
Recommandé
Contenu connexe
Tendances
Tendances (20)
Similaire à Chomsky hierarchy
Similaire à Chomsky hierarchy (20)
Dernier
Dernier (20)
Chomsky hierarchy
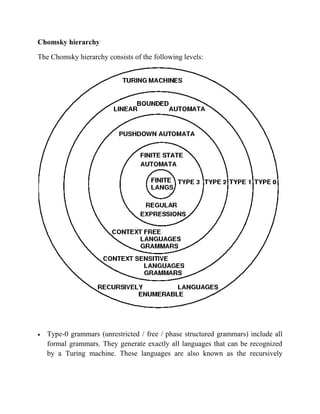
- 1. Chomsky hierarchy The Chomsky hierarchy consists of the following levels: Type-0 grammars (unrestricted / free / phase structured grammars) include all formal grammars. They generate exactly all languages that can be recognized by a Turing machine. These languages are also known as the recursively
- 2. enumerable languages. Note that this is different from the recursive languages which can be decided by an always-halting Turing machine. Type-1 grammars (context-sensitive grammars) generate the context-sensitive languages. These grammars have rules of the form A β → β with a non terminal A &, & β strings of terminals and non-terminals. The strings and β may be empty, but must be nonempty. The rule S→ is allowed if S does not appear on the right side of any rule. The languages described by these grammars are exactly all languages that can be recognized by a linear bounded automaton (a nondeterministic Turing machine whose tape is bounded by a constant times the length of the input.) Type-2 grammars (context-free grammars) generate the context-free languages. These are defined by rules of the form A → with a non-terminal A and a string of terminals and non-terminals. These languages are exactly all languages that can be recognized by a non-deterministic pushdown automaton. Context- free languages – or rather the subset of deterministic context-free language – are the theoretical basis for the phrase structure of most programming languages. Type-3 grammars (regular grammars) generate the regular languages. Such a grammar restricts its rules to a single non-terminal on the left-hand side and a right-hand side consisting of a single terminal, possibly followed by a single non-terminal (right regular). Alternatively, the right-hand side of the grammar can consist of a single terminal, possibly preceded by a single non-terminal (left regular); these generate the same languages – however, if left-regular rules and right-regular rules are combined, the language need no longer be regular. The rule S→ is allowed here also if S does not appear on the right side of any rule. These languages are exactly all languages that can be decided by a finite state automaton. Additionally, this family of formal languages can be obtained by regular expressions. Regular languages are commonly used to define search patterns and the lexical structure of programming languages. Grammar Language Automation Production rules (Constraints) Type-0 Recursively enumerable Turing machine → β (no restrictions)
- 3. Type-1 Context-sensitive Linear-bounded non-deterministic Turing machine. A β → β Type-2 Context-free Non-deterministic pushdown automaton A → Type-3 Regular Finite state automaton A → a and A → aB Classification of languages (Chomsky hierarchy): Linear Grammar: A linear grammar is a grammar in which at most one variable can occur on the right side of any production, without restriction on the position of this variable. A grammar G = (V, T, S, P) is said to be right-linear (left-linear) if all productions are of the form A → xB (A → Bx) or A → x,
- 4. where A, B V and x T*. A regular grammar (or type-3 grammar) is one that is either right-linear or left-linear. A regular grammar is always linear, but not all linear grammars are regular. All context free grammars are not linear Eg: Consider the grammar S → a S b | SS | . This grammar is context free, but not linear and it can be defined as: L(G) = {w {a, b}∗ : na(w) = nb(w) and na(v) ≥ nb(v),where v is any prefix of w}. Note: L is the set of all properly nested parenthesis structures for the common programming languages. CFL: In formal language theory, a context-free language (CFL) is a language generated by some context-free grammar (CFG). Different CF grammars can generate the same CF language, or conversely, a given CF language can be generated by different CF grammars. The set of all context-free languages is identical to the set of languages accepted by pushdown automata, which makes these languages amenable to parsing. Context-free languages have many applications in programming languages; for example, the language of all properly matched parentheses is generated by the grammar S→SS | (S) | . Also, most arithmetic expressions are generated by context-free grammars. Unambiguous CFLs are a proper subset of all CFLs: there are inherently ambiguous CFLs (for which no unambiguous grammar can be written, i.e. all the grammars existing for the language are ambiguous). To prove that a given language is not context-free, one may employ the pumping lemma for context-free languages or a number of other methods, such as Ogden's lemma or Parikh's theorem. DCFL: In formal language theory, deterministic context-free languages (DCFL) are a proper subset of context-free languages. They are the context-free languages that can be accepted by a deterministic pushdown automaton. DCFLs are always unambiguous, meaning that they admit an unambiguous grammar, but any (non- empty) DCFL also admits ambiguous grammars. There are non-deterministic unambiguous CFLs, so DCFLs form a proper subset of unambiguous CFLs.
