Challenges in usingGenAI APIs
• Track Token usage across multiple applications
• Ensure single app doesn’t consume whole TPM quota
• Distribute load across multiple endpoints
• Ensure committed capacity in PTUs is exhausted before falling back to PAYG instance
7.
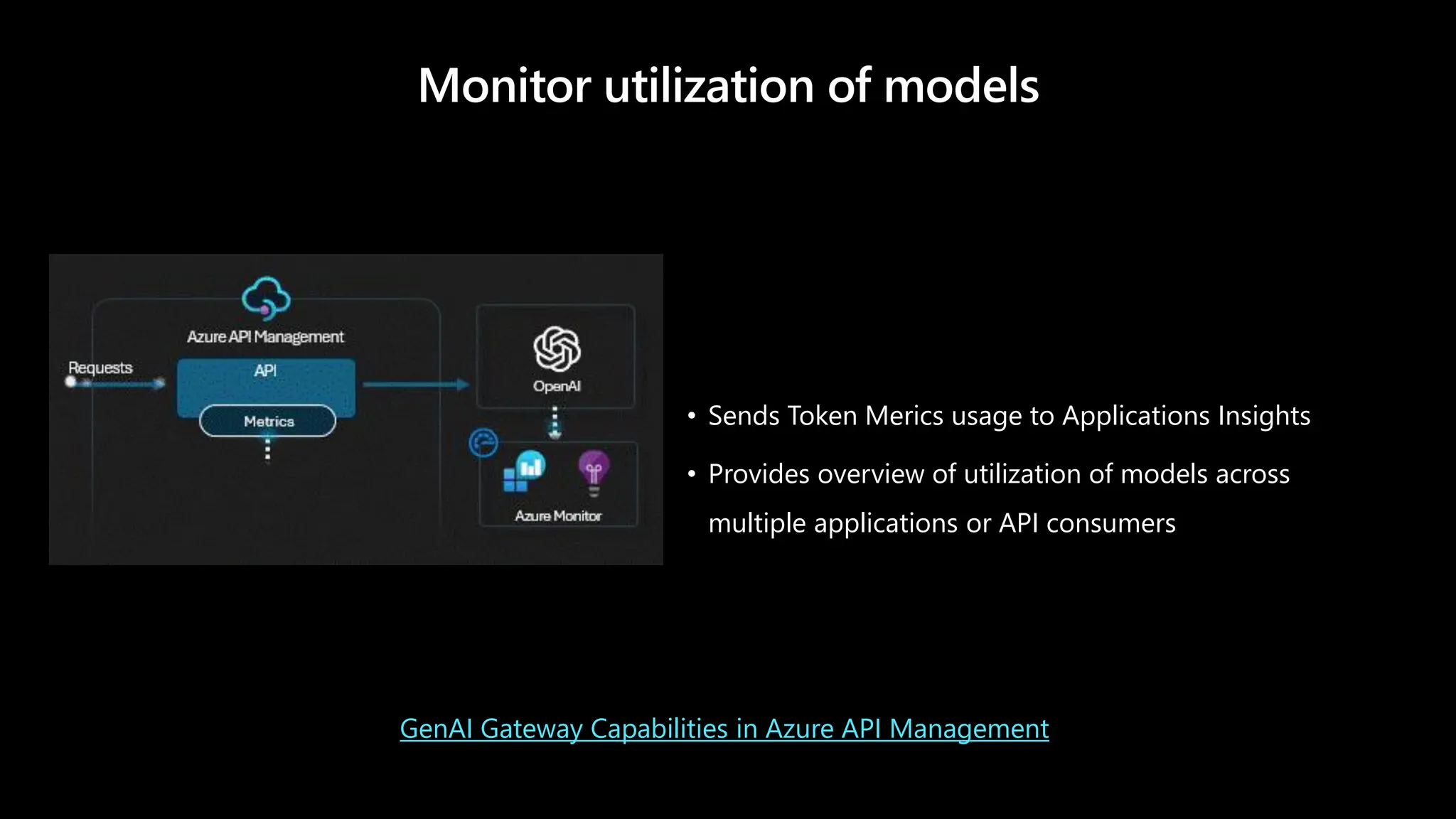
Monitor utilization ofmodels
• Sends Token Merics usage to Applications Insights
• Provides overview of utilization of models across
multiple applications or API consumers
GenAI Gateway Capabilities in Azure API Management
8.
