristics for sentence extraction 3. Automated summarization using unstructured machine learning to model topics 4. Automated summarization using recurrent neural networks to predict sentence 38
- 39. © Copyright Project10x | Confidential 39 Deep Learning Machine Learning Natural Language Processing Ar6ficial Intelligence • Natural Language Processing (NLP) is the confluence of Artificial Intelligence (AI) and linguistics. A key focus is analysis and interpretation of written language. • Machine Learning (or ML) is an area of AI and NLP that uses large data sets and statistical techniques for problem solving. • Deep Learning (DL) is a type of machine learning that uses neural networks (including Convolution Neural Networks (CNN) and Recurrent Neural Networks (RNN)) to process natural language and other types of data.
- 41. © Copyright Project10x | Confidential • The goal of automated summarization is to produce a shorter version of a source text by preserving the meaning and the key contents of the original. A well written summary reduces the amount of cognitive work needed to digest large amounts of text. • Automatic summarization is part of artificial intelligence, natural language processing, machine learning, deep learning, data mining and information retrieval. • Document summarization tries to create a representative extract or abstract of the entire document, by finding or generating the most informative sentences. • Image summarization tries to find the most representative and important (i.e. salient) images and generates explanatory captions of still or moving scenes, including objects, events, emotions, etc. 41 Automatic summarization
- 42. © Copyright Project10x | Confidential 42 S u m m a r i z a t i o n Output documentInput document Purpose Source size Single-document Multi-document Specificity Domain-specific General Form Audience Generic Query-oriented Usage Expansiveness Indicative Informative Derivation Conventionality Background Just-the-news Extract Abstract Partiality Neutral Evaluative Fixed Floating Scale Genre Summarization classification Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Genres of summary include: • Single-document vs. multi-document source — based on one text vs. fuses together many texts. E.g., for multi-document summaries we may want one summary with common information, or similarities and differences among documents, or support and opposition to specific ideas and concepts. • Generic vs. query-oriented — provides author’s view vs. reflects user’s interest. • Indicative vs. informative — what’s it about (quick categorization) vs. substitute for reading it (content processing). • Background vs. just-the-news — assumes reader’s prior knowledge is poor vs. up-to-date. • Extract vs. abstract — lists fragments of text vs. re-phrases content coherently.
- 43. © Copyright Project10x | Confidential 43 extractive abstractive select subset of words output in best order encode hidden state decode to text sequence Extractive vs. Abstractive summarization
- 44. © Copyright Project10x | Confidential Query Document MulKple Documents Automatic summarization machine 44 10% 50% 100% Long Very Brief Headline Brief IN OUT Extract Abstract IndicaKve InformaKve Generic Query-oriented Background Just the news Extracted summaries Computable models Abstracted summaries • Frames, templates • ProbabilisKc models • Knowledge graphs • Internal states
- 48. © Copyright Project10x | Confidential 48 1 VECTORIZE 2 SCORE 3 SELECT Extractive summarization Sentence extraction uses a combination of statistical heuristics to identify the most salient sentences of a text. It works as a filter, which allows only important sentences to pass. Individual heuristics are weighted according to their importance. Each assigns a (positive or negative) score to the sentence. After all heuristics have been applied, highest-scoring sentences become the summary. Extractive summarization involves three steps: • Vectorize — First, turn each passage into a sequence of numbers (a vector) that can be analyzed and scored by a computer. • Score — Rate each sentence by assigning a score or rank to its vectorized representation. • Select — Choose a small number of the best scoring sentences. These are the summary.
- 49. © Copyright Project10x | Confidential 49 Input document(s) Summary Pre-processing Normalizer Segmenter Stemmer Stop-word eliminator List of sentences List of pre-processed words for each sentence Processing Clustering Learning Scoring List of clusters Summary size P(f|C) Extraction Extraction Sentences scores ReOrdering List of first higher scored sentences Reordered sentences Extrac6ve summariza6on process • Preprocessing reads and cleans-up data (including stop word removal, numbers, punctuation, short words, stemming, lemmatization), and builds the document term matrix. • Processing vectorizes and scores sentences, which may entail heuristic, statistical, linguistic, graph-based, and machine learning methods. • Extraction selects, orders and stitches together highest scoring sentences, and presents the summary
- 50. © Copyright Project10x | Confidential • Training data — (Low) Preprocessing of data required. Training and validation data sets not required with statistical heuristics. • Domain expertise — (Hi) Adding statistical heuristics requires understanding domain features and the characteristics of the summary to be produced.. • Computational cost — (Low) Does not require special hardware or extensive preparation or run cycles times. • Interpretability — (Med-to-Hi) Statistical heuristics can account for how a sentence was extracted, but do not capture information about context and what sentences mean. • Machine learning — It is possible to process heuristics as features using supervised machine learning to model and classify them. For example, to learn where in a document significant sentence tend to occur. However, unsupervised approaches perform as well or better (as with topic modeling). 50 Statistical heuristics considerations The tradeoffs in computational cost and interpretability for different summarization systems Heuristics LDA RNN Interpretability ComputationalCost The tradeoffs in training data and domain expertise required for different summarization systems Heuristics LDA RNN Domain Expertise TrainingData
- 53. © Copyright Project10x | Confidential Topic modeling 53 Topic modeling learns topics by looking for groups of words that frequently co-occur. After training on a corpus, a topic model can be ap-plied to a document to determine the most prominent topics in it
- 54. © Copyright Project10x | Confidential 54 WordsTopics ObservedObserved Latent Documents Topic modeling approaches try to model relaKonships between observed words and documents by a set of latent topics. Topic modeling • A topic model is a type of statistical model for discovering the abstract "topics" that occur in a collection of documents. • Topic modeling is used to discover hidden semantic structures in a text body. • Documents are about several topics at the same time. Topics are associated with different words. Topics in the documents are expressed through the words that are used. • Latent topics are the “link” between the documents and words. Topics explain why certain words appear in a given document.
- 55. © Copyright Project10x | Confidential Document-Term Matrix • DTM describes the frequency of terms that occur in a collection of documents and is the foundation on which all topic modeling methods work. • The document-term matrix (DTM) describes the frequency of terms that occur in a collection of documents and is the foundation on which all topic modeling methods work. • Preprocessing steps are pretty much the same for all of the topic modeling algorithms: - Bag-of words (BOW) approaches are used, since the DTM does not contain ordering information. - Punctuation, numbers, short, rare and uninformative words are typically removed. - Stemming and lemmatization also may be applied. 55 Document-Term Matrix
- 56. © Copyright Project10x | Confidential • A key preprocessing step is to reduce high- dimensional term vector space to low- dimensional ‘latent’ topic space. • Two words co-occurring in a text: - signal that they are related - document frequency determines strength of signal - co-occurrence index • TF: Term Frequency — terms occurring more frequently in document are more important • IDF: Inverted Document Frequency — terms in fewer documents are more specific • TF * IDF indicates importance of term relative to the document 56 Semantic Analysis TF-IDF Dimension Reduction Semantic relatedness and TF-IDF
- 57. © Copyright Project10x | Confidential 57 Probabilistic topic model What is a topic? A list of probabilities for each of the possible words in a vocabulary. Example topic: • dog: 5% • cat: 5% • hause: 3% • hamster: 2% • turtle: 1% • calculus: 0.000001% • analytics: 0.000001% • .......
