Hdfs raid migration to hadoop 1.x
•
2 j'aime•1,960 vues

We adopt the basically structure of hdfs raid from Facebook, and we have migrated these feature to our cluster both in hadoop 1.x(0.20.203) and hadoop 2.x(hadoop 2.4) in Sina. We made some change during our development. Here is the theory of Rc code and the structure of hfs raid, besides we compared the efficiency of different Rc code and make a final conclusion.

Recommandé
Contenu connexe
Tendances
Similaire à Hdfs raid migration to hadoop 1.x
Similaire à Hdfs raid migration to hadoop 1.x (20)
Hdfs raid migration to hadoop 1.x
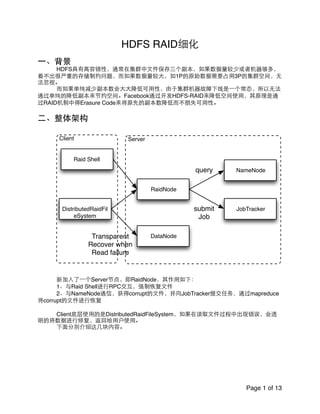
- 1. HDFS RAID细化! ! ⼀一、背景! ! HDFS具有⾼高容错性,通常在集群中⽂文件保存三个副本,如果数据量较少或者机器够多, 看不出很严重的存储制约问题,⽽而如果数据量较⼤大,如1P的原始数据需要占⽤用3P的集群空间,⽆无 法忽视。! ! ⽽而如果单纯减少副本数会⼤大⼤大降低可⽤用性,由于集群机器故障下线是⼀一个常态,所以⽆无法 通过单纯的降低副本来节约空间。Facebook通过开发HDFS-RAID来降低空间使⽤用,其原理是通 过RAID机制中得Erasure Code来将原先的副本数降低⽽而不损失可⽤用性。! ! ⼆二、整体架构! ! ! 新加⼊入了⼀一个Server节点,即RaidNode,其作⽤用如下:! ! 1、与Raid Shell进⾏行RPC交互,强制恢复⽂文件! ! 2、与NameNode通信,获得corrupt的⽂文件,并向JobTracker提交任务,通过mapreduce 将corrupt的⽂文件进⾏行恢复! ! ! Client底层使⽤用的是DistributedRaidFileSystem,如果在读取⽂文件过程中出现错误,会透 明的将数据进⾏行修复,返回给⽤用户使⽤用。! ! 下⾯面分别介绍这⼏几块内容。! ! ! ! ! ! ! Page of1 13 NameNode JobTracker RaidNode DistributedRaidFil eSystem DataNode query submit Job Transparent Recover when Read failure ServerClient Raid Shell
- 2. 三、RaidNode内部结构! ! RaidNode是最主要的结构,它负责定期的读取配置⽂文件,找到需要Raid的⺫⽬目录或者⽂文件 进⾏行Raid,对失效的block通过EC算法进⾏行恢复,以及接收⽤用户的强制恢复指令对特定⽂文件进⾏行 恢复,同时提供http服务⽅方便⽤用户查看状态等。! ! RaidNode内部结构包括有ConfigManager,BlockIntegrityMonitor, TriggerMonitor, PlacementMonitor, PurgeMonitor,HarMonitor,StatsCollectorThread以及HTTP Server等组成。! ! (⼀一)ConfigManager! ! 每隔⼀一定时间动态的加载配置,提供reload功能。! ! ! (⼆二)BlockIntegrityMonitor! ! BlockIntegrityMonitor的作⽤用主要是维护raid后数据的有效性,如果出现数据异常(如数据 丢失,数据checksum出错等,机器下线等),进⾏行recovery操作。! ! BlockIntegrityMonitor是⼀一个虚类,它⼜又两种⼦子类,也就是有两种⼯工作模式,⼀一个是 DistBlockIntegrityMoniter,⼀一个是LocalBlockIntegrityMonitor,对应了通过mr任务进⾏行恢复和本地进 ⾏行恢复。由于本地模式没有太多意义,不进⾏行讨论。! ! 在DistBlockIntegrityMonitor中,通过三个⼯工作线程来控制数据有效性的检测和提交任务进 ⾏行恢复,分别是CorruptionWorker, DecommissionWorker和CorruptFileCounter。! ! DistBlockIntegrityMonitor⾸首先定义了这些⼯工作线程的⼀一些基本变量和流程,定义了⼀一个虚 类Worker线程,其流程如下:! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! 每次loop的时候都先更新当前状态,获取丢失的⽂文件列表,随后计算优先级提交任务。! ! 