
Recommandé
Contenu connexe
Tendances
Tendances (20)
En vedette
Similaire à 2012 mdsp pr06 hmm
Similaire à 2012 mdsp pr06 hmm (20)
Dernier
Dernier (20)
2012 mdsp pr06 hmm
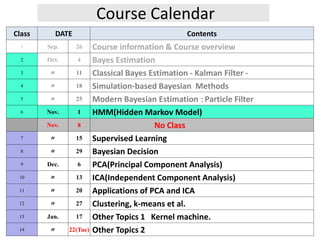
- 1. Course Calendar Class DATE Contents 1 Sep. 26 Course information & Course overview 2 Oct. 4 Bayes Estimation 3 〃 11 Classical Bayes Estimation - Kalman Filter - 4 〃 18 Simulation-based Bayesian Methods 5 〃 25 Modern Bayesian Estimation :Particle Filter 6 Nov. 1 HMM(Hidden Markov Model) Nov. 8 No Class 7 〃 15 Supervised Learning 8 〃 29 Bayesian Decision 9 Dec. 6 PCA(Principal Component Analysis) 10 〃 13 ICA(Independent Component Analysis) 11 〃 20 Applications of PCA and ICA 12 〃 27 Clustering, k-means et al. 13 Jan. 17 Other Topics 1 Kernel machine. 14 〃 22(Tue) Other Topics 2
- 2. Lecture Plan Hidden Markov Model 1. Introduction 2. Hidden Markov Model (HMM) Discrete-time Markov Chain & HMM 3. Evaluation Problem 4. Decoding Problem 5. Learning Problem 6. HMM for speech recognition
- 3. 1. Introduction 3 1.1 Discrete-time hidden Markov model (HMM) The HMM is a stochastic model of an ordered or sequential process that can be used for modeling and estimation. Its distinguishing feature is the probabilistic model for both states transition and measurements process. The internal states are usually not observed directly therefore, are hidden. 1.2 Applications All fields treating discrete representation of stochastic processes: Speech recognition, Natural language, Communications, Economics, Biomedical (DNA analysis), Computer vision (Gesture recognition)
- 4. 2. HMM 4 2.1 Discrete-time Markov Chains (finite state machine) 1, 2, At each time step t, the state variables are defined by state space where, ....., Pr : the probability that at time t the state i is occupied. 1st-order Markovian: Pr xN i n x t x t x t X X X X X 1 , 2 ,...., 0 Pr 1 Define a :=Pr 1 (time-stationary) m r l n m mn n m x t x t x x t x t x t x t Define the state transition probability: : Pr 1 (time stationary) Initial probability: Pr 0 = 1,..., mn n m i i x a x t x t x i N X X (1) (2) (3) (4) 0 ,....., xNx x
- 5. (hidden (latent) states) (visible variables) Introduce the measurement or output process into the Markov chain Markov Chain + measurements HMM discrete outputs in the observation spacyN 1 2 : e. (observation space) , ,....., The observation or emission probability (likelihood) : Pr Define : 1 , 2 ,......, , : 1 , 2 ,......, : yN kl l k T i j l T k r p t T r y t y y y c y t x t X x x x T Y y y y T Y y Y Y 0 ,......, Initial / final (absorber) states: , . st y T x 2.2 Hidden Markov Model (HMM) (5) (6) (7)
- 6. 6 x(t) : state sequence (hidden) y(t) : measurement sequence 1ix t jx t 1kx t 1ly t my t 1ny t ija jka ilc jmc knc Structure of HMM : , ,ij jk iParameters a c
- 7. 1ix t jx t 1kx t 1ly t my t 1ny t ija jka ilc jmc knc Evaluation problem : Determine the probability of a particular sequence of output YT Decoding problem : For a given output sequence YT, determine the most probable sequence XT of hidden states that leads to the observation YT Learning problem : Given a set of output sequences {Y(i) t}, determine the model parameters .ija jkc Three Central Issues in HMM
- 8. 1ix t jx t 1kx t 1ly t my t 1ny t ija jka ilc jmc knc Evaluation problem : Determine the probability of a particular sequence of output YT Decoding problem : For a given output sequences Yt’s, determine the most probable sequence of hidden states that lead to those observations Learning problem : Given a set of output sequences Yt’s, determine the model parameters .ija jmc Three Central Issues in HMM Pr TY
