Téléchargé 29 fois




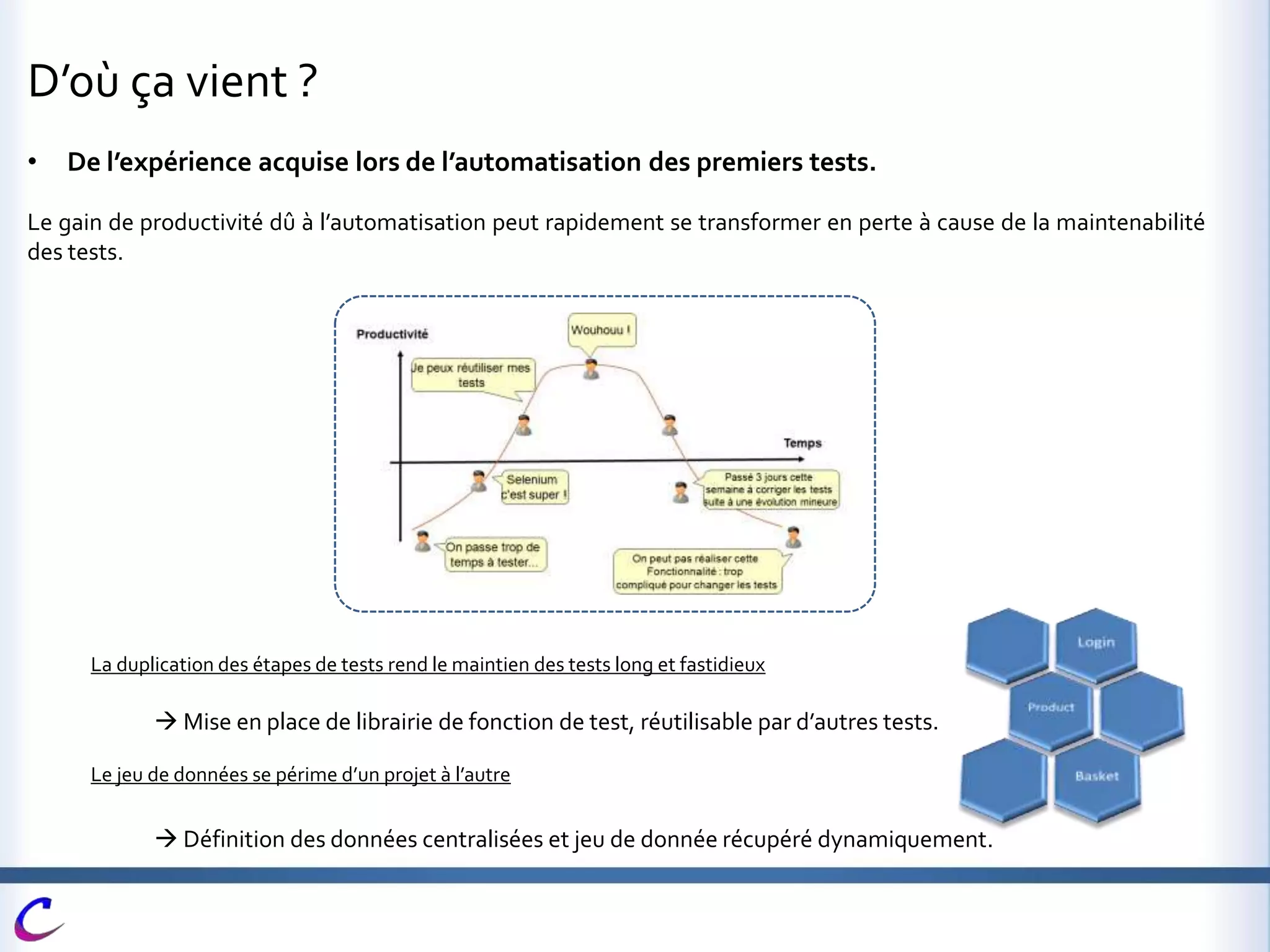





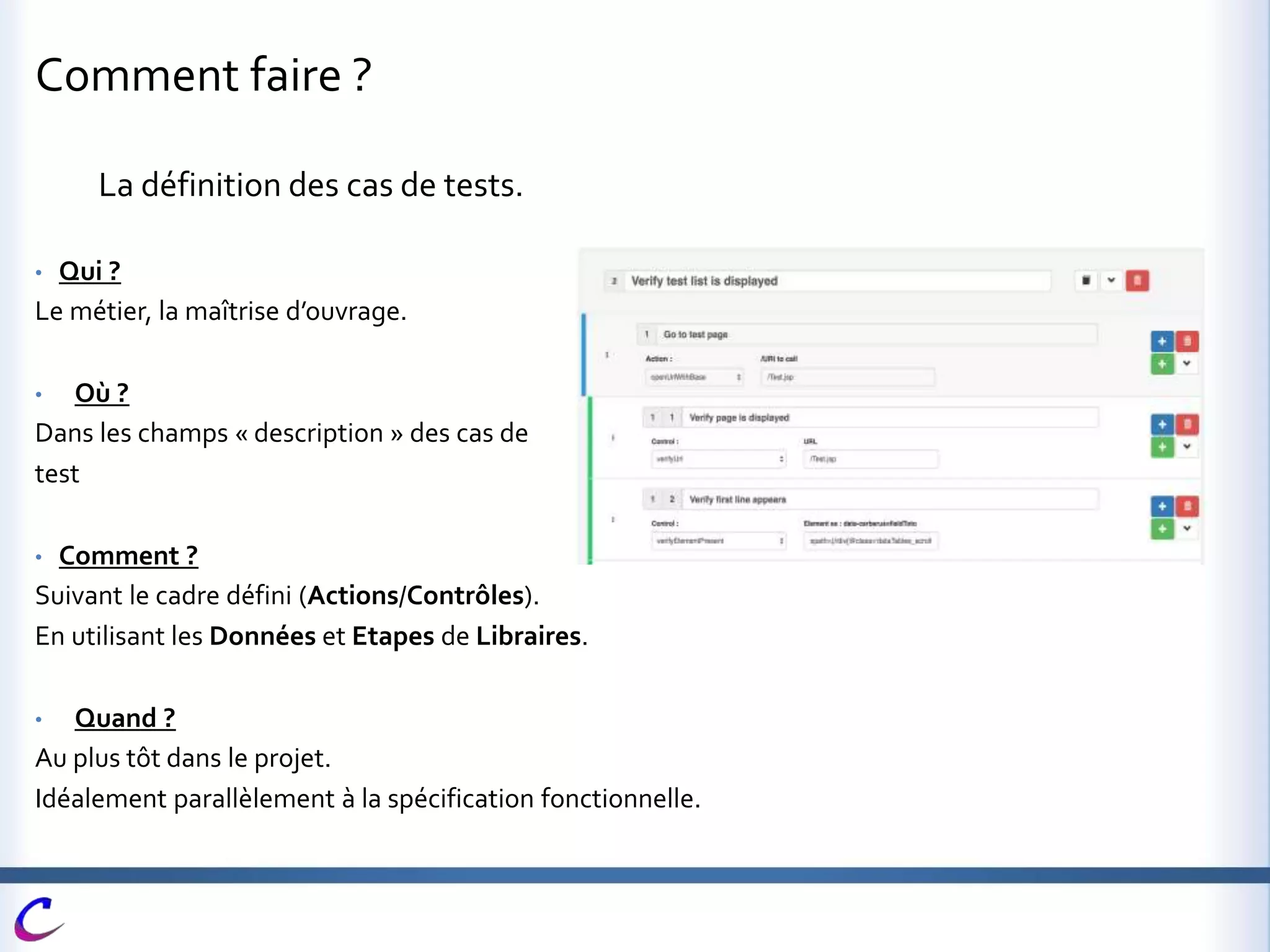

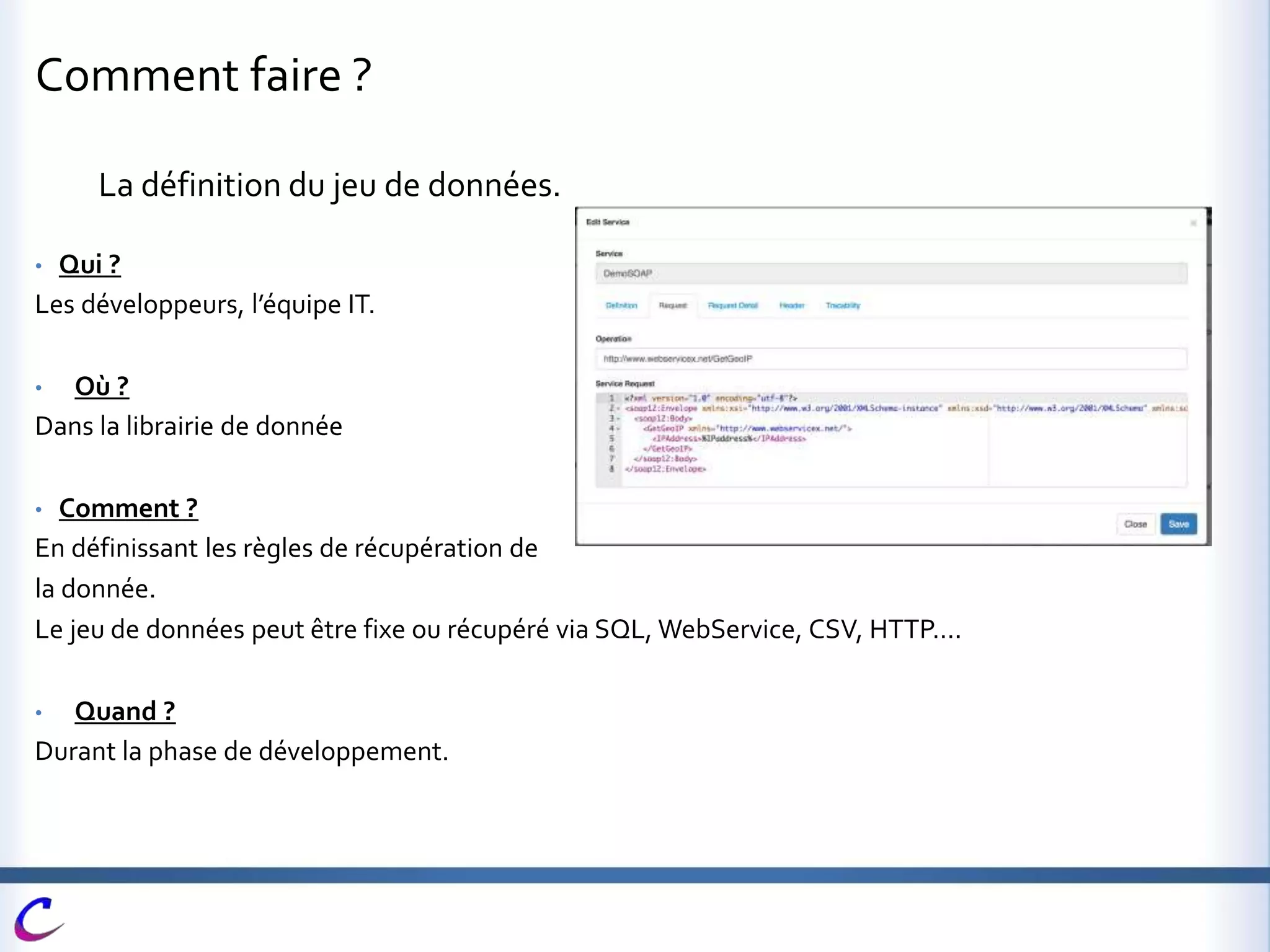

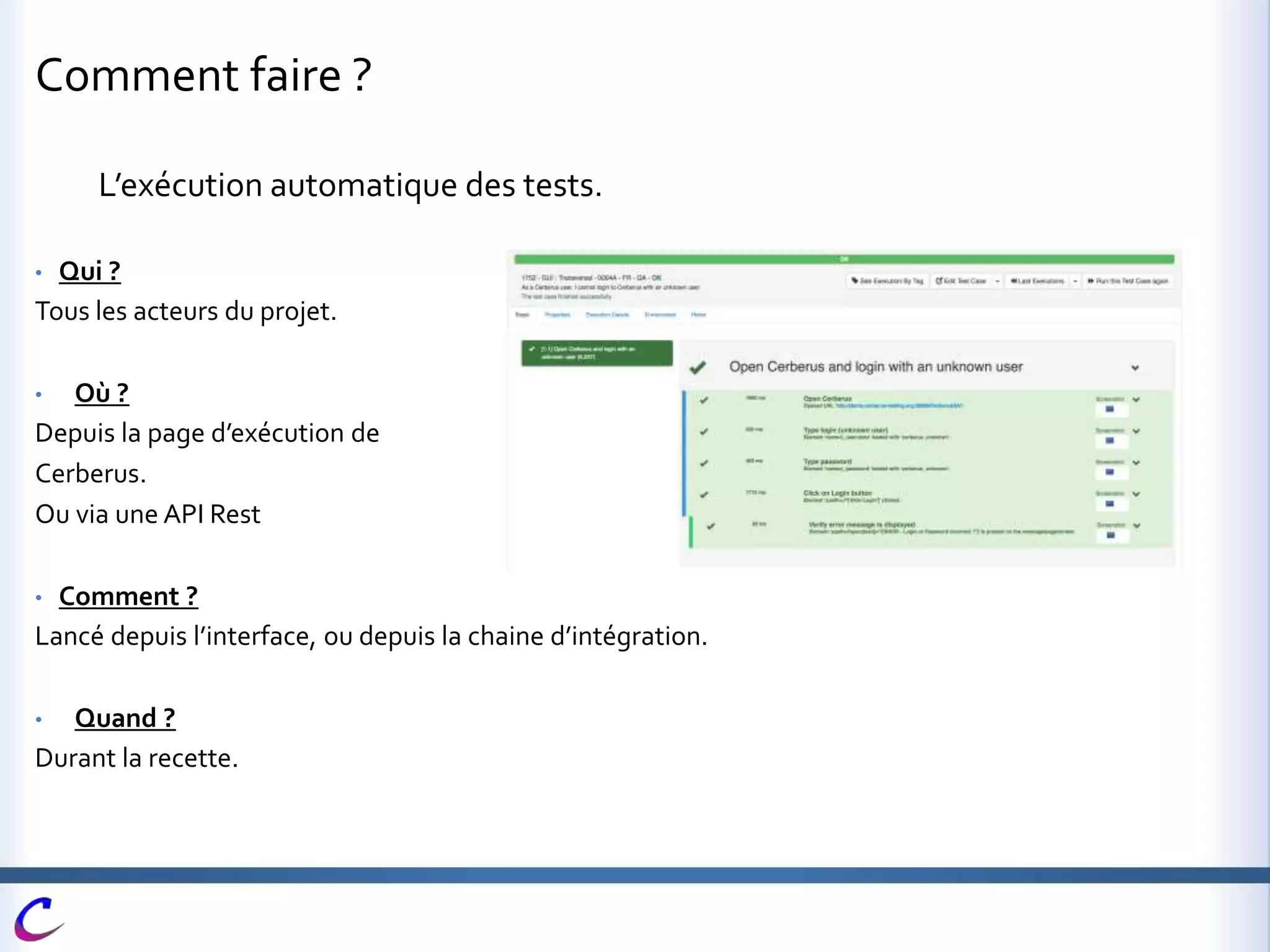












Cerberus est une application web open-source développée pour automatiser les tests dans des environnements variés et dans plusieurs langages, contribuant à maintenir une couverture fonctionnelle adéquate. Elle vise à intégrer des processus de test dès les phases de développement afin d'accélérer la qualification des livraisons et de limiter les risques liés aux mises en production. Des fonctionnalités avancées telles que l'automatisation, le pilotage de la recette, et l'intégration avec d'autres outils sont également mises en avant.















