- 58. © Copyright Project10x | Confidential Convolu6onal neural network architecture for sentence classifica6on 58 This diagram illustrates a convolutional neural network (CNN) architecture for sentence classification. • It shows three filter region sizes: 2, 3 and 4, each of which has 2 filters. • Every filter performs convolution on the sentence matrix and generates (variable-length) feature maps. • Next, 1-max pooling is performed over each map, i.e., the largest number from each feature map is recorded. Thus a univariate feature vector is generated from all six maps, and these 6 features are concatenated to form a feature vector for the penultimate layer. • The final softmax layer then receives this feature vector as input and uses it to classify the sentence; here we assume binary classification and hence depict two possible output states. Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
- 59. © Copyright Project10x | Confidential Several different topic modeling algorithms: • LSA — Latent semantic analysis finds smaller (lower-rank) matrices that closely approximate DTM. • pLSA — Probabilistic LSA finds topic-word and topic-document associations that best match dataset and a specified number of topics (K). • LDA — Latent Dirichlet Allocation finds topic- word and topic-document associations that best match dataset and specified number of topics that come from Dirichlet distribution with given Dirichlet priors. • Other advanced topic modeling algorithms — will briefly mention several including CTM, DTM, HTM, RTM, STM, and sLDA. 59 Topic modeling algorithms
- 60. © Copyright Project10x | Confidential 6x4 DOCUMENTS T E R M S = 6x4 TOPICS T E R M S X X TOP 0 0 0 0 IC 0 0 0 0 IMPO 0 0 0 0 RTAN CE 4x4 DOCUMENTS T O P I C S 60 Latent semantic analysis • LSA is a technique of distributional semantics for analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. • LSA finds smaller (lower-rank) matrices that closely approximate the document- term matrix by picking the highest assignments for each word to topic, and each topic to document, and dropping the ones not of interest. • The contexts in which a certain word exists or does not exist determine the similarity of the documents.
- 61. © Copyright Project10x | Confidential Aspects that describe summaries 61 Latent Dirichlet Allocation • Latent Dirichlet Allocation (LDA) is an unsupervised, probabilistic, text clustering algorithm. • LDA finds topic-word and topic-document associations that best match dataset and specified number of topics that come from Dirichlet distribution with given Dirichlet priors. • LDA defines a generative model that can be used to model how documents are generated given a set of topics and the words in the topics. • The LDA model is built as follows: 1. Estimate topics as product of observed words 2. Use to estimate document topic proportions 3. Evaluate corpus based on the distributions suggested in (1) & (2) 4. Use (3) to improve topic estimations (1) 5. Reiterate until best fit found.
- 62. © Copyright Project10x | Confidential 62Source: Andrius Knispelis, ISSUU the topic distribution for document i a parameter that sets the prior on the per-document topic distributions a parameter that sets the prior on the per-topic word distributions the topic for the j’th word in a document i observed words in a document i N M Θα β Z W N words M documents A topic model developed by David Blei, Andrew Ng and Michael Jordan in 2003. It tells us what topics are present in any given document by observing all the words in it and producing a topic distribution. LATENT DIRICHLET ALLOCATION word word word word word word word word word word word word word word word word tfidf.mm wordids.txt words documents words topics model.lda Document Term Matrix Topic Model
- 64. © Copyright Project10x | Confidential 64Source: Andrius Knispelis, ISSUU preprocess the data Text corpus depends on the application domain. It should be contextualised since the window of context will determine what words are considered to be related. The only observable features for the model are words. Experiment with various stoplists to make sure only the right ones are getting in. Training corpus can be different from the documents it will be scored on. Good all utility corpus is Wikipedia. train the model The key parameter is the number of topics. Again, depends on the domain. Other parameters are alpha and beta. You can leave them aside to begin with and only tune later. Good place to start is gensim - free python library. score it on new document The goal of the model is not to label documents, but rather to give them a unique fingerprint so that they can be compared to each other in a humanlike fashion. evaluate the performance Evaluation depends on the application. Use Jensen-Shannon Distance as similarity metric. Evaluation should show whether the model captures the right aspects compared to a human. Also it will show what distance threshold is still being perceived as similar enough. Use perplexity to see if your model is representative of the documents you’re scoring it on. LDA process overview
- 65. © Copyright Project10x | Confidential LDA topic modeling process 65 Topics and their Words Tuning Parameters Dictionaries Bag-of-Words Bag of- words Dictionaries Tokenization Lemmatization Stopwords Removal LDA Vector Space ModelPreprocessing Step 1: Select β • The term distribution β is determined for each topic by β ∼ Dirichlet (δ). Step 2: Select α • The. proportions θ of the topic distribution for the document w are determined by: θ ∼ Dirichlet (α) Step 3: Iterate • For each of the N words wi - (a) Choose a topic zi ∼ Multinomial(θ). - (b) Choose a word wi from a multinomial probability distribution conditioned on the topic - zi : p(wi|zi, β). * β is the term distribution of topics and contains the probability of a word occurring in a given topic. * The process is purely based on frequency and co-occurrence of words • Pass through LDA algorithm and evaluate • Create document-term matrix, dictionaries, corpus of Bag-of-Words • Clean documents of as much noise as possible, for example: - Lowercase all the text - Replace all special characters and do n-gram tokenizing - Lemmatize - reduce words to their root form, e.g., “reviews” and “reviewing” to “review” - Remove numbers (e.g., “2017”) and remove HTML tags and symbols
- 66. © Copyright Project10x | Confidential • Correlated topic model — CTM allows topics to be correlated, leading to better prediction, which is more robust to overfitting. • Dynamic topic model — DTM models how each individual topic changes over time. • Supervised LDA — sLDA associates an external variable with each document, which defines a one-to-one correspondence between latent topics and user tags. • Relational topic model — RTM predicts which documents a new document is likely to be linked to. (E.g., tracking activities on Facebook in order to predict a reaction to an advertisement.) • Hierarchical topic model — HTM draws the relationship between one topic and another (which LDA does not) and indicates the level of abstraction of a topic (which CTM correlation does not). • Structural topic model — STM provides fast, transparent, replicable analyses that require few a priori assumptions about the texts under study. STM includes covariates of interest. Unlike LDA, topics can be correlated and each document has its own prior distribution over topics, defined by covariate X rather than sharing a mean, allowing word use within a topic to vary by covariate U. 66 Advanced topic modeling techniques
- 67. © Copyright Project10x | Confidential Topic modeling is a form of lossy compression because it expresses a document as a vector where each element can be thought of as the weight of that topic in that document. Each element of the vector has interpretable meaning. This makes topic modeling a powerful technique to apply in many more contexts than text summarization. For example: • A preprocessing step to generate features for arbitrary text classification tasks • A way to visualize and explore a corpus by grouping and linking similar documents • A solution to the cold-start problem that plagues collaborative filtering • Applied to non-text data, including images, genetic information, and click-through data. 67 Other uses of topic modeling
- 68. © Copyright Project10x | Confidential 68 Query focused0mul$Qdocument0summariza$on0 • a Document Document Document Document Document Input Docs Sentence Segmentation All sentences from documents Sentence Simplification Content Selection Sentence Extraction: LLR, MMR Extracted sentences Information Ordering Sentence Realization Summary All sentences plus simplified versions Query • Multi-document summarization aims to capture the important information of a set of documents related to the same topic and presenting it in a brief, representative, and pertinent summary. • Query-driven summarization encodes criteria as search specs. The user needs only certain types of information (e.g., I know what I want! — don’t confuse me with drivel!) System processes specs top- down to filter or analyze text portions. Templates or frames order information and shape presentation of the summary.