- 9. 1ix t jx t 1kx t 1ly t my t 1ny t ija jka ilc jmc knc Evaluation problem : Determine the probability of a particular sequence of output Yt Decoding problem : For a given output sequence YT, determine the most probable sequence XT of hidden states that leads to the observation YT Learning problem : Given a set of output sequences Yt’s, determine the model parameters .ija jmc Three Central Issues in HMM
- 10. 1ix t jx t 1kx t 1ly t my t 1ny t ija jka ilc jmc knc Evaluation problem : Determine the probability of a particular sequence of output Yt Decoding problem : For a given output sequences Yt’s, determine the most probable sequence of hidden states that lead to those observations Learning problem : Given a set of output sequences {Y(i) T}, determine the model parameters .ija jmc Three Central Issues in HMM
- 11. 3. Evaluation Problem max 1 max The probability that the model produces an output sequence is Pr Pr Pr where indicates an index of a possible sequence of T hidden states of , and (the number of possible T r r r T T T T r r T Y Y Y X X r X r terms in ).T T xX N 1 0 0 From the first-order Markovian property, the second term of (8) Pr Pr 1 , 2 ,...., Pr 1 product of the ' At , : final absorbing state and gives the output uniquly. T T ij t X x x x T x t x t a s t T x T x x T y (8) (9)
- 12. max max 1 1 sum over all possible sequences of hidden states of From the measurement mechanism, Pr Pr Finally, (9) and (10) give Pr Pr Pr 1 T r T T t r T T r t r Y X y t x t Y y t x t x t x t the conditional probabilities Basic elements in the Pr representation in (11) : Pr Pr 1 Evaluation of Pr by the forward algorithm uses the following : Pr T T j t j Y y t x t x t x t Y forward variables t Y x t Forward Algorithm (10) (11) (12) (13)
- 13. The represents the probability that the HMM is in the hidden state at step (i.e. ) having generated the first (0 ) elements of ( i.e. ). j j j T t t x t x t x t t Y Y Forward variable computation algorithm: 0 0 and initial state 1 0 and initial state elsewhere 1 where is the index of the output j i ij jk i k t j t t j t a c k y t y (14)
- 14. 14 Example: Forward algorithm 0 4 0 0 1 2 3 0 1 2 3 Three hidden states and an explicit sbsorber state and unique final output = , , , , , , , 1 0 0 0 1 0 0 0 0.2 0.3 0.1 0.4 0 0.3 0.4 , 0.2 0.5 0.2 0.1 0 0.1 0.1 0.8 0.1 0.0 0.1 , 0.1 0 ij jk x y x x x x y y c y y y a X Y 1 3 2 0 1 0 0.2 0.1 0 0.5 0.2 0.2 the probability it generates the following particular sequence 1 , 2 , , Suppose we have the initial hidden state at 0 to be 7 1 . . 0. Compute y y y y y t y y t y t x
- 15. 15 0 1 2 3 x x x x t 0 0 0 1 1 0 0 2 0 0 3 0 0 0 1 0.09 1 1 0.01 2 1 0.2 3 1 0 0 2 0.0052 1 2 0.0077 2 2 0.0057 3 2 0 0 3 0.024 1 3 0.0002 2 3 0.0007 3 3 0.0011 0 4 0 1 4 0 2 4 0 3 4 0 1 2 3 4 y t 1y 3y 2y 0y Trellis Diagram of forward variables * Numerical values in above diagram are rounded to four places of decimals
- 16. 16 4. Decoding problem 16 Problem: Suppose we have an HMM as well as an observation YT. Determine the most likely sequence of hidden states {x(0), ..……,x(T) } that leads the observation. Solution: Convenient method is to connect the hidden states with the highest value of 𝛼𝑗 at each step t in the trellis diagram. This one does not always give the optimal solution due to the existence of forbidden path connection in the case of 𝑎𝑖𝑗 = 0.