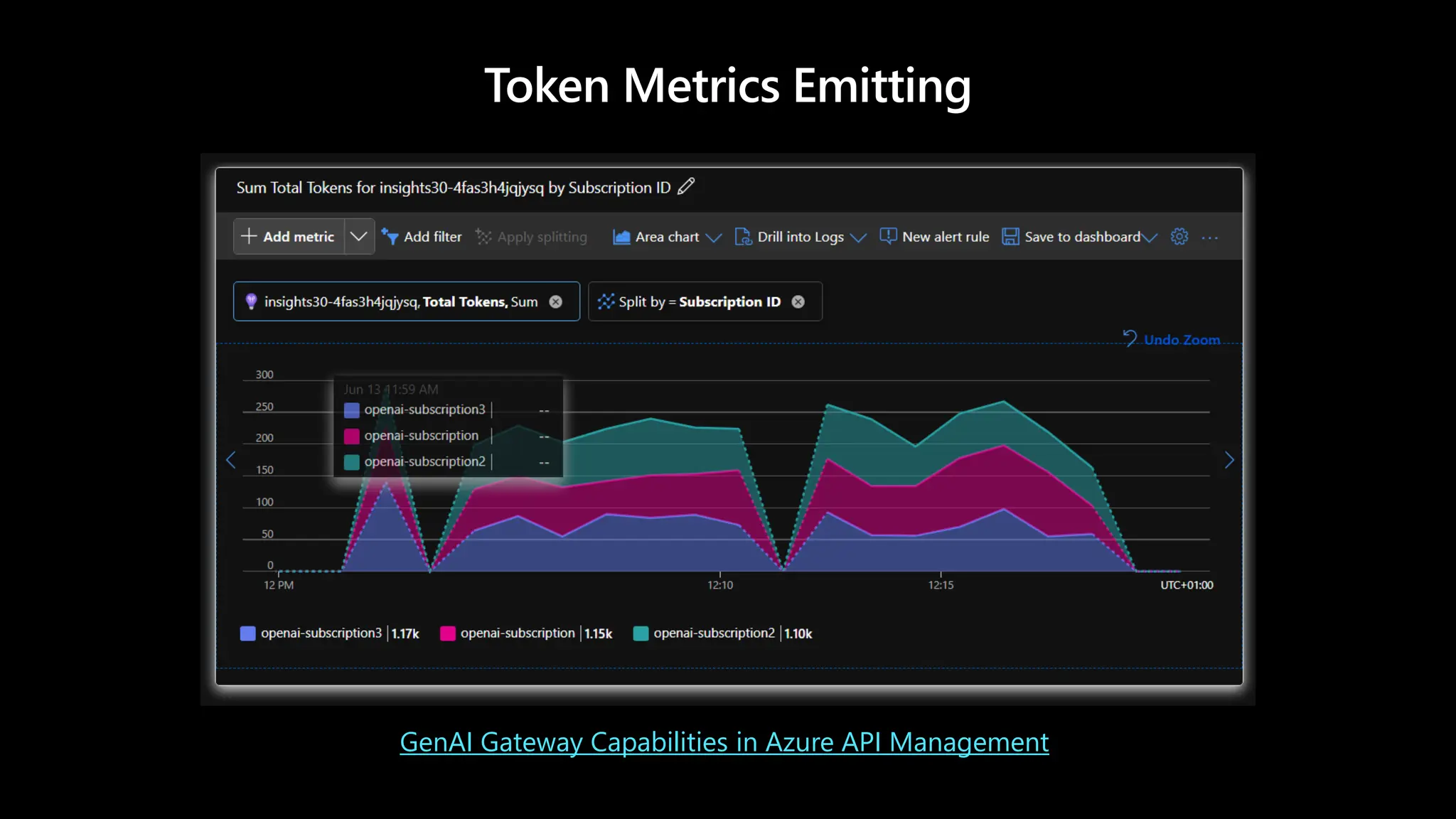
Token Metrics Emitting– Token Metric Policy
GenAI Gateway Capabilities in Azure API Management
Enforce limits perconsumer
• Manage and enforce limits per API consumer based on the
usage of API Tokens
GenAI Gateway Capabilities in Azure API Management
11.
