Ce mémoire de fin de formation présente un projet sur l'administration en cloud computing et la virtualisation, réalisé au sein de l'entreprise Naftal. Il décrit les technologies de virtualisation, les solutions de cloud, ainsi qu'une étude comparative des différentes options disponibles. Le travail inclut également des scénarios pratiques d'application de ces technologies, ainsi qu'une analyse des besoins fonctionnels et de la supervision des ressources.










![1.9 Conclusion du Scénario 1a ………………………………………….82
2. Scénario lb : Gestion du stockage par bloc ………………………………..82
2.1. Schéma du scénario lb ……………………………………………....82
2.2. Composition de Cinder……………………………………………....83
2.3. Fonctionnement de Cinder…………………………………………...83
2.4. Problèmes rencontrés…………………………………………………84
2.5. Conclusion du Scénario 1b…………………………………………...85
III. Scénario 2 : Haute Disponibilité du Cloud Controller ……………………..85
1. Qu'est-ce que la HA ………………………………………………………..85
1.1 La HA Active/Active………………………………………………....86
1.2 La HA Active/Passive………………………………………………..86
1.3 L’IP flottante ou virtuelle…………………………………………….87
1.4 Services Stateless ou Statefull………………………………………..87
2. Scénario 2 : La HA au sein des AP] OpenStack……………………………88
2.1. Schéma du scénario 2a……………………………………………….88
2.2. But du Scénario…………………………………………………........89
2.3. Éléments physiques…………………………………………………..89
2.4. HA Active/Active avec HAProxy……………………………………89
2.5. HA Load Balancer avec KeepAlived………………………………...90
2.6. Bilan Scénario 2a…………………………………………………….90
3. HA SQL (Active/Active Statefull) ………………………………………...92
3.1. Schéma du Cluster SQL……………………………………………...92
3.2. Théorème du CAP……………………………………………………93
3.3. Gestion du Cluster SQL……………………………………………....94
IV. Scénario 3 : Collecte et entreposage des Logs………………………………95
1. Cahier des Charges………………………………………………………….95
2. Contraintes………………………………………………………………….95
3. Variantes de stockage de Logs………………………………………………96
3.1. Variante 1 : Stockage des Logs sous forme de fichiers……………….96
3.2. Variante 2 : Logstash-‐> ElasticSearch……………………………....98
3.3. Variante3 : Logstash-‐> Redis -‐> Logstash -‐>ElasticSearch……..102
3.4. Variante 4 : Abolition du serveur de Logs physique………………….103
3.5. Comparaison des quatre variantes et choix…………………………...103
3.6. Choix de la variante…………………………………………………..105](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-10-320.jpg)