- 69. © Copyright Project10x | Confidential • Training data — (Medium) Unsupervised machine learning needs to preprocess and then learn from a significant number of documents. For example, 10,000 documents per topic. How many training documents depends on the number of topics, characteristics of the document domain, and the type of summary. The number of topics is a fixed input. • Domain expertise — (Medium) Off-the-shelf topic modeling algorithms learn directly from the data, and do not require hand-written summaries in addition to the original documents. They identify structures in data (clusters of words), but on their own have no way to name or describe these structures. Choosing how to label topics, select sentences, and present extracts requires some domain knowledge. • Computational cost — (Medium-to-hi) Training a topic model with LDA requires minutes or hours, rather than days or weeks, using a PC (CPU) or on-line service (if larger data sets). Post-learning the summarization is much quicker. • Interpretability — (Hi) Topic modeling is the most interpretable approach discussed here. Like statistical heuristics, the reason why a sentence was selected is transparent. Furthermore, the intermediate vector reveals information that is hidden in the text. The topic model discerns it by comparing the text to its memory of a large corpus of training documents. 69 Topic modeling considerations The tradeoffs in computational cost and interpretability for different summarization systems Heuristics LDA RNN Interpretability ComputationalCost The tradeoffs in training data and domain expertise required for different summarization systems Heuristics LDA RNN Domain Expertise TrainingData
- 72. © Copyright Project10x | Confidential 72 Semantic hashing is using a deep autoencoder as a hash- function to map a relatively small number of binary variables to map documents to memory addresses in such a way that semantically similar documents are located at nearby addresses. Semantic Hashing Function Document Semantic Hashing Address Space Semantically Silmiiar Documents European Community Energy Markets Accounts/Earnings Learntomapdocuments into small number of semantic binary codes. Retrieve similardocuments storedat the nearbyaddresses with no searchat all.
- 73. © Copyright Project10x | Confidential “You shall know a word by the company it keeps” — John Firth 73 Seman6c rela6ons in vector space Word embeddings A word’s meaning is embedded by the surrounding words. Word2vec is a two-layer neural net for pre-processing text. Its input is a text corpus. Its outputs are word embeddings — a set of feature vectors for words in that corpus. Word vectors are positioned in the space so that words that share common contexts (word(s) preceding and/or following) are located in close proximity to each other. One of two model architectures are used to produce the word embeddings distribution. These include continuous bag-of-words (CBOW) and continuous skip-gram: • With CBOW, the model predicts the current word from a window of surrounding context words without considering word order. • With skip-gram, the model uses the current word to predict the surrounding window of context words, and weighs nearby words more heavily than more distant context words. Word2vec embedding captures subtle syntactical and semantic structure in the text corpus and can be used to map similarities, analogies and compositionality.
- 75. © Copyright Project10x | Confidential 75 Feedforward neural network Source: A Beginner’s Guide to Recurrent Networks and LSTMs Neural networks • A neural network is a system composed of many simple processing elements operating in parallel, which can acquire, store, and utilize experiential knowledge from data. • Input examples are fed to the network and transformed into an output. For example, to map raw data to categories, recognizing patterns that signal, for example, that an input image should be labeled “cat” or “elephant.” • Feedforward neural networks move information straight through (never touching a given node twice). Once trained the neural network has no notion of order in time. It only considers the current example it has been exposed, nothing before that.
- 76. © Copyright Project10x | Confidential 76Source: A Beginner’s Guide to Recurrent Networks and LSTMs Simple Recurrent Neural Network architecture model Recurrent neural network (RNN) • A recurrent neural network (RNN) can give itself feedback from past experiences. It maintains a hidden state that changes as it sees different inputs. Like short-term memory, this enables answers based on both current input and past experience. • RNNs are distinguished from feedforward networks by having this feedback loop. Recurrent networks take as their input not just the current input example they see, but also what they perceived one step back in time. RNNs have two sources of input, the present and the recent past, which combine to determine how they respond to new data.
- 77. © Copyright Project10x | Confidential 77Source: A Beginner’s Guide to Recurrent Networks and LSTMs Long short term memory (LSTM) • Long Short Term Memory (LSTM) empowers a RNN with longer- term recall. This allows the model to make more context-aware predictions. • LSTM has gates that act as differentiable RAM memory. Access to memory cells is guarded by “read”, “write” and “erase” gates. • Starting from the bottom of the diagram, the triple arrows show where information flows into the cell at multiple points. That combination of present input and past cell state is fed into the cell itself, and also to each of its three gates, which will decide how the input will be handled. • The black dots are the gates themselves, which determine respectively whether to let new input in, erase the present cell state, and/or let that state impact the network’s output at the present time step. S_c is the current state of the memory cell, and g_y_in is the current input to it. Remember that each gate can be open or shut, and they will recombine their open and shut states at each step. The cell can forget its state, or not; be written to, or not; and be read from, or not, at each time step, and those flows are represented here.