1、CorruptionWorker线程! ! CorruptionWorker负责将corrupt的File定期进⾏行恢复,⾸首先通过与NN通信获得需要恢复的 ⽂文件,随后计算优先级,提交任务。! ! (1)getLostFiles每次都是通过RPC与NameNode通信,得到neededReplication的列表。! ! (2)computePrioritiesAndStartJobs! ! 将获得的CorruptFile 轮询,如果是监控⺫⽬目录下的⽂文件,加⼊入需要恢复映射结构中,等待提 交任务,在提交任务前,需要计算⼀一下优先级,优先级的计算是通过FileCheckRunnable来计算 的。! Page of2 13 updateStatus updateRaidNode Metric getLostFiles ComputePriorities AndStartJobs
- 3. ! FileCheckRunnable根据Codec类型,还有丢失的Block个数,来设置优先级为LOW, LOWEST,HIGH三种类型。⽐比如如果是XOR丢失块优先级就是HIGH,如果是RS,丢失了多于⼀一 个块就是HIGH,否则就是LOW等。! ! 随后提交任务,将任务异步提交到⼀一个Executor⾥里⾯面去执⾏行。! ! ! ! 2、DecommissioningWorker线程! ! (1)getLostFiles通过DFsck去获得lost file。! ! (2)computePrioritiesAndStartJobs! ! 根据获得的lost file,计算优先级,普遍优先级较低,最后提交任务。! ! ! 3、CorruptFileCounter线程! ! 定期的通过fsck获取raid中missing的block数,并更新到metrics系统中。! ! ! (三)TriggerMonitor! ! TriggerMonitor是RaidNode中最主要的⼀一个⼯工作线程。! ! TriggerMonitor定时更新Configuration,获得需要Raid的⽂文件或者⺫⽬目录,随后提交Mr任务 进⾏行raid。raid过程后⾯面会详细介绍。! ! ! (四)PurgeMonitor! ! PurgeMonitor主要对过期失效的parity⽂文件、⺫⽬目录进⾏行删除。! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! PurgeMonitor最主要的是确定purge的元素,它是通过DirectoryTraversal来对进⾏行遍历, 需要提供check⽅方法,来确定返回符合purge条件的元素。! ! ⾸首先是对directory进⾏行purge。! ! 然后是对parity进⾏行purge,同时检查是否需要将parity移动(原因是parity尽可能分散,防⽌止 某个节点挂起导致的数据丢失)。! ! ! ! (五)PlacementMonitor线程! ! 内部主要靠BlockMover线程⼯工作,与PurgeMonitor配合,通过拉取datanode topology以 及socket通知DataNode将block到其它DataNode上。! ! ! ! Page of3 13 purgeDirectory purgeParity purgeHar BlockMover
- 4. ! (六)HarMonitor线程! ! 定期的扫描parity⽂文件,提交任务,进⾏行归档。! ! ! (七)StatisticsCollector线程! ! 获取RaidNode运⾏行过程中得⼀一份快照状态供使⽤用。! ! ! 四、编码过程! ! TriggerMonitor定期的将⽂文件或者⺫⽬目录进⾏行raid化,通过map reduce向集群提交任务来加 速raid。! ! (⼀一)、编码⽅方式! ! HDFS Raid⺫⽬目前⽀支持三种⽅方式进⾏行冗余编码,分别是XOR,Reed-Solomon以及Jerasure Code三种。其中前两种采⽤用的是java 代码进⾏行冗余码的编解码,⽽而Jerasure Code采⽤用的是C实 现的native代码。! ! 1、XOR编码! ! XOR编码很简单,其原理就是利⽤用异或的性质:! ! 假设数据块为D1,D2.....Dn,冗余位是P! ! 则P = D1^D2^….Dn! ! 如果⼀一个数据块损坏,那么可以通过冗余位P进⾏行恢复,假设Dj损坏,那么恢复的⽅方法是! ! Dj=D1^D2^…Dj-1^….Dn^P! ! XOR编码只能容忍⼀一个块损坏,推荐10个数据块⽣生成1个冗余块,并且所有块的副本数是 2。! ! 这样从原来的10个Block,3个副本,需要占据30个Block的存储空间,减少为10个Block, 1个Parity Block,2个副本,只需要占据22个Block的存储空间。节省27%的存储空间。! ! ! 2、Reed-Solomon编码! ! Reed-Solomon编码原先主要⽤用于通信纠错等领域,⺫⽬目前已经⼲⼴广泛的应⽤用于存储(raid)等领 域。RS编码涉及理论范德蒙矩阵,伽罗华域,⾼高斯矩阵近似等概念,尤其涉及到信息论等学科, 较为复杂。简单的说就是有(n,k),n为码⻓长,k为信息源⻓长度,n-k为冗余码⻓长度,经过计算,通过 伽罗华域的编解码,能够在有n-k个单位码失效的基础上还原原信息码。! ! 在FB的实现中,推荐10个数据块为⼀一个stripe,⽣生成4个parity冗余块,这样⾄至多可以存在4个 坏块,依然能够恢复。! Page of4 13 D1 D2 D3 ...... Dn P D1 D2 D3 ...... Dn P D1 D2 ...... D10 P1 P2 P3 P4