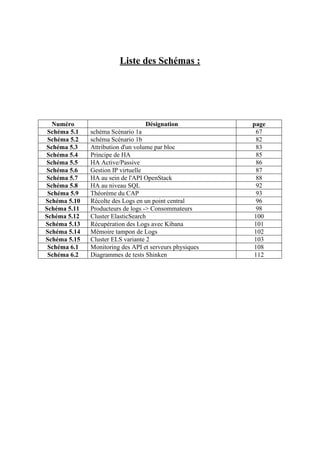


















![CHAPITRE 2 : Technologie de Virtualisation et de Cloud : Etat de L'art
13
Cependant du fait de l’empilement de couches d’abstraction et de l’impossibilité pour la
machine virtuelle d’accéder directement au matériel, les performances du système invité sont assez
éloignées de celles d’un système « natif ». Selon les implémentations, diverses solutions sont
utilisées pour accélérer les machines virtuelles, par exemple en passant la plupart des instructions
destinées au processeur virtuel directement au processeur physique3
. Cela accélère la vitesse de
calcul du système invité. Il reste cependant le problème des Entrées/Sorties (E/S), c’est à dire les
accès au disque, à la RAM, à la carte graphique, à la carte réseau, etc. D’une manière générale, on
appelle Entrées/Sorties (I/O ou Input/Output) tout ce qui consiste à transférer des informations ou des
données entre un périphérique et le système d’exploitation. Les E/S sont beaucoup plus dures à
optimiser, car chaque système d’exploitation a une façon propre de gérer cela. Il faut donc cohabiter
étroitement à la fois avec le système hôte pour l’accès réel au matériel et avec le système invité pour
que ses accès au matériel soient le plus rapide possible. Cela amène une plus grande complexité de
code, et une séparation en couches moins marquée que dans le modèle vu sur la figure 2.1. Cette «
rupture » dans le modèle en couches est exploitée par une autre technologie de virtualisation : le para
virtualisation.
3.2 La paravirtualisation :
La para virtualisation (para virtualization ou encore para-virtualization) est très proche du
concept de la virtualisation complète, dans le sens où c’est toujours un système d’exploitation complet
qui s’exécute sur le matériel émulé par une machine virtuelle, cette dernière s’exécutant au-dessus
d’un système hôte. Toutefois, dans une solution de para virtualisation, le système invité est modifié
pour être exécuté par la machine virtuelle. Les modifications effectuées visent à rendre le système
émulé « au courant » du fait qu’il s’exécute dans une machine virtuelle. De ce fait, il pourra collaborer
plus étroitement avec le système hôte, en utilisant une interface spécifique, au lieu d’accéder au
matériel virtuel via les couches d’abstraction. Au final, l’architecture obtenue est plus performante que
l’empilement de couches d’abstraction de la figure 2.2.
Le terme para-virtualisation a été mentionné pour la première fois dans [WSG02], où les
auteurs définissent la para virtualisation comme la modification sélective de certaines parties de
l’architecture virtuelle pour améliorer les performances, la réactivité sous forte charge et la simplicité
de conception.
L’idée du para virtualisation est toutefois plus ancienne que cela. Les premiers gros systèmes
utilisant une architecture de virtualisation avaient déjà une technologie similaire, dès les années
soixante-dix, même si elle n’avait pas de nom.
En pratique, un système paravirtualisé possède quelques pilotes de périphériques et sous-
systèmes modifiés, qui lui permettent de communiquer directement avec la machine virtuelle, sans
avoir passé par une couche d’abstraction pour parler au matériel virtuel. Les pilotes para virtualisés
échangent directement des données avec la machine virtuelle, sans avoir à passer par une émulation du
comportement du matériel. Les parties du système hôte généralement modifiées pour tirer profit de la
para virtualisation sont la gestion de la mémoire et la gestion des E/S. En effet, ce sont véritablement
les deux goulets d’étranglement d’un système virtualisé, du fait du nombre de couches d’abstraction à
traverser. Il est donc logique que les optimisations se portent là-dessus.
La figure 2.3 montre la structure d’une machine virtuelle et d’un système hôte supportant le
para virtualisation. Les pilotes non modifiés interagissent toujours avec le matériel émulé par la
machine virtuelle (rectangle bleu ciel), alors que les pilotes modifiés communiquent directement les
fonctions de la machine virtuelle (rectangle jaune)4
. La simplification qui en résulte communique
3
EuroCloud France. L'évolution maitrisée vers l’IaaS/PaaS. novembre 2011
4
Ignacio M. LlorenteBorja Sotomayor, Ruben S. Montero and Ian Foster](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-32-320.jpg)




