- 78. © Copyright Project10x | Confidential 78 Abstractive text summarization Abstractive text summarization is a two-step process: • A sequence of text is encoded into some kind of internal representation. • This internal representation is then used to guide the decoding process back into the summary sequence, which may express ideas using words and phrases not found in the source. State of the art architectures use recurrent neural networks for both the encoding and the decoding step; often with attention over the input during decoding as additional help. internal representation summarysource document encoder decoder
- 79. © Copyright Project10x | Confidential • Training data — (Hi) RNN summarizers have the most extensive data requirements that include language models (such as word2vec and skip-thoughts) for the vectorization/ embedding step, and a large sampling of training documents. Depending on choice of algorithm(s), training documents may also need corresponding summaries. • Domain expertise — (Low) RNN summarizers generally demand less domain specific expertise or hand-crafted linguistic features to develop. Abstractive summarization architectures exist that combine RNNs and probabilistic models to cast the summarization task as a neural machine translation problem, where the models, trained on a large amount of data, learn the alignments between the input text and the target summary through an attention encoder- decoder paradigm enhanced with prior knowledge, such as linguistic features. • Computational cost — (Hi-to-very hi) RNNs require large amounts of preprocessing, and a large (post-training) static shared global state. Computations are best done on a GPU configuration. • Interpretability — (Low) RNN summarizers do not provide simple answers to the why of sentence selection and summary generation. Intermediate embeddings (and internal states) are not easily understandable in a global sense. 79 Google NMT, arxiv.org/abs/1609.08144 RNN sequence-to-sequence language translation — Chinese to English Sequence-to-sequence language translation All variants of encoder-decoder architecture share a common goal: encoding source inputs into fixed-length vector representations, and then feeding such vectors through a “narrow passage” to decode into a target output. The narrow passage forces the network to pick and abstract a small number of important features and builds the connection between a source and a target.
- 80. © Copyright Project10x | Confidential Example: Input: State Sen. Stewart Greenleaf discusses his proposed human trafficking bill at Calvery BapKst Church in Willow Grove Thursday night. Output: Stewart Greenleaf discusses his human trafficking bill. 80 Sentence compression with LSTMs Source: Lukasz Kaiser, Google Brain Deep learning for abstractive text summarization • If we cast the summarization task as a sequence-to-sequence neural machine translation problem, the models, trained on a large amount of data, learn the alignments between the input text and the target summary through an attention encoder-decoder paradigm. • The encoder is a recursive neural network (RNN) with long-short term memory (LSTM) that reads one token at time from the input source and returns a fixed-size vector representing the input text. • The decoder is another RNN that generates words for the summary and it is conditioned by the vector representation returned by the first network. • Also, we can increase summary quality by integrating prior relational semantic knowledge into RNNs in order to learn jointly word and knowledge embeddings by exploiting knowledge bases and lexical thesaurus.
- 82. © Copyright Project10x | Confidential • Training data — (Hi) RNN summarizers have the most extensive data requirements that include large language models (such as word2vec and skip-thoughts) for the vectorization/embedding step, a large sampling of training documents, and potentially other sources of prior knowledge (e.g., parts of speech, summary rhetoric models, and domain knowledge) for scoring and select steps. Depending on choice of algorithm(s), training documents may also need corresponding summaries. • Domain expertise — (Low) RNN summarizers generally demand less domain specific expertise or hand-crafted linguistic features to develop. Abstractive summarization architectures exist that combine RNNs and probabilistic models to cast the summarization task as a neural machine translation problem, where the models, trained on a large amount of data, learn the alignments between the input text and the target summary through an attention encoder-decoder paradigm enhanced with prior knowledge, such as linguistic features. • Computational cost — (Hi-to-very hi) RNNs require large amounts of preprocessing, and a large (post-training) static shared global state. Computations are best done on a GPU configuration. • Interpretability — (Low) RNN summarizers do not provide simple answers to the why of sentence selection and summary generation. Intermediate embeddings (and internal states) are not easily understandable in a global sense. 82 Recursive neural network summarization considerations The tradeoffs in computational cost and interpretability for different summarization systems Heuristics LDA RNN Interpretability ComputationalCost The tradeoffs in training data and domain expertise required for different summarization systems Heuristics LDA RNN Domain Expertise TrainingData
- 83. © Copyright Project10x | Confidential Symbolic methods • Declarative languages (Logic) • Imperative languages C, C++, Java, etc. • Hybrid languages (Prolog) • Rules — theorem provers, expert systems • Frames — case-based reasoning, model-based reasoning • Semantic networks, ontologies • Facts, propositions Symbolic methods can find information by inference, can explain answer Non-Symbolic methods • Neural networks — knowledge encoded in the weights of the neural network, for embeddings, thought vectors • Genetic algorithms • graphical models — baysean reasoning • Support vectors Neural KR is mainly about perception, issue is lack of common sense (there is a lot of inference involved in everyday human reasoning Knowledge Representation and Reasoning Knowledge representation and reasoning is: • What any agent—human, animal, electronic, mechanical—needs to know to behave intelligently • What computational mechanisms allow this knowledge to be manipulated? 83
- 85. Natural language generation (NLG) is the process by which thought is rendered into language. 85 David McDonald, Brandeis University
- 86. © Copyright Project10x | Confidential SUMMARY 86 Natural language generation (NLG) is the process by which thought is rendered into language. Computers are learning to “speak our language” in multiple ways, for example: data-to- language, text-to-language, vision-to-language, sound-to- language, and interaction-to-language. The purpose of this research deck is to introduce the application of AI techniques to the automatic generation of natural language. This research deck is divided into seven sections as follows: • Natural language generation — AI for human communication is about recognizing, parsing, understanding, and generating natural language. NLG converts some kind of data into human language. Most often this means generating text from structured data. However, the current state of play is broader. To set the stage, we identify four broad classes of AI for language generation with examples. • Commercial applications of data-to-text NLG — The most common commercial applications of NLG relate to article writing, business intelligence and analytics, and enhanced understanding of big data. In this section we provide examples ranging from simple data to text rendition to more insightful reporting based on a deeper understanding of the data, audience, and use case. • How data-to-text natural language generation works — This section overviews the process by which data is ingested and analyzed to determine facts; then facts get reasoned over to infer a conceptual outline and a communication plan; and an intelligent narrative is generated from the facts and the plan.