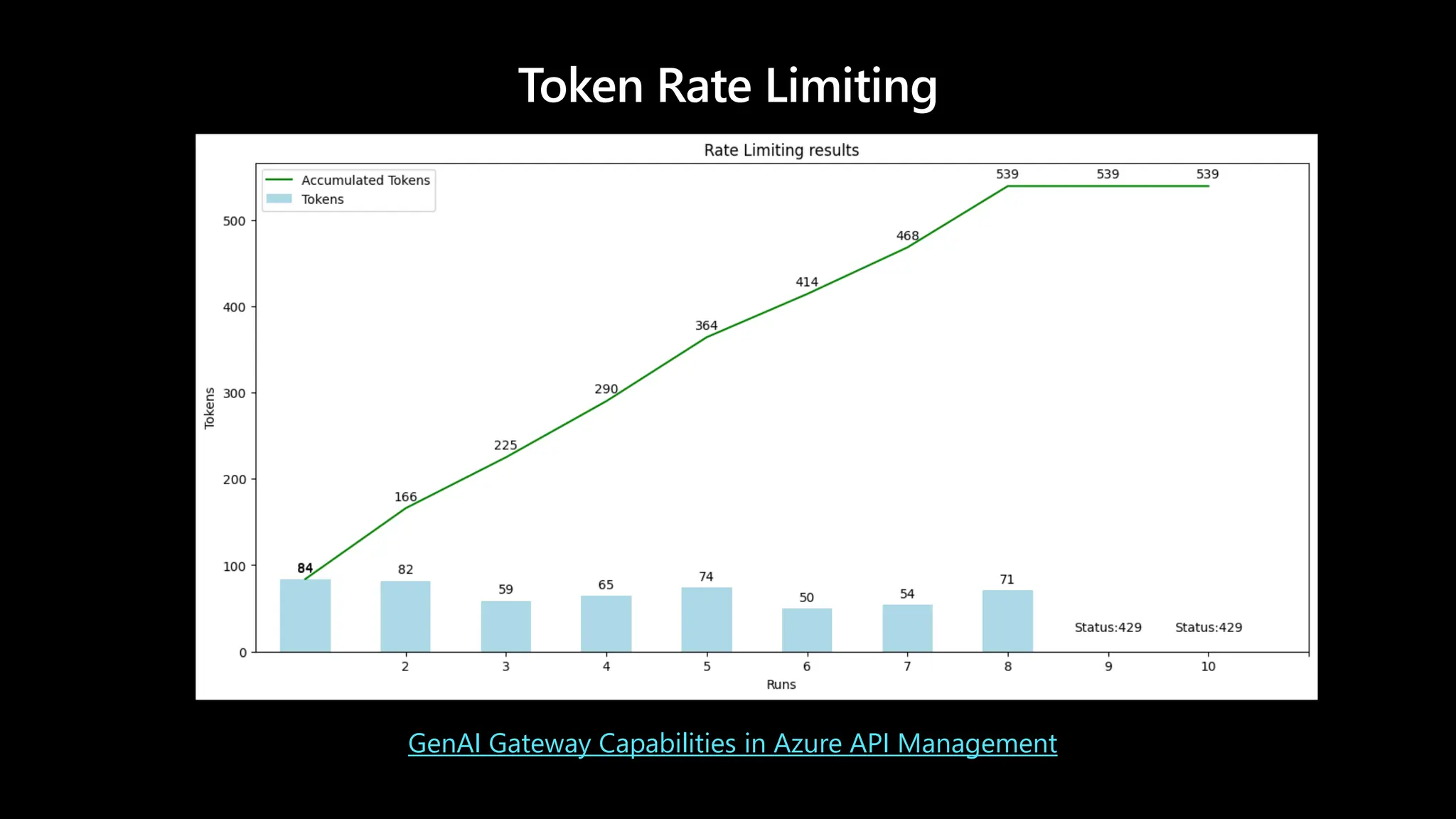
Token Rate Limiting– Token Limit Policy
GenAI Gateway Capabilities in Azure API Management