- 5. DCFLs are of great practical interest, as they can be parsed in linear time, and various restricted forms of DCFGs admit simple practical parsers. Unambiguous grammars do not always generate a DCFL. For example, the language of even-length palindromes on the alphabet of 0 and 1 has the unambiguous context-free grammar S → 0S0 | 1S1 | ε. An arbitrary string of this language cannot be parsed without reading its entire letters first which means that a pushdown automaton has to try alternative state transitions to accommodate for the different possible lengths of a semi-parsed string. Deterministic context-free languages can be recognized by a deterministic Turing machine in polynomial time and O (log2 n) space. The set of deterministic context-free languages is not closed under union but is closed under complement. The complexity of the program and execution time of a deterministic pushdown automaton is vastly less than that of a nondeterministic one. In the naive implementation, the latter must make copies of the stack every time a nondeterministic step occurs. The best known algorithm to test membership in any context-free language is Valiant's algorithm, taking O (n2.378 ) time, where n is the length of the string. On the other hand, deterministic context-free languages can be accepted in O (n) time by a LR (k) parser. This is very important for computer language translation because many computer languages belong to this class of languages. Parsing: Given a string w of terminals, we want to know whether or not w is in L(G). The term parsing describes finding a sequence of productions by which a w L(G) is derived. Exhaustive Search Parsing: The Exhaustive search parsing, also known as brute force parsing is a form of top-down parsing. It constructs a derivation tree from the root down. One can apply leftmost (or rightmost) derivation on it. For every context-free grammar there exists an algorithm that parse any w L(G) in a number of steps proportional to |w|3 . Simple Grammars: A context-free grammar G = (V, T, S, P) is said to be a simple grammar or s-grammar if all its productions are of the form A → ax, where A V, a T, x V *, and any pair (A, a) occurs at most once in P. Note: the form A → ax is common to both Greibach normal form and s- grammar, but Greibach normal form does not put the restriction that the pair (A, a) occur at most once.
- 6. If G is an s-grammar, then any string w in L(G) can be parsed with an effort proportional to |w| {Linear time parsing – only for restricted grammar} A context-free grammar G is said to be ambiguous if there exists some w L(G) that has at least two distinct derivation trees. Alternatively, ambiguity implies the existence of two or more leftmost and rightmost derivations. If L is a context-free language for which there exists an unambiguous grammar, then L is said to be unambiguous. If every grammar that generates L is ambiguous, then the language is called inherently ambiguous. The language L = {an b n cm } ∪ {an b m cm }, with n and m nonnegative, is an inherently ambiguous context-free language. Deterministic pushdown automaton (DPDA) In automata theory, a deterministic pushdown automaton (DPDA or DPA) is a variation of the pushdown automaton. The DPDA accepts the deterministic context-free languages, a proper subset of context-free languages. Machine transitions are based on the current state and input symbol, and also the current topmost symbol of the stack. Symbols lower in the stack are not visible and have no immediate effect. Machine actions include pushing, popping, or replacing the stack top. A deterministic pushdown automaton has at most one legal transition for the same combination of input symbol, state, and top stack symbol. This is where it differs from the nondeterministic pushdown automaton. A (not necessarily deterministic) PDA M can be defined as a 7-tuple: M = (Q, Σ, Γ, δ, q0, z, F) Where: Q is a finite set of states Σ is a finite set of input symbols Γ is a finite set of stack symbols q0 Q is the start state z Γ is the starting stack symbol F ⊆ Q is the set of final states/accepting states δ is a transition function A pushdown automation M = (Q, Σ, Γ, δ, q0, z, F) is said to be deterministic if it satisfies the following condition(s), for every q Q, a Σ ∪ {λ} and b Γ δ (q, a, b) contains at most one element
- 7. if δ (q, λ, b) is not empty then (q, c, b) must be empty for every c Σ Not all context-free languages are deterministic. This makes the DPDA a strictly weaker device than the PDA. For example, the language of even-length palindromes on the alphabet of 0 and 1 has the context-free grammar S → 0S0 | 1S1 | ε. An arbitrary string of this language cannot be parsed without reading its entire letters first which means that a pushdown automaton has to try alternative state transitions to accommodate for the different possible lengths of a semi-parsed string . Determinism Vs Non-determinism: Deterministic Finite Automata (DFA) and Non-deterministic Finite Automata (NFA) have equivalent computational capabilities. I.e. for every NFA there is an equivalent DFA and vice versa.