- 5. ! 由于RS编码能够容忍更多的块损坏,所以RS编码更加激进的只选取了⼀一个副本。这样从 原来的10个Block,3个副本,需要占据30个Block的存储空间,减少为10个Block,4个Parity Block,1个副本,只需要占据14个存储空间.节省了53%的存储空间。! ! ! 3、Jerasure Code! ! 采⽤用的是Native代码,在效率上可能更⾼高(?)。! ! ! 总结:! ! 上述的Raid过程采⽤用的不同编码,其根本⺫⽬目的都是希望通过⼀一定的冗余性来较少存储空 间,属于⽤用计算来换存储。同时,由于parity与stripe中得block相关性增⼤大,要求我们将同⼀一 stripe中的不论parity还是block都能够平均的分不到集群中。最后,较少的block做raid是没有意义 的。! ! ! ! (⼆二)、编码过程! ! 1、提交阶段! ! RaidNode通过TriggerMonitor线程扫描配置⺫⽬目录,其⼯工作在两种模式下,⼀一种是Local模 式,既在RaidNode下进⾏行所有raid操作,以及Distribute模式,既提交Map Reduce任务来进⾏行 raid操作。Local模式不具备可操作性,所以选取Distribute模式。在Distribute模式下,RaidNode 负责提交Map Reduce任务。其过程如下:! ! ! ! ! ! ! 线程每次执⾏行⾸首先会reload⼀一下所有的Policy,policy是以! json格式定义,包含有id,parity存储位置,stripe⻓长度以及parity⻓长度, raid采⽤用的⽅方法,是否对dir进⾏行raid。! ! ! 随后对reload的policy进⾏行轮询,查找定义的⺫⽬目录,对满⾜足条件的⺫⽬目 录或者⽂文件将其Split,Split主要的作⽤用是计算当前⺫⽬目录或者⽂文件的 Block数,根据Policy定义确定的Stripe个数,parity个数等,封装成为! EncodingCandidate类。! ! ! 初始化Job,将EncodingCandidate类序列化,同时定义 InputFormat为DistRaidInputFormat,只有map没有reduce,map类为 DistRaidMapper,取消推测式执⾏行等。! ! ! ! 最后提交任务,并监控该任务。! ! ! ! ! ! 2、map 执⾏行阶段! ! map执⾏行阶段的流程图如下:! ! ! ! ! ! Page of5 13 SplitPaths Job Reload Policy
- 6. ! ! ! ! ! (1)初始化Codec,获取进⾏行raid的⽅方式,stripe包含的 block数,parity个数等! (2)反序列化出EncodingCandidate,包含有raid所需 要的所有信息! (3)随后进⾏行检查,分别检查该path是否存在,是否 被修改,所包含的Block数是否过少! (4)如果均满⾜足条件,就⽣生成parity⽂文件! ! ! ! ! ! ! ! ! ! ! ! ! ! ! Generate Parity File 的过程较为复杂,其基本流程为:! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! Page of6 13 EncodingCandidate Path End Path End Block 3 No Action Generate Parity File tmp tmp EC EC Block tmp parity
- 7. ! (1)⾸首先创建tmp⺫⽬目录以及tmp⽂文件! ! (2)通过EncodingCandidate获取需要raid的⽂文件,Block等! ! (3)StripeReader类⽤用来并⾏行的读取多个Block,⽤用于⽣生成parity⽂文件,parity⽂文件根据算法 不同可能有多个块组成,如XOR是⼀一个块,⽽而RS就是四个块,这样第⼀一个块⾸首先写⼊入输出流写 ⼊入到HDFS⽂文件中,其它的块⾸首先写⼊入到本地临时⽂文件,调⽤用EC算法⽣生成好后⼀一次将这些块 append到HDFS⽂文件中(不是HDFS Append,是输出流Append)。! ! (4)⾄至此parity⽂文件⽣生成,剩下的就是做⼀一些cleanup! ! ! 五、集群搭建及配置! ! 集群搭建在10.39.5.21-10.39.5.44上,其中10.39.5.21上部署NameNode,JobTracker, RaidNode, 其它机器为处理机。! ! 