![CHAPITRE 3 : Etude comparative et choix de la solution
41
que Swift fonctionne l'environnement doit inclure au minimum le service d’identité
(keystone) avant de déployer le service de stockage d’objet9
.
- Heat: le service d'orchestration d'OpenStack (heat) permet d'orchestrer des tâches dans le
cloud computing. Il permet de plannifier et d'automatiser certaines tâches en gérant ls
ressources du cloud tel que les instances virtuelles, les adresses IP flottantes, les volumes, les
images, les groupes de sécurité, les utilisateurs. Il fournit également des fonctionnalités tels
que la haute disponibilité des instances, l'auto-scaling (extensibilité) des instances, en
décrivant via un template heat (HOT) qui est une sorte de langage, comment on souhaite
gérer les ressources du cloud.
- Ceilometer: le service de télémétrie d'OpenStack (ceilometer). Il permet de collecter
différentes métriques sur l'utilisation du cloud. Par exemple il permet de récolter le nombre
d'instances lancé dans un projet et depuis combien de temps. Ces métriques peuvent être
utilisées pour fournir des informations nécessaires à un système de facturation par exemple.
Ces métriques sont aussi utilisées dans les applications ou par d'autres composants
d'Openstack pour définir des actions en fonction de certains seuils comme avec le composant
d'orchestration.
Les services décrits plus haut sont les services les plus souvent utilisés quand on déploie un
cloud (en particulier avec OpenStack). Bien entendu OpenStack possède encore beaucoup
d'autres modules que pouvez installer (troove, ironic, sahara, designate, barbican, zaqar,
magnum, manila...). Tout cela dépend de ce que vous souhaitez faire. Et ceci est même un
des gros avantages qu'OpenStack possède par rapport à d'autres solutions de cloud computing
come VMWare vCloud, ou encore Microsoft System Center, qui non seulement sont des
solutions propriétaires et payantes, mais en plus ne s'installent pas par modules, c'est-à-dire
que vous n'avez pas réellement le choix sur ce que vous décidez d'installer ou pas. Par
exemple si vous souhaitez uniquement faire du cloud de stockage, avec OpenStack vous
aurez juste besoin d'installer le service de stockage Swift, sans avoir à déployer Nova, ou
encore Neutron, et ceci rendra votre environnement plus léger, par contre les autres solutions
intègre directement des fonctionnalités sans doute bien, mais dont vous n'avez pas forcément
besoin, et qui peut même rendre le déploiement complexe.
Voici un schéma illustrant, les relations entre les différents services d'OpenStack:
9
Eucalyptus. http://www.eucalyptus.com/. [15] Kvm. http://www.linux-kvm.org/.](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-61-320.jpg)






















![CHAPITRE 4 : Technologies de stockage et Haute Disponibilité
64
objectif : permettre à l'utilisateur d'utiliser un service le plus rapidement possible. La réparation
définitive doit donc être évitée car elle prend beaucoup plus de temps. Ce processus devra donc
mettre en place une solution de contournement du probleme.
5. Cluster haute disponibilités :
Un cluster haute disponibilité (par opposition à un cluster de calcul) est une grappe
d'ordinateurs dont le but est d'assurer un service en évitant au maximum les indisponibilités.
Voici une liste non exhaustive d'applications de clustering pour UNIX (fonctionnant
sous AIX, HP-UX, Linux ou Solaris) :
• Evidian SafeKit [archive] (load balancing, réplication temps réel et failover)
• HP MC/ServiceGuard pour HP-UX
• IBM HACMP
• Bull Application Roll-over Facility
• Symantec Veritas Cluster Server
• Open Source Linux Pacemaker (logiciel)
• OpenSVC [archive] (Logiciels Libres Gratuits)
• Oracle Solaris Cluster [archive] (ex SUN Cluster)](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-85-320.jpg)









![CHAPITRE 5 : Branche Fonctionnelle : Analyse et Spécification des Besoins
73
2. L’API envoie à Keystone le token reçu afin qu’il puisse vérifier sa signature grâce au
certificat req.pem.
1.4.4 Les Bases de Données :
Afin de stocker les différentes informations relatives à notre infrastructure, le Cloud
Controller possède un serveur de base de données MariaDB7, qui est un dérivé de MySQL. Pour
configurer OpenStack, je n’ai pas eu besoin d’effectuer des requêtes SQL, donc les contenus des
bases sont présents à titre indicatif. Le serveur va posséder deux bases de données :
▪ Base Keystone : Contient les utilisateurs, les tokens délivrées, ainsi que leurs périodes
de validités Aperçu des champs de la table user de la base Keystone :
MariaDB []> use keystone;
MariaDB [keystone]> describe user;
Field Type Null Key Default Extra
Id
Name
Extra
Password
Enabled
Domain_id
Default_project_id
Varchar (64)
Varchar (255)
Text
Varchar (128)
tinyint (1)
Varchar (64)
Varchar (64)
NO
NO
YES
YES
YES
NO
YES
PRI
MUL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
▪ Base nova : Contient toutes les informations des VMs, comme leurs informations
réseaux, leurs caractéristiques, et également la liste des computes nodes à disposition :
Comme par exemple la table « Computes_Nodes » :
MariaDB []> use nova;
MariaDB [nova]> describe compute_nodes ;](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-95-320.jpg)