- 8. Deterministic Linear Bounded Automata (DLBA) and Non-deterministic Linear Bounded Automata (NLBA) have equivalent computational capabilities. I.e. for every NLBA there is an equivalent DLBA and vice versa. Deterministic Turing Machine (DTM) and Non-deterministic Turing Machine (NTM) have the same computational capabilities. I.e. for every NTM there is an equivalent DTM and vice versa. However, the computational capabilities of Deterministic Push-Down Automata (DPDA) are less than that of Non-deterministic Push-Down Automata (NPDA). I.e. DPDA is a proper subset of NDPDA. Pumping Lemma In the theory of formal languages in computability theory, a pumping lemma or pumping argument states that, for a particular language to be a member of a language class, any sufficiently long string in the language contains a section, or sections, that can be removed, or repeated any number of times, with the resulting string remaining in that language. The proofs of these lemmas typically require counting arguments such as the pigeonhole principle. The two most important examples are the pumping lemma for regular languages and the pumping lemma for context-free languages. Ogden's lemma is a second, stronger pumping lemma for context-free languages. Pumping lemma for regular languages: For every regular language L, there exists a positive whole number p such that every string w L that has p characters or more can be broken down into three substrings xyz, where y is not the empty string and the total length of xy is at most p, and for every integer i ≥ 0 the string xyi z is also in L. Formal statement: Let L be a regular language. Then there exists an integer p ≥ 1 depending only on L such that every string w in L of length at least p (p is called the "pumping length") can be written as w = xyz (i.e., w can be divided into three substrings), satisfying the following conditions: |y| ≥ 1;
- 9. |xy| ≤ p For all i ≥ 0, xyi z L „y‟ is the substring that can be pumped (removed or repeated any number of times, and the resulting string is always in L We can observe that the idea of this theorem is essentially the pigeonhole principle: the principle that if we put more than n pigeons into n holes then there must be a hole with more than one pigeon in. Take the regular language L, and express it as a deterministic finite automaton with p states. Any string in L determines a path through the automaton; so any string with p or more characters must visit the same state twice, forming a loop. This looped part can be repeated any arbitrary number of times to produce other strings in L. The pumping lemma theorem is a negative theorem and is the necessary condition for a language to be regular but not sufficient. It means if a language satisfies Pumping Lemma then it may or may not be regular, but if a language is regular then it should satisfy Pumping Lemma. Also if a language violates Pumping Lemma, it is clear evidence to the fact that the language is not regular. Thus this theorem is used to prove that no-regularity of languages. Pumping lemma for context-free languages: The pumping lemma for context-free languages, also known as the Bar-Hillel lemma, is a lemma that gives a property shared by all context-free languages. Formal statement: If a language L is context-free, then there exists some integer p ≥ 1 such that every string s in L with |s| ≥ p (where p is a "pumping length") can be written as s = uvxyz with substrings u, v, x, y and z, such that 1. |vxy| ≤ p, 2. |vy| ≥ 1, and 3. u v n x y n z is in L for all n ≥ 0.