相对于原来的Namenode,部署上多了⼀一个中⼼心节点RaidNode,同时还需要增加⼀一些配 置:! ! ! ! ! ! hdfs-site.xml新增部分! ! ! ! ! ! ! Page of7 13 Key Value Desciption raid.config.file 需要raid的⽂文件在DFS中位 置及相关属性 raid.codecs.json raid的codec及实现类, stripe⻓长度等属性 raid.server.address raid rpc server的地址 raid.blockfix.classname org.apache.hadoop.raid.Di stBlockIntegrityMonitor integerityMonitor实现类, 分为本地和mr fs.hdfs.impl org.apache.hadoop.dfs.Dis tributedRaidFileSystem FileSystem的实现类 dfs.block.replicator.classna me org.apache.hadoop.hdfs.se rver.namenode.BlockPlace mentPolicyRaid NN Block选择策略 raid.classname org.apache.hadoop.raid.Di stRaidNode RaidNode实现类 mapred.raid.http.address raid http server地址 raid.policy.rescan.interval raid相关⺫⽬目录后相隔多⻓长时 间再⼀一次做操作 hdfs.raid.block.move.simul ate FALSE raidnode控制放置位置改 变,是否启动该功能
- 8. ! ! ! ! ! ! ! ! ! raid.xml配置! ! ! raid.xml⽰示例:! Page of8 13 key value Description policy name policy的名称,唯⼀一标识 srcPath prefix 该policy对应的⺫⽬目录 codecId 与HDFS Codec对应 property 可以配置额外的property,如 raid后的副本数,meta副本 数等 <configuration>! <policy name = "rs">! <srcPath prefix="hdfs://yz522.hadoop.data.sina.com.cn:8020/test"></srcPath>! <shouldRaid>true</shouldRaid>! <codecId>rs</codecId>! <property>! <name>targetReplication</name>! <value>1</value>! <description> after RAIDing, decrease the replication factor of a file to! this value.! </description>! </property>! <property>! <name>metaReplication</name>! <value>1</value>! <description> the replication factor of the RAID meta file! </description>! </property>! <property>! <name>modTimePeriod</name>! <value>1000</value>! <description> time (milliseconds) after a file is modified to make it a! candidate for RAIDing! </description>! </property>! </policy>! </configuration>
- 9. ! ! ! 六、测试内容! ! (⼀一)、向相应⺫⽬目录灌数据,然后⼿手动提交任务将相应⺫⽬目录下的所有⽂文件进⾏行raid,并且⽐比 较不同算法时间与系统资源占⽤用情况。! ! 1、向⺫⽬目录灌数据,每个⺫⽬目录都保存250个⽂文件,总共500GB数据,块⼤大⼩小128MB。! ! 2、测试结果:! ! 3、结果分析:! ! 从上图我们可以看出,⾸首先RS算法,Java Implements中通过top可以看出有⼀一个cpu 核已 经被跑满,cpu成为了系统的瓶颈,所以每秒处理速度是23.5MB,出⼝口和⼊入⼝口带宽⼤大概在45MB 左右。! ! 随后通过两个⽣生成数据的任务,第⼀一个任务跑500个map,把每台机器上的map都占满, 这样能够打满带宽,第⼆二个任务只是⽤用20个map,这样带宽的使⽤用在100MB左右。! Page of9 13 数据量 执⾏行时间 算法 每秒处理数据量 500GB 21267s RS java implement 23.5MB 500GB 10560s Jerasure native implement 47.3MB