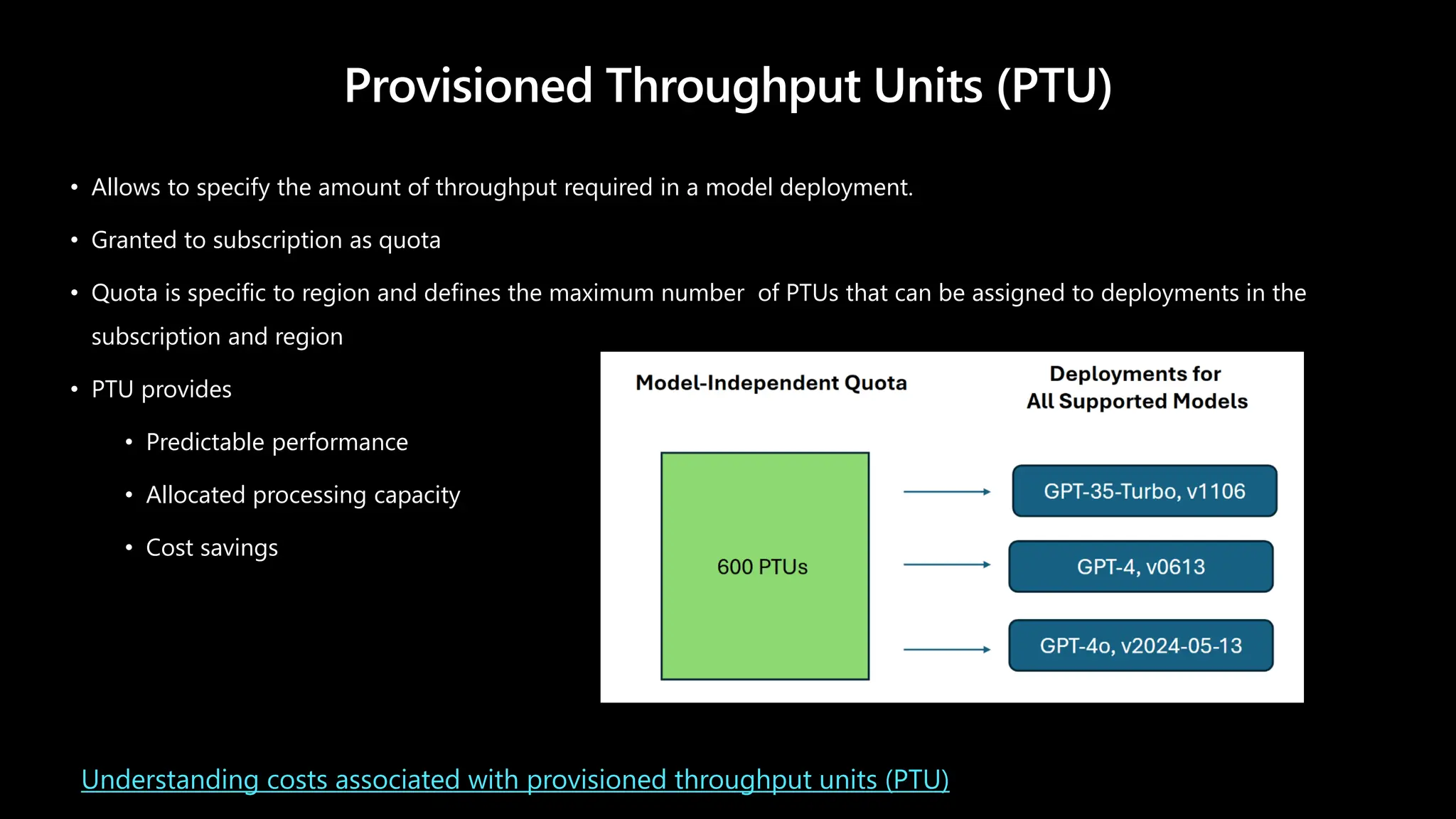
Provisioned Throughput Units(PTU)
• Allows to specify the amount of throughput required in a model deployment.
