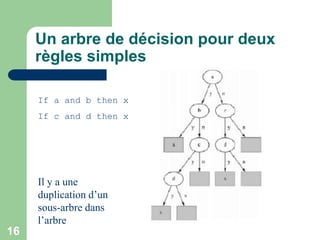
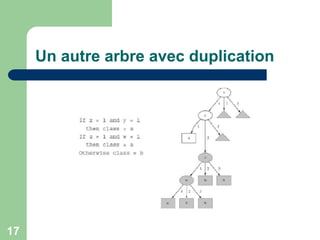
Les arbres de décision sont des structures de données utilisées pour la classification en divisant les données en sous-groupes plus purs en fonction des attributs. Les algorithmes tels que CART et C5.0 sont utilisés pour construire ces arbres, qui se basent sur le gain d'information pour choisir les attributs à chaque nœud. Toutefois, des défis existent, notamment la gestion des attributs numériques, l'optimisation contre le surapprentissage et la transformation des arbres en règles de classification.



![3
Arbres de décision
Une structure de données utilisée comme modèle pour la
classification [Quinlan]
Méthode récursive basée sur diviser-pour-régner pour créer des
sous-groupes (plus) purs (un sous-groupe est pur lorsque tous les
éléments du sous-groupe appartiennent à la même classe)
Construction du plus petit arbre de décision possible
Nœud = Test sur un attribut
Une branche pour chaque valeur d’un attribut
Les feuilles désignent la classe de l’objet à classer
Taux d’erreur: La proportion des instances qui n’appartiennent pas
à la classe majoritaire de la branche
Problèmes: Choix de l’attribut, terminaison](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-3-320.jpg)
![4
Algorithmes
Les deux algorithmes les plus connus et les plus
utilisés (l'un ou l'autre ou les deux sont présents dans
les environnements de fouille de données) sont CART
(Classification And Regression Trees [BFOS84]) et C5
(version la plus récente après ID3 et C4.5 [Qui93]).
[BFOS84] L. Breiman, J. H. Friedman, R. A. Olshen,
and C. J. Stone. Classification and regression trees.
Technical report, Wadsworth International, Monterey,
CA, 1984.
[Qui93] J. R. Quinlan. C4.5: Programs for Machine
Learning. Morgan Kaufmann, San Mateo, CA, 1993.](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-4-320.jpg)


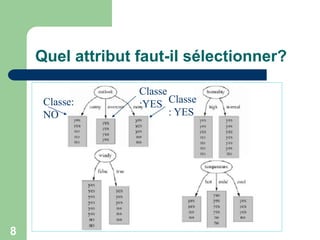
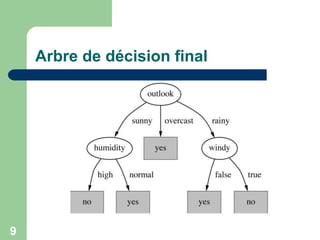





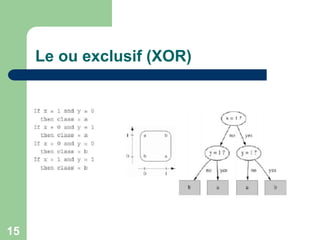





![24
Théorie de l’information
Besoin d’une méthode pour bien choisir l’attribut
[Shannon & Weaver, 1949]
Mesure de l’information en bits (pas dans le sens
ordinaire de bit – 0 ou 1)
– L’information peut être un décimal
A chaque étape,à chaque point de choix dans l’arbre,
on va calculer le gain d’information
– L’attribut avec le plus grand gain d’information est sélectionné
Méthode ID3 pour la construction de l’arbre de
décision](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-24-320.jpg)




![30
Première étape: Information Outlook
bits
Info
Info
Entropy
Info
Entropy
Info
971
.
0
])
3
,
2
([
)
6
.
0
log(
6
.
0
)
4
.
0
log(
4
.
0
2
log
1
])
3
,
2
([
)
6
.
0
,
4
.
0
(
])
3
,
2
([
5
3
,
5
2
])
3
,
2
([
bits
Info
bits
Info
971
.
0
])
2
,
3
([
0
.
0
])
0
,
4
([
Similarly:
Outlook =
“Sunny”
Outlook =
“Overcast”
Outlook =
“Rainy”](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-30-320.jpg)
![31
outlook
yes
yes
no
no
no
yes
yes
yes
yes
yes
yes
yes
no
no
sunny overcast rainy
info([2,3]) info([4,0]) info([3,2])
0.971 0.0 0.971](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-31-320.jpg)
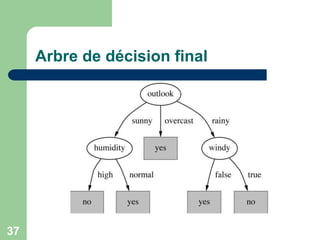
![32
Information pour l’arbre
])
2
,
3
([
14
5
])
0
,
4
([
14
4
])
3
,
2
([
14
5
])
2
,
3
[
],
0
,
4
[
],
3
,
2
([ Info
Info
Info
Info
La valeur de l’information pour l’arbre après
branchement est la somme pondérée des informations
de l’attribut de branchement.
Le poids est la fraction des instances dans chaque
branche.
Info([2,3],[4,0],[3,2]) = 0.693
Information pour l’arbre complet après le choix de
Outlook:](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-32-320.jpg)
![33
Information sans utiliser l’arbre
bits
Info
Entropy
Info
940
.
0
])
5
,
9
([
14
5
,
14
9
])
5
,
9
([
Outlook](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-33-320.jpg)
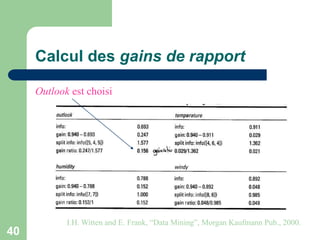
![34
Gain d’information pour Outlook
bits
outlook
gain
outlook
gain
Info
Info
outlook
gain
247
.
0
)
(
693
.
0
940
.
0
)
(
])
2
,
3
[
],
0
,
4
[
],
3
,
2
([
])
5
,
9
([
)
(
De même:
bits
windy
gain
bits
humidity
gain
bits
e
temperatur
gain
048
.
0
)
(
152
.
0
)
(
029
.
0
)
(
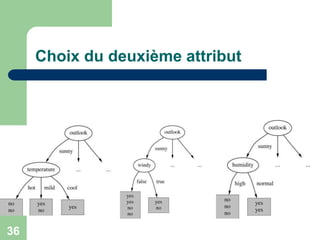
Outlook est
choisi](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-34-320.jpg)


![39
Information de branchement
577
.
1
])
5
,
4
,
5
([
14
5
,
14
4
,
14
5
])
5
,
4
,
5
([
Info
Entropy
Info
Première étape:](https://image.slidesharecdn.com/arbres3-230314125430-a1180ab7/85/arbres-de-decision-ppt-39-320.jpg)




























































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)