- 17. 17 5. Learning problem 17 Problem: Given a training set of observation sequences, {YT j } j=1,….,J Find the best (MAP) estimate of aij and cjk ,assuming(*) that the hidden state sequences for these training data are known a priori. (*More sophisticated algorithm without assuming this is actually applied in practice) Useful approach is to iteratively update the parameters in order to better explain the observed training sequences. Forward-backward algorithm The forward variables 𝛼i(t) as well as the following backward variables𝛽i(t) are employed in this algorithm.
- 18. 0 0 Backward variable computation: 0 and 1 and 1 otherwise where is the index of the output 1 i i i j ij jk j k t T x t x t t T x t x t a c k y t y 1: : : Pr represents the probability that the model is in and generates the given target sequence from ( 1) to ( ) . i t T i i t T defined by t Y x t x t x y t y T Y Backward Algorithm Backward variable (15) (16)
- 19. 19 Define the following posterior probability of a state sequence passes through state xi(t-1) and xj(t). 1 Pr i ij jk j ij T t a c t t Y Forward-backward algorithm : Pr 1 , , where = , is the HMM parameters. ij i j T ij jk t x t x t Y a c The 𝛾𝑖𝑗 𝑡 is given as follows: * 1 : Pr 1 , , Pr 1 , , , 1 Pr Pr ij i j T i j t t T i ij jk j T T t x t x t Y x t x t Y Y t a c t Y Y (17) (18) (19) Path’s past history at t Evaluation problem Current activity at t with observation yk(t+1) Path’s future history at t
- 20. Baum-Welch estimate (20) 1 1 1 1 1 1 ˆ , ˆ , such that x x T ij t ij NT ij t j T ij t jk kNT ij t j t a t t c y t y t In our case, since all of the paths are known, then it is possible to count the number of times each particular transition or output observation in a set of training data. The HMM parameters are empirically estimated by use of the following frequent or repetition ratio.
- 21. 21 where : counted number of the state transition from to : counted number of the output observation emitted from (t) to y ij i j jk i k N x t x x N y t x ˆ ˆ, ij jk ij jk ij jk j j N x t N y t a c N x t N y t Unknown state sequence case: Some types of iterative approach will be applied. Expectation Maximization (EM)/Baum-Welch approach: Start form an initial guess of 𝑎ij , and 𝑐jk gives the initial estimates of αi(t-1) and 𝛽j(t) , then repeat the B-W with known parameters. (21)
- 22. Phoneme(*)-unit HMM (* smallest segment unit of speech sound) Short-time Frequency spectrum data (Mel cepstrum 12-dimensional vector sequence) → y(t) t=1,…,T Left-to-right HMM (no reverse-time transition model ) Learning problemHMM of /a/ 6. Application of HMM -speech recognition-
- 23. Speech Signal 0 0.5 1 1.5 2 2.5 3 3.5 4 x 10 4 -6 -4 -2 0 2 4 6 time amplitude /g/ /a/ Phoneme
- 24. 20 40 60 80 100 120 50 100 150 200 250 -60 -40 -20 0 20 40 Time-Frequency domain representation -SPECTROGRAM- Time (Frame number) Frequency ( Bin )
- 25. HMM of /k/ HMM of /e/ HMM of /i/ HMM of /o/ Word-level HMM (Linked phoneme HMM’s)
- 26. Learning problem 𝑊𝑖 𝑖th 𝑊𝑜𝑟𝑑 ↔ 𝜽𝑖 (𝐻𝑀𝑀 𝑝𝑎𝑟𝑎𝑚𝑒𝑡𝑒𝑟𝑠) Recognition: Given a sequence of speech feature vectors for an uttered word y(t) t=1~T, Find the most probable word WMAX in the following sense Evaluationproblem max Pr Pr arg Pr ( ) Pr Pr : Language model Pr Pr 1,..... i T i i i T W T i T i T i W Y W W W Max W Y Bayes Y W Y W Y i N
- 27. Other application fields of HMM ・Time sequence : Music, Economics ・Symbol sequence : Natural language ・Spatial sequence : Image processing (Gesture recognition) ・structure order : Sequence of a gene's DNA References: Main reference materials in this lecture are [1] R.O. Duda, P.E. Hart, and D. G. Stork, “Pattern Classification”, John Wiley & Sons, 2nd edition, 2004 [2] J. Candy, “ Bayesian Signal Processing Classical, Modern, and Particle Filtering Methods”, John Wiley/IEEE Press, 2009