• Granted to subscription as quota
• Quota is specific to region and defines the maximum number of PTUs that can be assigned to deployments in the
subscription and region
• PTU provides
• Predictable performance
• Allocated processing capacity
• Cost savings
Understanding costs associated with provisioned throughput units (PTU)
14.
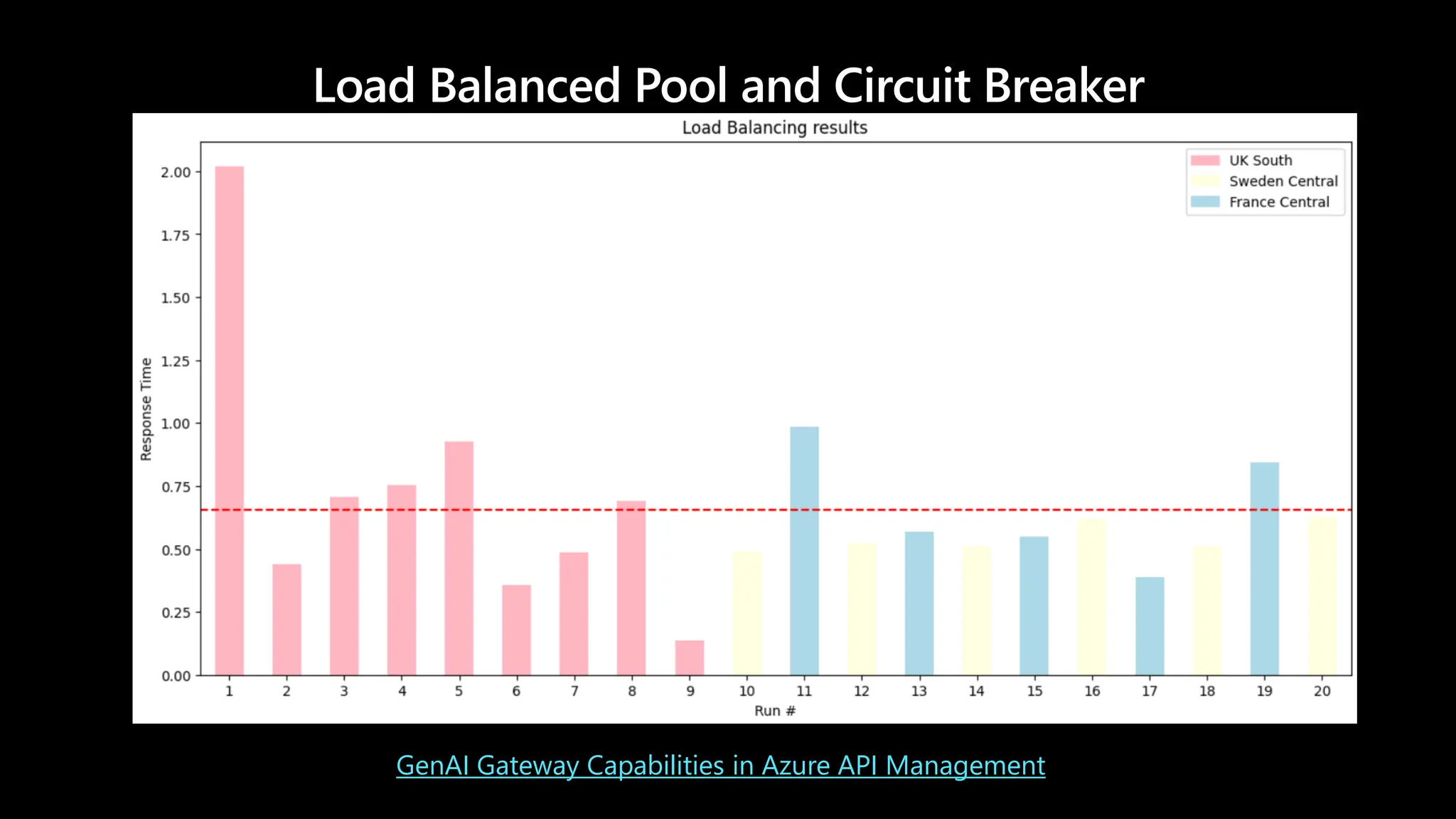
HA - LoadBalanced Pool and Circuit Breaker
• Helps to spread load across multiple Azure OpenAI endpoints
• Round-robin, weighted or priority based load distribution
strategy
GenAI Gateway Capabilities in Azure API Management
15.
Load Balanced Pooland Circuit Breaker
GenAI Gateway Capabilities in Azure API Management