- 87. © Copyright Project10x | Confidential SUMMARY • Symbolic and statistical approaches to NLG — Historically, there are two broad technical approaches to NLG—symbolic reasoning and statistical learning: - Symbolic approaches apply classical AI and involve hand- crafted lexicons, knowledge, logic, and rules-based reasoning. We overview the architecture most commonly used. - Statistical learning approaches to NLG have emerged in recent years. They involve machine learning, deep learning, and probabilistic reasoning, and incorporate techniques being developed for computer vision, speech recognition and synthesis, gaming, and robotics. • NLG futures — We outline some possible developments of language generation technology, applications, and markets: - The concept of natural language is evolving. The direction of AI for NLG is to encompass visual language and conversational interaction as well as text. - The direction for AI system architecture is from hand- crafted knowledge and rules-based symbolic systems, and statistical learning and probabilistic inferencing systems, to contextual adaption systems that surpass limitations of earlier AI waves. New capabilities will include explainable AI, embedded continuous machine learning, automatic generation of whole-system causal models, and human- machine symbiosis. - New AI hardware will provide 100X to 1000X increases in computational power. 87
- 89. © Copyright Project10x | Confidential 1. Natural language generation (NLG) 2. Commercial applications of data-to-text NLG 3. How data-to-text NLG works 4. Symbolic and statistical approaches to NLG 5. NLG providers 89 TOPICS
- 91. Natural language generation (NLG) is the conversion of some kind of data into human language. 91
- 93. © Copyright Project10x | Confidential Data-to-text applications analyze and convert incoming (non-linguistic) data into a generated language. One way is by filling gaps in a predefined template text. Examples of this sort of "robo journalism" include: • Sports reports, such as soccer, baseball, basketball • Virtual ‘newspapers’ from sensor data • Textual descriptions of the day-to-day lives of birds based on satellite data • Weather reports • Financial reports such as earnings reports • Summaries of patient information in clinical contexts • Interactive information about cultural artifacts, for example in a museum context • Text intended to persuade or motivate behavior modification. 93 Data-to-language generation
- 94. © Copyright Project10x | Confidential Text-to-text applications take existing texts as their input, then automatically produce a new, coherent text or summary as output. Examples include: • Fusion and summarization of related sentences or texts to make them more concise • Simplification of complex texts, for example to make them more accessible for low-literacy readers • Automatic spelling, grammar and text correction • Automatic generation of peer reviews for scientific papers • Generation of paraphrases of input sentences • Atomatic generation of questions, for educational and other purposes. 94 Text-to-language generation
- 95. © Copyright Project10x | Confidential Vision-to-text applications convert incoming visual data from computer vision into a generated text descriptions or answers to questions. Examples include: • Automatic captions for photographs • Automatic scene descriptions from video • Automatic generation of answers to questions based on understanding and interpretation of a diagram. 95 Vision-to-language generation
- 98. © Copyright Project10x | Confidential Associated Press 1. Content determination: Deciding which information to include in the text under construction, 2. Text structuring: Determining in which order information will be presented in the text, 3. Sentence aggregation: Deciding which information to present in individual sentences, 4. Lexicalization: Finding the right words and phrases to express information, 5. Referring expression generation: Selecting the words and phrases to identify domain objects, 6. Linguistic realization: Combining all words and phrases into well-formed sentences. 98 Source: Automated Insights (Wordsmith) Article writing Associated Press
- 99. © Copyright Project10x | Confidential Associated Press • The Automated Insights Wordsmith platform uses natural language generation to transform raw fantasy football data into draft reports, match previews, and match recaps. The platform generates millions of stories each week, essentially giving every fantasy owner a personalized sports reporter writing about their team. • Accounting for the average number of unique readers per week and the average number of minutes per visit, Yahoo! has added over 100 years of incremental audience engagement by using NLG. • Yahoo!’s fantasy football content offers users a rare mix of personalization, insight, and wit—a combination that users might not expect from an algorithm. This form of social brand advocacy deepens the engagement of fans and their friends, which of course further expands Yahoo! Fantasy’s monetization potential. Leveraging the power of automation and personalization, NLG helps Yahoo! build success one user at a time. 99 Source: Automated Insights (Wordsmith) Article writing
- 100. © Copyright Project10x | Confidential 100 Source: NarraKve Science Automatic generation of language based on known facts Quarter Product Sales Q1 ID_0075 2,500,000$,,,,,,, Q2 ID_0075 2,300,000$,,,,,,, Q3 ID_0075 2,100,000$,,,,,,, Q4 ID_0075 1,900,000$,,,,,,, Q1 ID_0078 1,700,000$,,,,,,, Q2 ID_0078 1,800,000$,,,,,,, Q3 ID_0078 1,800,000$,,,,,,, Q4 ID_0078 1,850,000$,,,,,,, ID Name ID_0075 The*overly*large*widget ID_0078 The*small*light*widget Time Metric En3ty “Sales of the overly large widget have been on the decline over the last year.” Name Source: NarraKve Science Basic NLG
- 101. © Copyright Project10x | Confidential Giving people advice instead of data 101 Risk Company PerformanceAsset Growth Market Data Data about product flowing through stores Inventory Targets Sales Data Inventory Loss Store Demographics Information and advice you can act on Although the opportunity to reduce loss is the highest for Self-Service Cookies, concentraGng on European Heritage Bread may have greater impact overall, as it consistently has the higher sales. Source: NarraKve Science Transforming facts into advice