- 10. Myhill–Nerode theorem In the theory of formal languages, the Myhill–Nerode theorem provides a necessary and sufficient condition for a language to be regular. The theorem is named for John Myhill and Anil Nerode, who proved it at the University of Chicago in 1958. The thermo can also be used for DFA minimization. Chomsky normal form (CNF): In formal language theory, a context-free grammar is said to be in Chomsky normal form (named for Noam Chomsky) if all of its production rules are of the form: A → BC or A → a or S → Where A, B and C are nonterminals, „a‟ is a terminal, S is the start symbol and is the null string. Also, neither B nor C may be the start symbol, and the third production rule can only appear if is in L (G), namely, the language produced by the context-free grammar G. Every grammar in Chomsky normal form is context-free, and conversely, every context-free grammar can be transformed into an equivalent one which is in Chomsky normal form. Several algorithms for performing such a transformation are known. The drawback of these transformations is that they can lead to an undesirable bloat in grammar size. The size of a grammar is the sum of the sizes of its production rules, where the size of a rule is one plus the length of its right-hand side. Using |G| to denote the size of the original grammar G, the size blow-up in the worst case may range from |G|2 to 22|G| , depending on the transformation algorithm used. Chomsky reduced form: Another way to define the Chomsky normal form is: A formal grammar is in Chomsky reduced form if all of its production rules are of the form: A → BC or
- 11. A → a Where A, B and C are nonterminals, „a‟ is a terminal. When using this definition, B or C may be the start symbol. Only those context-free grammars which do not generate the empty string can be transformed into Chomsky reduced form. Converting a grammar to Chomsky Normal Form 1. Introduce : Introduce a new start variable, and a new rule where the previous is start variable. 2. Eliminate all rules: rules are rules of the form , where and , where is the CFG's variable alphabet. Remove every rule with on its right hand side (RHS). For each rule with in its RHS, add a set of new rules consisting of the different possible combinations of replaced or not replaced with . For example, examine the following grammar : has one rule. When the is removed, we get the following: Notice that we have to account for all possibilities of and so we actually end up adding 3 rules. 3. Eliminate all unit rules After all the rules have been removed, you can begin removing unit rules, or rules whose RHS contains one variable and no terminals (which is inconsistent with CNF).
- 12. To remove , where is a string of variables and terminals, add rule unless this is a unit rule which has already been removed. 4. Clean up the remaining rules that are not in Chomsky normal form. Replace with , where are new variables. If , replace in above rules with some new variable and add rule . Note: The key advantage is that in Chomsky Normal Form, every derivation of a string of n letters has exactly 2n − 1 steps. If a parse tree for a word string w is generated by a CNF and the parse tree has a path length of at most i, then the length of w is at most 2i -1. (Pf: apply mathematical induction) Greibach normal form:
- 13. In computer science and formal language theory, a context-free grammar is in Greibach normal form (GNF) if the right-hand sides of all production rules start with a terminal symbol, optionally followed by some variables. A non-strict form allows one exception to this format restriction for allowing the empty word (epsilon, ε) to be a member of the described language. The normal form was established by Sheila Greibach and it bears her name. More precisely, a context-free grammar is in Greibach normal form, if all production rules are of the form: A → aA1A2A3…An or S → Where A is a nonterminal symbol, „a‟ is a terminal symbol, A1A2A3…An is a (possibly empty) sequence of nonterminal symbols not including the start symbol, S is the start symbol, and ε is the empty word. Observe that the grammar does not have left recursions. Every context-free grammar can be transformed into an equivalent grammar in Greibach normal form. Various constructions exist. Some do not permit the second form of rule and cannot transform context-free grammars that can