Télécharger en tant que PDF, PPTX


























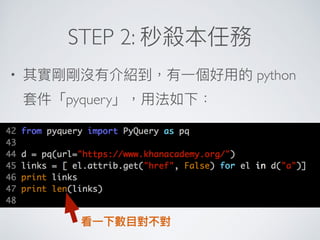

















Le document fournit un guide technique sur l'utilisation de divers modules Python pour le crawling et le scraping web, notamment des outils comme 'whois', 'requests', et 'BeautifulSoup'. Il détaille les étapes à suivre, y compris l'analyse des fichiers robots.txt, l'utilisation de regex pour le traitement de modèles, et les méthodes pour contourner des obstacles comme les CAPTCHA. Enfin, il mentionne des solutions pour le rendu JavaScript et l'automatisation du navigateur.
![Agile x API x Documentation @ NGO [[MOPCON2015]]](https://cdn.slidesharecdn.com/ss_thumbnails/mopcon2015aadngo-151114145910-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

