16.
Load Balanced Pooland Circuit Breaker
GenAI Gateway Capabilities in Azure API Management
17.
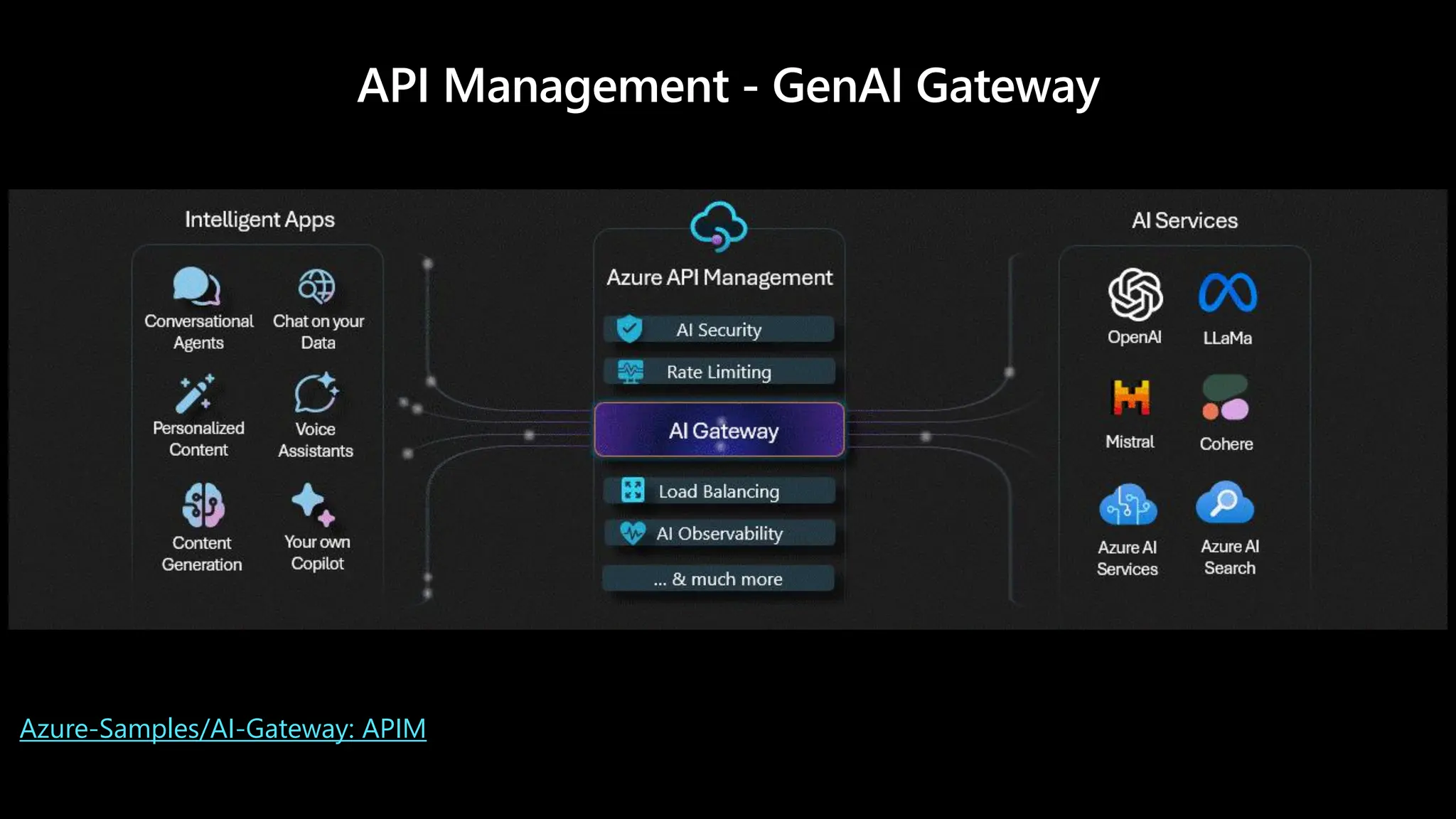
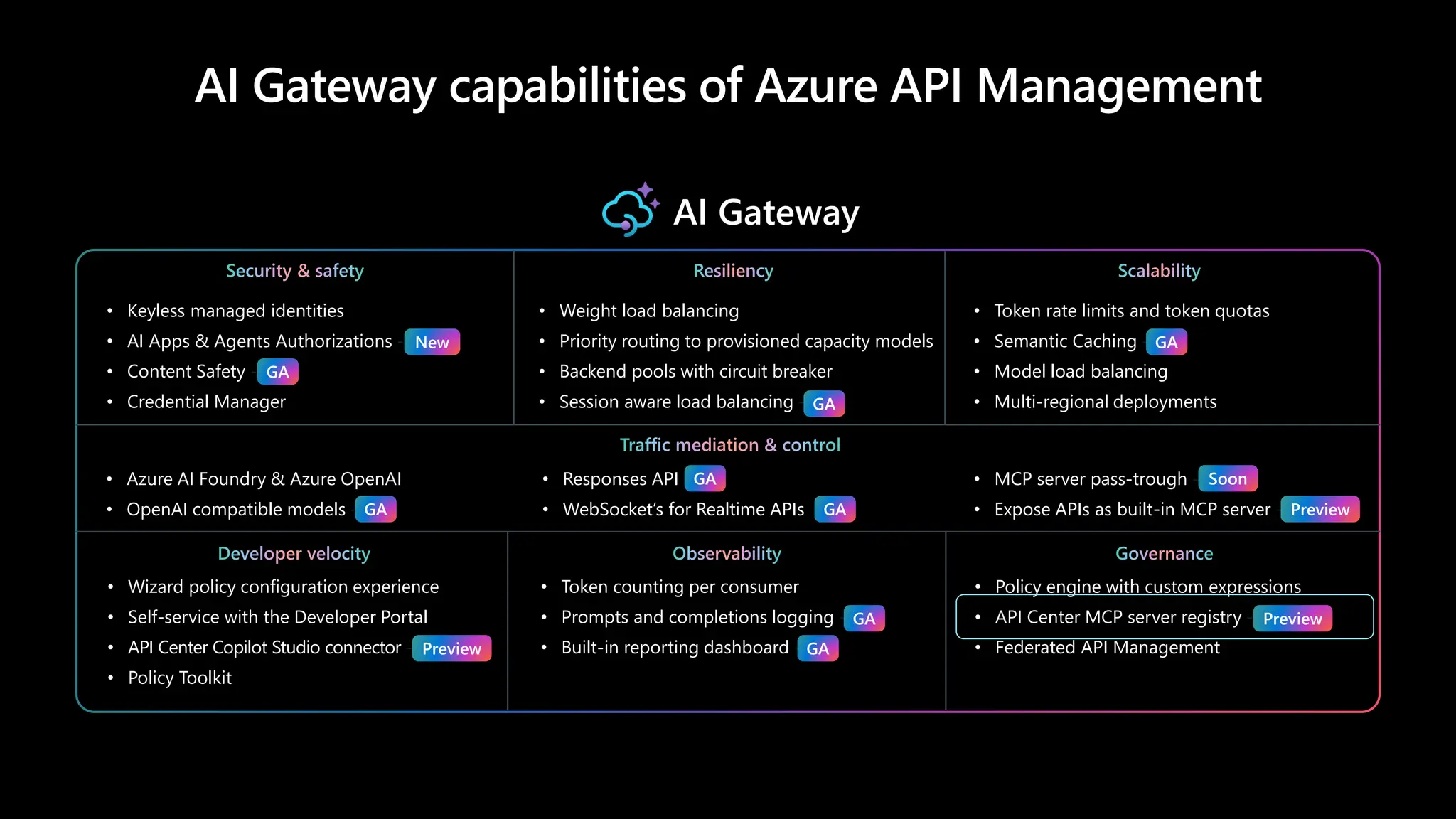
AI Gateway capabilitiesof Azure API Management
AI Gateway
Security & safety
• Keyless managed identities
• AI Apps & Agents Authorizations -New
• Content Safety -GA
• Credential Manager
Resiliency
• Weight load balancing
• Priority routing to provisioned capacity models
• Backend pools with circuit breaker
• Session aware load balancing -GA
Scalability
• Token rate limits and token quotas
• Semantic Caching -GA
• Model load balancing
• Multi-regional deployments
Traffic mediation & control