generate the empty word. For one such construction the size of the constructed grammar is O (n4 ) in the general case and O (n3 ) if no derivation of the original grammar consists of a single nonterminal symbol, where n is the size of the original grammar. This conversion can be used to prove that every context-free language can be accepted by a non-deterministic pushdown automaton. Given a grammar in GNF and a derivable string in the grammar with length n, any top-down parser will halt at depth n. Closure Properties of Context-Free languages: Union: Context-free languages are closed under Union operation. I.e. if L1 is context free and L2 is context free then L1∪L2 is context-free. Example: Language Grammer
- 14. L1 = {an b n | n>=0} S1→aS1b |λ L2 = {w w R |w {a, b}*} S2 →aS2a | bS2b |λ L = L1∪L2 S →S1 | S2 In general: For context-free languages L1, L2 with context-free grammars G1, G2 and start variables S1, S2 the grammar of the union L1∪L2 has new start variable S and additional production S →S1 | S2. Concatenation: Context-free languages are closed under Concatenation operator. I.e. if L1 is context free and L2 is context free then L1.L2 is also context-free. Example: Language Grammer L1 = {an b n | n>=0} S1→aS1b |λ L2 = {w w R |w {a, b}*} S2 →aS2a | bS2b |λ L = L1.L2 S →S1 S2 In general: For context-free languages L1, L2 with context-free grammars G1, G2 and start variables S1, S2 the grammar of the union L1.L2 has new start variable S and additional production S →S1 S2. Star-operation: Context-free languages are closed under Star-operation. I.e. if L is context free then L* is also context-free. Example: Language Grammer L1 = {an b n | n>=0} S1→aS1b |λ L = (L1)* S →S S1|λ
- 15. In general: For context-free languageL1 with context-free grammar G1 and start variables S1 the grammar of the star operation (L1)* has new start variable S and additional production S →S S1|λ. Negative Properties of Context-Free Languages: Intersection: Context-free languages are not closed under Intersection operation. I.e. if L1 is context free and L2 is context free then L1∩L2 is not necessarily context-free. Example: L1 = {an b n c m | m, n>=0} L2 = {an b m c m | m, n>=0} Corresponding CFG: Corresponding CFG: S→AC S→AB A → aAb |λ A → aA |λ C → cC |λ B → bBc |λ But L1 ∩ L2 = {a n b n c n | n>=0} NOT context-free. Complement: Context-free languages are not closed under complement operation. I.e. if L is context free then L’ is not necessarily context-free. Example: L1 = {an b n c m | m, n>=0} L2 = {an b m c m | m, n>=0} Corresponding CFG: Corresponding CFG: S→AC S→AB A → aAb |λ A → aA |λ C → cC |λ B → bBc |λ But (L1‟∪L2‟)‟ = L1 ∩ L2 = {a n b n c n | n>=0} NOT context-free. Intersection of Context-free languages and Regular Languages:
- 16. The intersection of a context-free language and a regular language is a context-free language. I.e. if L1is context free and L2 is regular then L1∩L2 is context-free. This operation is said to be regular closure. Application of Regular Closure Prove that: L = {w: na = nb = nc} is not context-free Solution: If L = {w: na = nb = nc} is context-free. Now take a regular language say R = {a* b* c*} then the regular closure L ∩ {a* b* c*} = {a n b n c n} which is need to be context free (by regular closure property), but actually it is impossible for {a n b n c n} to be context free, i.e. we get a contradiction and is due to our initial assumption. Hence our assumption is wrong. Thus L is not context free. Decidable Properties of Context-Free Languages: Membership Question: For context-free grammar G finds if string w L (G). Membership Algorithms: Parsers Exhaustive search parser CYK parsing algorithm Efficient polynomial-time algorithms for the membership problem are the CYK algorithm and Earley's Algorithm (Both are dynamic programming based) Cocke–Younger–Kasami (CYK) algorithm: CYK algorithm is a parsing algorithm for context-free grammars; its name came from the inventors, John Cocke, Daniel Younger and Tadao Kasami. It employs bottom-up parsing and dynamic programming. The standard version of CYK operates only on context-free grammars given in Chomsky normal form (CNF). However any context-free grammar may be transformed to a CNF grammar expressing the same language. The worst case running time of CYK is Ө (n3 |G|), where n is the length of the parsed string and |G| is the size of the CNF grammar G.
