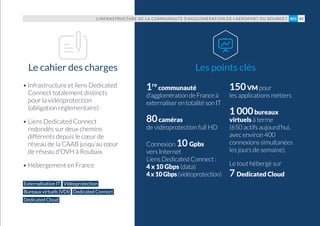
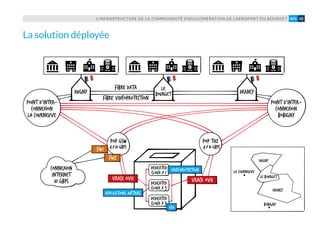
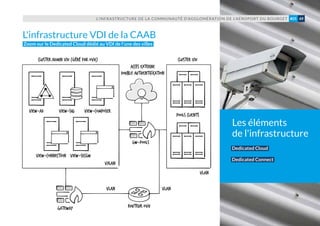
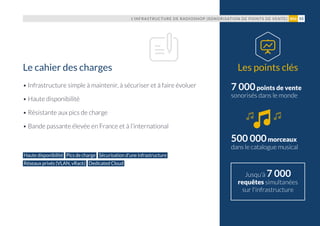
Le document présente un recueil d'études de cas sur les infrastructures déployées par OVH, illustrant diverses applications dans des domaines tels que les médias en ligne, l'expertise comptable, et le design sonore. Chaque cas montre comment OVH a aidé des entreprises à mettre en place des solutions scalables et performantes pour répondre à leurs besoins spécifiques. Le livre insiste sur l'importance d'une approche collaborative et d'une assistance à l'adoption des innovations technologiques.































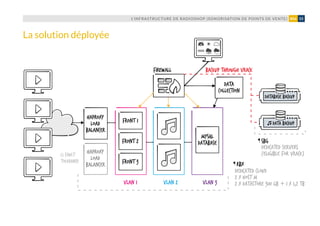
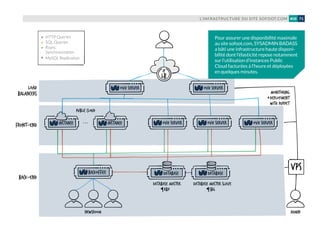
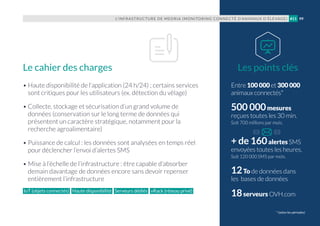
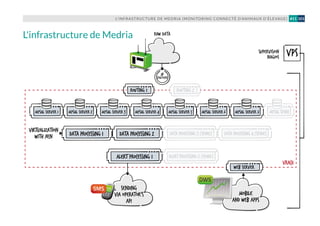
![L’INFRASTRUCTURE DES SITES ET APPLICATIONS MOBILES DE BFM, RMC ET 01NET (NEXTRADIOTV)36 #04
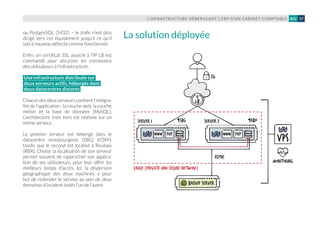
pour cela des 50 % de ressources dispo-
nibles). Couplée à la garantie apportée par
OVH.com de fournir sous quinze minutes
maximum un host de remplacement en
cas de défaillance hardware (sur lequel les
VM seront redistribuées par le DRS pour
rééquilibrer la charge), elle permet à l’in-
frastructure de bénéficier d’un très haut
niveau de disponibilité.
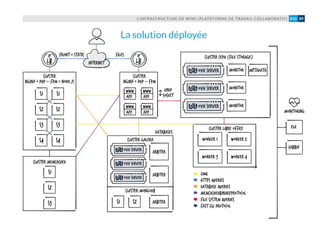
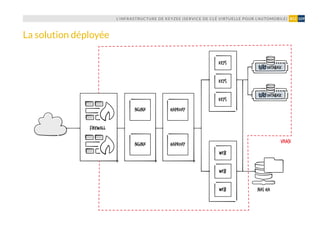
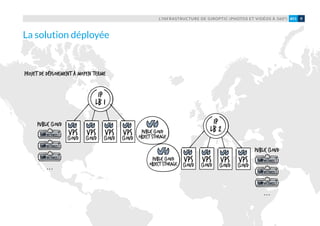
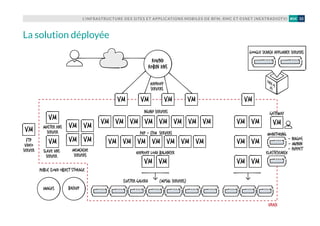
L’évolutivité de l’infrastructure, en l’occur-
rence sa capacité à grossir à chaud pour
absorber un trafic croissant (pics de charge
liés à une séquence d’actualité, ou tout
simplement croissance naturelle du trafic,
liée au développement de l’activité numé-
rique des médias hébergés), repose sur sa
structure multi-tiers et sur la possibilité
de créer en quelques minutes de nouvelles
VM. Configurées à l’aide de Puppet, elles
peuvent être déployées très rapidement
aux différents points de congestion de l’in-
frastructure (serveurs web Nginx par ex.).
Aujourd’hui, les ressources du Dedicated
Cloud de NextRadioTV sont dimensionnées
de façon à résister aux pics de charge sans
ajout de hosts supplémentaires. L’objectif,
dans les mois à venir, est de travailler sur
l’élasticité de la plateforme, en profitant de
la possibilité d’être livré d’une ressource
supplémentaire en cinq minutes, facturée à
l’heure. L’idée : « dynamiser » le nombre de
NextRadioTV effectue les purges des backups via des scripts.
Il y a encore plus simple : Public Cloud Object Storage permet
de définir une date de péremption pour les fichiers uploadés.
Le jour J, les fichiers sont alors détruits sans nécessiter
d’action particulière. Comment positionner l’expiration
à T+21 jours et la récupérer ?
$ curl -X POST endpoint/path/file.ext -H Content-
Type: application/json -H X-Auth-Token: token -H
X-Delete-After: 1814400
$ curl -X GET endpoint/path/file.ext -H Content-
Type: application/json -H X-Auth-Token: token -I
[...]
X-Delete-At: 1438584553
hosts de la plateforme, à la baisse comme à
la hausse, de façon à optimiser les coûts tout
en étant capable de résister à des charges
encore plus importantes.
Sécurité de l’infrastructure
Nousl’avonsévoquéplushaut,seuleslesVM
HAProxy, assurant le load balancing vers les
serveurs web, sont exposées sur le réseau
public (avec une autorisation pour le seul
port 80). Elles constituent la porte d’entrée
sécuriséedel’infrastructure, quis’apparente
ensuite à une zone démilitarisée (DMZ). Le
but est de sécuriser la partie production de
l’infrastructure. Fail2ban est utilisé sur les
connexions SSH, et l’implémentation d’un
système de prévention et détection d’intru-
sion est à l’étude (IPS + IDS).](https://image.slidesharecdn.com/12294cf6-d560-4ef9-af88-1c2cb4d3f1a5-161008082207/85/cookbook-fr-36-320.jpg)