- 102. © Copyright Project10x | Confidential Giving people advice instead of data 102 Data on the quality of our water and beaches Wave Height Temperature Time and Date Turbidity Beach&Name Timestamp Water&Temperature Turbidity Transducer&Depth Wave&Height Wave&PeriodBattery&Life Measurement&ID Montrose(Beach 8/30/13(8:00 20.3 1.18 0.891 0.08 3 9.4 MontroseBeach201308300800 Ohio(Street(Beach 5/26/16(13:00 14.4 1.23 0.111 4 12.4 OhioStreetBeach201605261300 Calumet(Beach 9/3/13(16:00 23.2 3.63 1.201 0.174 6 9.4 CalumetBeach201309031600 Calumet(Beach 5/28/14(12:00 16.2 1.26 1.514 0.147 4 11.7 CalumetBeach201405281200 Montrose(Beach 5/28/14(12:00 14.4 3.36 1.388 0.298 4 11.9 MontroseBeach201405281200 Montrose(Beach 5/28/14(13:00 14.5 2.72 1.395 0.306 3 11.9 MontroseBeach201405281300 Calumet(Beach 5/28/14(13:00 16.3 1.28 1.524 0.162 4 11.7 CalumetBeach201405281300 Montrose(Beach 5/28/14(14:00 14.8 2.97 1.386 0.328 3 11.9 MontroseBeach201405281400 Calumet(Beach 5/28/14(14:00 16.5 1.32 1.537 0.185 4 11.7 CalumetBeach201405281400 Calumet(Beach 5/28/14(15:00 16.8 1.31 1.568 0.196 4 11.7 CalumetBeach201405281500 Montrose(Beach 5/28/14(15:00 14.5 4.3 1.377 0.328 3 11.9 MontroseBeach201405281500 Calumet(Beach 5/28/14(16:00 17.1 1.37 1.52 0.194 4 11.7 CalumetBeach201405281600 Montrose(Beach 5/28/14(16:00 14.4 4.87 1.366 0.341 3 11.9 MontroseBeach201405281600 Calumet(Beach 5/28/14(17:00 17.2 1.48 1.525 0.203 4 11.7 CalumetBeach201405281700 Montrose(Beach 5/28/14(17:00 14.1 5.06 1.382 0.34 4 11.9 MontroseBeach201405281700 Montrose(Beach 5/28/14(18:00 14.2 5.76 1.415 0.356 3 11.9 MontroseBeach201405281800 Calumet(Beach 5/28/14(18:00 17.1 1.8 1.501 0.188 4 11.7 CalumetBeach201405281800 Calumet(Beach 5/28/14(19:00 17 1.82 1.487 0.194 4 11.7 CalumetBeach201405281900 Montrose(Beach 5/28/14(19:00 14.2 6.32 1.386 0.346 3 11.9 MontroseBeach201405281900 Montrose(Beach 5/28/14(20:00 14.4 6.89 1.401 0.38 4 11.9 MontroseBeach201405282000 Calumet(Beach 5/28/14(20:00 17 1.83 1.488 0.196 4 11.7 CalumetBeach201405282000 Montrose(Beach 5/28/14(21:00 14.5 7.11 1.374 0.361 5 11.9 MontroseBeach201405282100 Calumet(Beach 5/28/14(21:00 16.8 1.9 1.494 0.181 4 11.7 CalumetBeach201405282100 Montrose(Beach 5/28/14(22:00 14.5 6.88 1.413 0.345 4 11.9 MontroseBeach201405282200 Calumet(Beach 5/28/14(22:00 16.7 1.83 1.467 0.18 4 11.7 CalumetBeach201405282200 Montrose(Beach 5/28/14(23:00 14.3 7.32 1.406 0.331 4 11.9 MontroseBeach201405282300 Calumet(Beach 5/28/14(23:00 16.5 1.69 1.548 0.177 4 11.7 CalumetBeach201405282300 Calumet(Beach 5/29/14(1:00 16.3 1.62 1.519 0.159 4 11.7 CalumetBeach201405290100 Montrose(Beach 5/29/14(1:00 14.2 7.18 1.46 0.305 4 11.9 MontroseBeach201405290100 Montrose(Beach 5/29/14(2:00 14.2 6.35 1.45 0.321 3 11.9 MontroseBeach201405290200 Calumet(Beach 5/29/14(2:00 16.2 1.57 1.535 0.154 4 11.7 CalumetBeach201405290200 Calumet(Beach 5/29/14(3:00 16.1 1.8 1.557 0.163 4 11.7 CalumetBeach201405290300 Montrose(Beach 5/29/14(3:00 14.1 6.78 1.468 0.285 4 11.8 MontroseBeach201405290300 Calumet(Beach 5/29/14(4:00 16.1 1.82 1.507 0.156 4 11.7 CalumetBeach201405290400 Montrose(Beach 5/29/14(4:00 14.1 6.27 1.456 0.306 3 11.8 MontroseBeach201405290400 Montrose(Beach 5/29/14(5:00 14 5.63 1.421 0.282 3 11.8 MontroseBeach201405290500 Beach&Name Timestamp Water&Temperature Turbidity Transducer&Depth Wave&Height Wave&PeriodBattery&Life Measurement&ID Montrose(Beach 8/30/13(8:00 20.3 1.18 0.891 0.08 3 9.4 MontroseBeach201308300800 Ohio(Street(Beach 5/26/16(13:00 14.4 1.23 0.111 4 12.4 OhioStreetBeach201605261300 Calumet(Beach 9/3/13(16:00 23.2 3.63 1.201 0.174 6 9.4 CalumetBeach201309031600 Calumet(Beach 5/28/14(12:00 16.2 1.26 1.514 0.147 4 11.7 CalumetBeach201405281200 Montrose(Beach 5/28/14(12:00 14.4 3.36 1.388 0.298 4 11.9 MontroseBeach201405281200 Montrose(Beach 5/28/14(13:00 14.5 2.72 1.395 0.306 3 11.9 MontroseBeach201405281300 Calumet(Beach 5/28/14(13:00 16.3 1.28 1.524 0.162 4 11.7 CalumetBeach201405281300 Montrose(Beach 5/28/14(14:00 14.8 2.97 1.386 0.328 3 11.9 MontroseBeach201405281400 Calumet(Beach 5/28/14(14:00 16.5 1.32 1.537 0.185 4 11.7 CalumetBeach201405281400 Calumet(Beach 5/28/14(15:00 16.8 1.31 1.568 0.196 4 11.7 CalumetBeach201405281500 Montrose(Beach 5/28/14(15:00 14.5 4.3 1.377 0.328 3 11.9 MontroseBeach201405281500 Calumet(Beach 5/28/14(16:00 17.1 1.37 1.52 0.194 4 11.7 CalumetBeach201405281600 Montrose(Beach 5/28/14(16:00 14.4 4.87 1.366 0.341 3 11.9 MontroseBeach201405281600 Calumet(Beach 5/28/14(17:00 17.2 1.48 1.525 0.203 4 11.7 CalumetBeach201405281700 Montrose(Beach 5/28/14(17:00 14.1 5.06 1.382 0.34 4 11.9 MontroseBeach201405281700 Montrose(Beach 5/28/14(18:00 14.2 5.76 1.415 0.356 3 11.9 MontroseBeach201405281800 Calumet(Beach 5/28/14(18:00 17.1 1.8 1.501 0.188 4 11.7 CalumetBeach201405281800 Calumet(Beach 5/28/14(19:00 17 1.82 1.487 0.194 4 11.7 CalumetBeach201405281900 Montrose(Beach 5/28/14(19:00 14.2 6.32 1.386 0.346 3 11.9 MontroseBeach201405281900 Montrose(Beach 5/28/14(20:00 14.4 6.89 1.401 0.38 4 11.9 MontroseBeach201405282000 Calumet(Beach 5/28/14(20:00 17 1.83 1.488 0.196 4 11.7 CalumetBeach201405282000 Montrose(Beach 5/28/14(21:00 14.5 7.11 1.374 0.361 5 11.9 MontroseBeach201405282100 Calumet(Beach 5/28/14(21:00 16.8 1.9 1.494 0.181 4 11.7 CalumetBeach201405282100 Montrose(Beach 5/28/14(22:00 14.5 6.88 1.413 0.345 4 11.9 MontroseBeach201405282200 Calumet(Beach 5/28/14(22:00 16.7 1.83 1.467 0.18 4 11.7 CalumetBeach201405282200 Montrose(Beach 5/28/14(23:00 14.3 7.32 1.406 0.331 4 11.9 MontroseBeach201405282300 Calumet(Beach 5/28/14(23:00 16.5 1.69 1.548 0.177 4 11.7 CalumetBeach201405282300 Calumet(Beach 5/29/14(1:00 16.3 1.62 1.519 0.159 4 11.7 CalumetBeach201405290100 Montrose(Beach 5/29/14(1:00 14.2 7.18 1.46 0.305 4 11.9 MontroseBeach201405290100 Montrose(Beach 5/29/14(2:00 14.2 6.35 1.45 0.321 3 11.9 MontroseBeach201405290200 Calumet(Beach 5/29/14(2:00 16.2 1.57 1.535 0.154 4 11.7 CalumetBeach201405290200 Calumet(Beach 5/29/14(3:00 16.1 1.8 1.557 0.163 4 11.7 CalumetBeach201405290300 Montrose(Beach 5/29/14(3:00 14.1 6.78 1.468 0.285 4 11.8 MontroseBeach201405290300 Calumet(Beach 5/29/14(4:00 16.1 1.82 1.507 0.156 4 11.7 CalumetBeach201405290400 Montrose(Beach 5/29/14(4:00 14.1 6.27 1.456 0.306 3 11.8 MontroseBeach201405290400 Montrose(Beach 5/29/14(5:00 14 5.63 1.421 0.282 3 11.8 MontroseBeach201405290500 Chicago Beaches: July 16, 2016 Best Bet For the week ending July 16, 2016, 63rd Street Beach was the cleanest beach in Chicago, as measured by the cloudiness of the water (average hourly turbidity raGng of 0.64). Not only did the beach have the cleanest water throughout the week, but also measured the cleanest out of all beach waters at any Gme (NTU 0.13), which was achieved on Wednesday around 9 PM. Calumet Beach was the calmest throughout the enGre week, with an average wave height of 0.12 meters. This beach also happened to be the warmest, with an average temperature of 19.1º C. Avoid Ohio Street Beach was the dirGest beach in Chicago, as measured by the overall turbidity of the water (average NTU 1.22). Ohio Street Beach did not record the highest turbidity raGng of the week, however. Rainbow Beach saw a reading of 6.57 NTU, which was recorded Wednesday around 1 PM. In fact, it has recorded the highest turbidity each week for the last four weeks. Ohio was also the coldest of all the beaches, with an average hourly temperature of 16.0º C. Beach goers would be advised to visit Oak Street beach that had a be/er than average cleanliness raGng this week. Understandable information on beach safety For the week ending July 16, 2016, 63rd Street Beach was the cleanest beach in Chicago, as measured by the cloudiness of the water… Ohio Street Beach was the dirGest beach in Chicago… Beach goers would be advised to visit Oak Street beach that had a be/er than average cleanliness raGng… Source: NarraKve Science Transforming facts into advice
