Télécharger en tant que PDF, PPTX






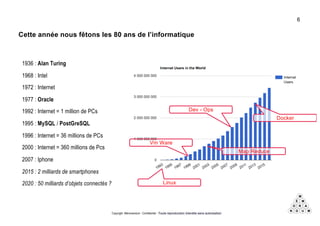
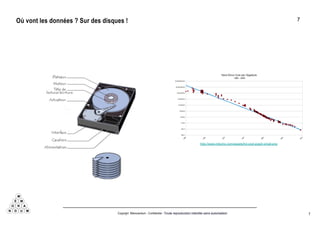




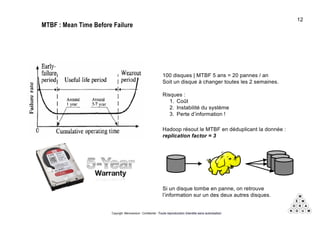
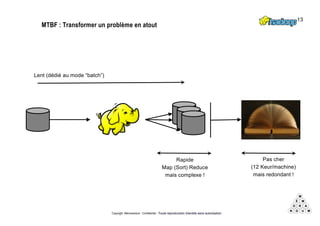


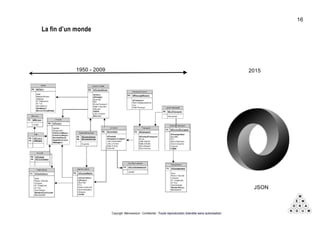
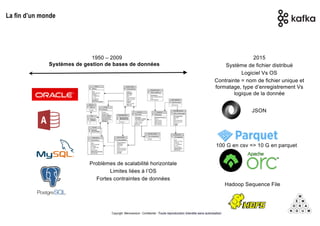
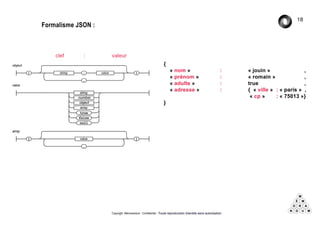
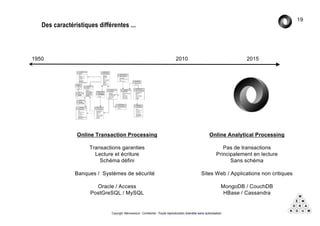
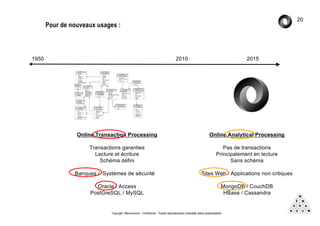
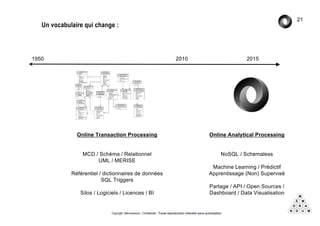


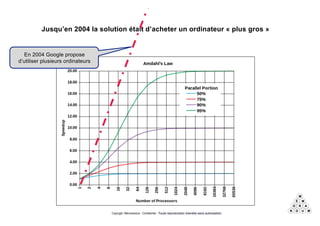
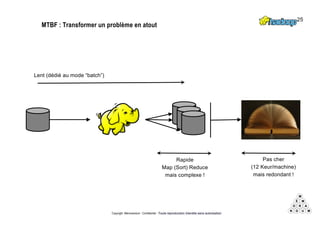










Mémorandum est un cabinet de conseil spécialisé en data stratégie, intervenant sur le coaching d'organisation, l'analyse de données et l'industrialisation de solutions informatiques. L'équipe, composée d'experts en big data et machine learning, utilise des méthodologies alliant stratégie et technique pour garantir des résultats adaptés. En outre, Mémorandum organise des événements et forme des professionnels sur les technologies liées aux big data.



