- 10. ! 最后是Jerasure Native实现,与⽣生成数据相似,每个map对应⼀一个Client的OutputStream 去写⼊入数据,可以看出CPU已经不是系统瓶颈,由于单个Client的限制,导致了带宽与20个map ⽣生成数据的任务带宽相似。! ! 综上:RS算法的Java Implements CPU是瓶颈。! ! Jerasure算法的Native实现单个Client的是瓶颈。! ! ! (⼆二)、将Raid成功的⽂文件删除⼀一个block后查看RaidNode恢复情况! ! 1、步骤! ! (1)⾸首先成功Raid⼀一些⽂文件! ! (2)通过FSCK找到该⽂文件的Block以及Location! ! (3)登陆DataNode,直接删除该Block! ! (4)NameNode通过DataNode的BlockReport获取Block丢失情况! ! (5)RaidNode与NameNode通信后去丢失数据,并且启动任务去恢复! ! 为了加快发现丢失块的时间,将BlockReport的时间设置为1分钟,在fb集群中需要配置! ! dfs.blockreport.intervalMsec参数,设置为30000。! ! 2、测试结果! ! 可以看出经过⼀一定时间,由RaidNode启动进⾏行修复。! ! 3、结果分析! ! RaidNode恢复时间与DataNode BlockReport时间有直接关系,⽆无论是⼿手动恢复还是 RaidNode DistBlockIntegrity线程⾃自动恢复,都需要与NameNode通信获取丢失的块信息来进⾏行恢 复,⽽而NameNode的信息是通过DataNode BlockReport获得的。! ! ! (三)、下线⼀一台DataNode! ! 1、步骤! ! (1)选择⼀一个DataNode,通过hadoop-daemon.sh stop datanode! ! (2)等待NameNode认定DataNode下线的时间! ! (3)查看恢复情况并记录系统运⾏行情况! Page of10 13
- 11. ! 2、测试结果! ! 下线后raidnode启动任务进⾏行修复。! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ⼀一台机器上带宽占⽤用情况! ! ⼀一台机器上cpu占⽤用情况! ! ! ! ! Page of11 13
- 12. ganglia中集群⺴⽹网络情况! ! ! 3、结果分析! ! 综上数据所⽰示,机器下线将会对集群的整体⺴⽹网络及单机⺴⽹网络产⽣生较⼤大压⼒力,⽐比如从我们的 数据可以看出,下线⼀一台机器后默认最多同时处理100个⽂文件,根据优先级提交任务,如果某台 机器上分配两个或以上的map task就会将⺴⽹网络跑满,⽽而⼀一个任务cpu通常能跑满⼀一个核。! ! 当然测试是将所有数据进⾏行raid,这样下线⼀一台机器就需要将所有块进⾏行恢复,会恢复⼤大 量的块,必然会对集群造成较⼤大⺴⽹网络压⼒力。如果只对部分数据进⾏行raid,并且机器数量⾜足够,并 且调整参数,在恢复的时效性与系统的性能进⾏行权衡,能够控制对带宽的影响。! ! ! ! ! ! ! ! ! ! ! Page of12 13
- 13. 七、向203集群迁移⽅方案! ! (⼀一)已知问题! ! 1、StatCollector线程NPE问题,导致raid⻚页⾯面⽆无法正常显⽰示! ! 2、getSplit计算问题! ! 3、metrics计算问题,process数据过⼤大! ! 4、BlockPlacement会导致DataNode的NPE问题,由于版本问题,在0.20.203上⾯面可能不 存在! ! 5、⽣生成parity是否可以多线程写⼊入多个⽂文件! ! ! (⼆二)不兼容部分,需要修改! ! 1、ClientProtocol以及相应的NameNode代码修改及增加raid功能! ! 2、ClientDatanodeProtocol以及相应的DataNode代码修改及增加raid功能! ! 3、DFSck重写! ! 4、NameNode加⼊入对raid分配block策略,需要熟悉代码并测试(测试过程中有些问题)! ! 5、build.xml ivy.xml ivy.properties⽂文件改写! ! 6、Metrics系统不兼容,需要重写! ! ! ⼋八、实施过程! ! (⼀一)RaidNode! ! 1、⾸首先修改build.xml ivy.xml ivy.properties与0.20.203兼容! ! 2、JUnit测试需要InjectHandler进⾏行测试过程,与0.20.203使⽤用不⼀一样,考虑不引⼊入 InjectHandler! ! 3、LocatedFileStatus类,封装了File Status 和 Block信息,⽤用于Raid BlockPlacement决 策时候使⽤用,加⼊入! ! 4、RemoteIterator,远程迭代器,加⼊入! ! 5、底层RPC略有不同FB加⼊入了signature函数,需要修改,同时JMX注册部分也需要修改! ! ! ! (⼆二)ConfigManager! ! 1、No Json here! ! ! (三)RaidNodeInstrument! ! 加⼊入metricsV2! ! ! (四)DataFsck! ! 注意hdfs-site.xml中的所有属性必须是final,在过程中发现Codec的init会出现问题! ! ! (五)DistBlockIntegrity Page of13 13