- 105. © Copyright Project10x | Confidential 105 Source: NarraKve Science Advanced natural language generation summarizes, explains, and delivers actionable insights. Source: NarraKve Science Account Execu3ve Sales Report Helen Crane’s performance and progress during the last quarter of 2016 has been excepGonal. She was the top performer, ranking extremely well within her team. This quarter, Helen closed $191,243 in sales. She had 93 deals with an average size of $2,056. Along both dimensions, she was in the 98th percenGle within her team. Helen’s largest sale was also near the top at $8,333. Helen’s sales total increased by $10,555 (about 6%) from the third to last quarter of 2016. This places her near the top in terms of overall improvement within her team. It is difficult to assess her current Pipeline in that the data associated with this metric seems to be faulty in general. extremely well excepGonal near the top performance and progress Sales Report overall improvement within her team It is difficult to assess her current Pipeline… the data seems to be faulty in general. Actionable performance summary in context
- 108. © Copyright Project10x | Confidential The sections of this research deck generally follow the order of the Fast Forward Labs Summarization report. Also, we include slides that provide tutorial information, drill-down on technical topics, and other material that expands upon themes of the report. ▪ Automated summarization — This section introduces summarization, genres of summary, basic concepts of summarization systems, and the spectrum of text summarization techniques ▪ Automated summarization using statistical heuristics for sentence extraction — This section summarizes the first POC discussed in the FFL report. ▪ Automated summarization using unstructured machine learning to model topics — This section overviews the topic modeling approach in POC-2. It then drills down to provide additional information about topic modeling, document-term matrix, semantic relatedness and TF•IDF, probabilistic topic models, convolutional neural networks, topic modeling algorithms, latent semantic analysis, latent Dirichlet allocation, advanced topic modeling techniques, and topic-modeled multi-document summarization. ▪ Automated summarization using recurrent neural networks to predict sentences — This section overviews three different POCs that utilize word and sentence embeddings and different types of neural networks to extract or generate summary sentences. It then drills down to discuss semantic hashing, word embeddings, skip-thoughts, feedforward networks, recurrent neural networks, long short term memory, sequence-to-sequence language translation, deep learning for abstractive text summarization, and prior semantic knowledge. ▪ NLP technology providers — Coverage not part of this deck. Some use cases for natural language generation in financial services Who’s using NLG Applicable Use Cases Wealth Managers To review and analyze portfolio data, determine meaningful metrics, and to generate personalized reports for customers on fund performance. International Banks To improve the regulatory compliance processes by monitoring all electronic communications of employees for indicators of non-compliant activities. Financial Information & Affiliated Services To generate content such as executive bios, company descriptions, fill out the blanks and related information, and generate news or press releases. Investment & Fund Managers To explain market performance and drivers (both back office and client-facing) in written reports. Some are even using this software for prescriptive analysis, explaining what to do in response to market changes. Hedge Fund Managers To automate the process of generating compliance notes. Higher Levels of Accuracy Increased Capacity Fast Implementation Time Savings Improved Personalization Increased Customer Satisfaction Benefits:
- 113. © Copyright Project10x | Confidential First, determine communication purpose and requirements 113 CONTEXT DOMAIN & TOPIC EXPERTISE AUDIENCE LINGUISTIC KNOWLEDGE CONTENT & DATA Document Planning Micro Planning Surface RealizaKon Delivery InteracKon COMMUNICATION PLANNING Learning COMMUNICATION INTENT CONSIDERATIONS: • Communication purpose • Scope • Constraints • Key questions • Answer form(s) • Hypotheses • Strategy • Data exploration • Evidence • Inference • Simulation & testing • Conclusions • Messages • Styling • Delivery • Interaction • Confidence NATURAL LANGUAGE GENERATION
- 121. SYMBOLIC NLG 121
- 122. © Copyright Project10x | Confidential 1. Morphological Level: Morphemes are the smallest units of meaning within words and this level deals with morphemes in their role as the parts that make up word. 2. Lexical Level: This level of speech analysis examines how the parts of words (morphemes) combine to make words and how slight differences can dramatically change the meaning of the final word. 3. Syntactic Level: This level focuses on text at the sentence level. Syntax revolves around the idea that in most languages the meaning of a sentence is dependent on word order and dependency. 4. Semantic Level: Semantics focuses on how the context of words within a sentence helps determine the meaning of words on an individual level. 5. Discourse Level: How sentences relate to one another. Sentence order and arrangement can affect the meaning of the sentences. 6. Pragmatic Level: Bases meaning of words or sentences on situational awareness and world knowledge. Basically, what meaning is most likely and would make the most sense. 122 How symbolic NLP interprets language (six level stack)
- 123. © Copyright Project10x | Confidential 1. Content determination: Deciding which information to include in the text under construction, 2. Text/document structuring: Determining in which order information will be presented in the text, 3. Sentence aggregation: Deciding which information to present in individual sentences, 4. Lexicalization: Finding the right words and phrases to express information, 5. Referring expression generation: Selecting the words and phrases to identify domain objects, 6. Linguistic realization: Combining all words and phrases into well-formed sentences. 123 Source: Reiter and Dale Natural language generation tasks