• Azure AI Foundry & Azure OpenAI
• OpenAI compatible models -GA
• Responses API -GA
• WebSocket’s for Realtime APIs
• MCP server pass-trough - Soon
• Expose APIs as built-in MCP server - Preview
Developer velocity
• Wizard policy configuration experience
• Self-service with the Developer Portal
• API Center Copilot Studio connector - Preview
• Policy Toolkit
Observability
• Token counting per consumer
• Prompts and completions logging -GA
• Built-in reporting dashboard -GA
Governance
• Policy engine with custom expressions
• API Center MCP server registry - Preview
• Federated API Management
GA
GA
GA Soon
GA
GA
GA
GA
Preview
Preview
GA
Preview
New
18.
Summary
• Track Tokenusage across multiple applications
• Emit Token Metrics policy
• Ensure single app doesn’t consume whole TPM quota
• Token Limit Policy
• Distribute load across multiple endpoints
• Backend pool load balancing and circuit breaker






















![[Workshop] API-driven Integration](https://cdn.slidesharecdn.com/ss_thumbnails/workshopapidrivenintegration1-200207075321-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Workshop] Managing the API lifecycle with Open Source Technologies](https://cdn.slidesharecdn.com/ss_thumbnails/workshopmanagingtheapilifecyclewithopensourcetechnologies1-190704142905-thumbnail.jpg?width=640&height=640&fit=bounds)












