- 17. The algorithm requires the context-free grammar to be rendered into Chomsky normal form (CNF), because it tests for possibilities to split the current sequence in half. Any context-free grammar that does not generate the empty string can be represented in CNF using only production rules of the forms: A→ BC and A→ Empty Language Question: For context-free grammar G find if L (G) =∅. Algorithm: 1. Remove useless variables 2. Check if start variable S is useless Infinite Language Question: For context-free grammar G find if L (G) is infinite. Algorithm: 1. Remove useless variables 2. Remove unit and productions 3. Create dependency graph for variables 4. If there is a loop in the dependency graph then the language is infinite Example: S →AB A →aCb | a B→ bB | bb C→ cBS Dependency graph is shown below: As the graph contains cycle, the grammar given will generate infinite number of strings which we can verify as follows:
- 18. S ⇒ AB ⇒ aCbB ⇒ acBSbB ⇒ acbbSbbb S ⇒* acbbSbbb ⇒* (acbb) 2 ( bbb)2 ⇒* (acbb)i S( bbb)i Table – closure properties Properties REG DCFL CFL CSL RC RE Reversal Inverse homomorphism Union Concatenation Kleen star (Kleen closure) Kleen Plus (Positive closure) -free homomorphism -free substitution Intersection Complement homomorphism substitution set difference Min Max Cycle Right quotient with a regular language ? Left quotient with a regular language ? Abbreviation Expansion REG Regular Language DCFL Deterministic Context-Free Language CFL Context-Free Language CSL Context-Sensitive Language RC Recursive Language RE Recursively Enumerable Language Table – Decidable Problems
- 19. (D – Decidable, U – Undecidable, T – Trivially decidable) Problem Regular DCFL CFL CSL Recursive RE Membership checking D D D Emptiness checking D D D Finite or Infinite D D D Equivalence D D U Intersection Emptiness D U Containment D U Universality D U Membership checking: For the given grammar G check whether string w L (G)? Emptiness checking: For the given grammar G check whether L (G) =∅? Finite or Infinite: For the given grammar G check whether L (G) is finite? Equivalence: Given two context-free grammars A and B, is L (A) = L (B)? Intersection Emptiness: Given two context-free grammars A and B, is L (A) L (B) =∅? Containment: Given a context-free grammar A, is L (A) ⊆ L (B)? Universality: Given a context-free grammar A, is L (A) = ∑*? Note: Decision problems (answering yes or no) are classified as decidable and undecidable problems. There exists an algorithm (algorithms that output yes/no, not a generalized algorithm) for decidable problem. No such algorithm exists if a problem is undecidable. The intersection emptiness problem is undecidable for CFG. However, the intersection of a context-free language and a regular language is context- free, and the variant of the problem where B is a regular grammar is decidable. The containment problem is undecidable for CFG. Again, the variant of the problem where B is a regular grammar is decidable.
- 20. List of regular languages “All finite languages are regular” L= {an b n | n ≤ 5} – finite language L = {an bl ak | n + l +k ≤ 5} – finite language L = {an bl ak | n + l +k>5} - Its regular expression is as follows: L= {an b l | n ≥ 100, l ≤ 100} - Its regular expression is as follows: Let L1 and L2 be regular languages. Let L = {w: w L1; w R L2}, then L is regular. To see this, just notice that L = L1 L2 R . Since the family of regular languages is closed under reversal and intersection, L is regular. L = {u w w R v: u, v, w {a, b} + } - Its regular expression is as follows: List of languages that are not regular
- 21. List of languages that are not regular but context free: L= {w w R |w is a member of {a, b}*} S → aSa | bSb | ∊ L={an b n | n>=0} L={an b m c m d n | n, m>=0} L = {an b n c m | m, n>=0}
- 22. L = {an b m c m | m, n>=0} L = {an bl ak | n>5, l >3, k≤ l} L = {an bm | n ≤ m + 3, n ≥ 0, m ≥ 0} S → aaaA | aa A | aA | λ, A → aAb | B, B → Bb | λ L = {an bm cn+m | m≥0, n≥0} S → aSc | S1| λ; S1 → bS1c| λ L = {wwR } List of languages that are not context free: L= {w w |w is a member of {0, 1}*} L= {an b n C n | n>=0} L = {w |w is a member of {a, b, c}* and na = nb = nc} L = {ai bj ck : i < j < k} L = {ap : p is a prime} Points: “If L1 and L2 are non-regular languages, then L1 ∪ L2 is non-regular." – False “All programming languages are context free”