- 124. © Copyright Project10x | Confidential Natural language generation tasks 124 DOCUMENT PLANNING Content determination Decides what information will appear in the output text. This depends on what the communication goal is, who the audience is, what sort of input information is available in the first place and other constraints such as allowed text length. Text/document structuring Decides how chunks of content should be grouped in a document, how to relate these groups to each other and in what order they should appear. For instance, to describe last month's weather, one might talk first about temperature, then rainfall. Alternatively, one might start off generally talking about the weather and then provide specific weather events that occurred during the month. MICRO-PLANNING Sentence aggregation Decides how the structures created by document planning should map onto linguistic structures such as sentences and paragraphs. For instance, two ideas can be expressed in two sentences or in one: The month was cooler than average. The month was drier than average. vs. The month was cooler and drier than average. Lexicalization Decides what specific words should be used to express the content. For example, choosing from a lexiconthe actual nouns, verbs, adjectives and adverbs to appear in the text. Also, choosing particular syntactic structures. For example, one could say 'the car owned by Mary' or the phrase 'Mary's car'. Refering expression generation Decides which expressions should be used to refer to entities (both concrete and abstract); it is possible to refer to the same entity in many ways. For example, the month Barack Obama was first elected President of the Unted States can be referred to as: • November 2008 • November • The month Obama was elected • it SURFACE REALIZATION Linguistic realization Uses grammar rules (about morphology and syntax) to convert abstract representations of sentences into actual text. Realization techniques include template completion, hand-coded grammar-based realization, and filtering using probabilistic grammar trained on a large corpora of candidate text passages. Structure realization Converts abstract structures such as paragraphs and sentences into mark-up symbols which are used to display the text.
- 125. © Copyright Project10x | Confidential Rule-based modular pipeline architecture for natural language generation 125 -1- Document Planning -2- Micro-planning Text Content Determination, Text Structuring Sentence Aggregation, Lexicalization, Referring Expression Generation Linguistic Realization Communication Goals Knowledge Source -3- Surface Realization Text Plan Sentence Plan Source: Reiter and Dale
- 126. © Copyright Project10x | Confidential 126 VERTICAL RULESET CLIENT RULESET CORE NLG ENGINE CORE ENGINE RULESET Source: Arria NLG rulesets • Core ruleset — general purpose rules used in almost every application of the NLG engine. These capture knowledge about data processing and linguistic communication in general, independent of the particular domain of application. • Vertical ruleset — rules encoding knowledge about the specific industry vertical or domain in which the NLG engine is being used. Industry vertical rulesets are constantly being refined via ongoing development, embodying knowledge about data processing and linguistic communication, which is common to different clients in the same vertical. • Client ruleset — rules that are specific to the client for whom the NLG engine is being configured. These rules embody the particular expertise in data processing and linguistic communication that are unique to a client application.
- 127. © Copyright Project10x | Confidential 127 Source: NarraKve Science Example architecture for realtime data storytelling The Arria NLG Engine combines data analytics and computational linguistics, enabling it to convert large and diverse datasets into meaningful natural language narratives. Source: Arria DATA ANALYSIS Analysis and Interpretation RAW DATA Information Delivery MESSAGES SENTENCE PLANS FACTS DOCUMENT PLAN SURFACE TEXT DOCUMENT PLANNING SURFACE REALISATION DATA INTERPRETATION MICRO- PLANNING DATA ANALYSIS processes the data to extract the key facts that it contains DATA INTERPRETATION makes sense of the data, particularly from the point of view of what information can be communicated DOCUMENT PLANNING takes the messages derived from the data and works out how to best structure the information they contain into a narrative MICROPLANNING works out how to package the information into sentences to maximise fluency and coherence SURFACE REALISATION ensures that the meanings expressed in the sentences are conveyed using correct grammar, word choice, morphology and punctuation DATA can be ingested from a wide variety of data sources, both structured and unstructured NARRATIVE can be output in a variety of formats (HTML, PDF, Word, etc.), combined with graphics as appropriate, or delivered as speech
- 128. STATISTICAL NLG
- 130. © Copyright Project10x | Confidential Summarization, and algorithms to make text quantifiable, allow us to derive insights from Large amounts of unstructured text data. Unstructured text has been slower to yield to the kinds of analysis that many businesses are starting to take for granted. We are beginning to gain the ability to do remarkable things with unstructured text data. First, the use of neural networks and deep learning for text offers the ability to build models that go beyond just counting words to actually representing the concepts and meaning in text quantitatively. These examples start simple and eventually demonstrate the breakthrough capabilities realized by the application of sentence embedding and recurrent neural networks to capturing the semantic meaning of text. Machine Learning Machine Learning is a type of Artificial Intelligence that provides computers with the ability to learn without being explicitly programmed. Machine Learning Algorithm Learned Model Data Prediction Labeled Data Training Prediction Provides various techniques that can learn from and make predictions on data 130 Source: NarraKve Science Machine learning Source: Lukas Masuch
- 131. © Copyright Project10x | Confidential Summarization, and algorithms to make text quantifiable, allow us to derive insights from Large amounts of unstructured text data. Unstructured text has been slower to yield to the kinds of analysis that many businesses are starting to take for granted. We are beginning to gain the ability to do remarkable things with unstructured text data. First, the use of neural networks and deep learning for text offers the ability to build models that go beyond just counting words to actually representing the concepts and meaning in text quantitatively. These examples start simple and eventually demonstrate the breakthrough capabilities realized by the application of sentence embedding and recurrent neural networks to capturing the semantic meaning of text. Deep Learning Architecture A deep neural network consists of a hierarchy of layers, whereby each layer transforms the input data into more abstract representations (e.g. edge -> nose -> face). The output layer combines those features to make predictions. 131 Source: NarraKve Science Deep learning Source: Lukas Masuch