![CHAPITRE 5 : Branche Fonctionnelle : Analyse et Spécification des Besoins
80
Les paquets ayant comme IP destination 129.194.184.5 sont redirigés vers l’adresse IP
192.168.1.2. IPTABLES va modifier l’adresse IP de destination par 192.168.1.2. Nous pouvons
le voir en faisant un TCPDUMP -i eth1 : 109.190.146.132.50875 > 192.168.1.2. Http 3
2. Le paquet sort du Network-Node via l’interface Eth1 et rentre dans le Compute Node,
mais avant d’arriver à la VM le paquet va être filtré par IPTABLES-Filtering qui a été
modifié à partir des Security-Group :
Nova-compute-inst-9 -p tcp -m tcp --dport 80 -j ACCEPT
Les paquets à destination du port 80 de la VM (nova-compute-inst-9) sont autorisés. Il
faut voir ces règles de Security comme des règles de Firewalls de types statefulls. Nous
contrôlons les paquets qui viennent du réseau Public en direction de la VM. Ces règles vont être
traduites en règles IPtables. Voici une capture d’écran concernant les règles IPtables de
l’interface Horizon pour autoriser l’ouverture du port 80:
Figure5.9 : Security-Group sous Horizon
3. En faisant un TCPDUMP dans la VM nous voyons le paquet possédant l’adresse source
du client :
109.190.146.132.52353 > 192.168.1.2. http
En conclusion nous voyons que toutes les règles de filtrage et de NAT doivent être
dynamiques car la VM ou le Floating peuvent changer d’adresse IP, il est primordial que les
différents services Nova-Network et Nova-Compute fassent remonter les informations et
puissent être contrôlés depuis un système centralisé : Nova-api.
1.8 Stockage par fichier des VMs :
Plusieurs architectures de stockage s’offrent à nous. Le stockage des disques virtuels des
VMs doit être externe à l’hyperviseur, afin d’avoir une unité de stockage centralisée, pour
pouvoir effectuer de la live-migration et faciliter la gestion des systèmes de stockages. Mais
l’OS de l’hyperviseur physique est lui stocké sur son propre disque dur. Le fait d’avoir un réseau
dédié (jaune) a l’avantage de pouvoir augmenter les débits grâce à l’activation par exemple des
Jumbo Frames.
3
] redhat. http://www.redhat.com/products/cloud-computing/cloudforms/](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-102-320.jpg)







![CHAPITRE 5 : Branche Fonctionnelle : Analyse et Spécification des Besoins
88
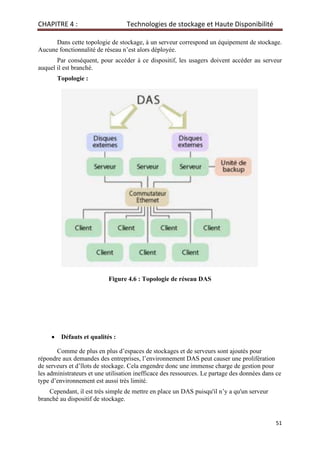
2. Scénario 2 : La HA au sein des AP] OpenStack :
Dans ce scénario, je vais implémenter la HA au sein de mon Cloud Controller sur
l’ensemble des API qui composent mon Infrastructure OpenStack :
▪ Interface Web Horizon
▪ API Nova
▪ API Cinder
▪ API Keystone
J’ai choisi d’installer les bases de données MySQL (Keystone DB, Nova DB et Cinder
DB) sur une autre machine physique, afin de ne m’attarder que sur la HA au niveau des requêtes
http avec les API. En effet la HA MySQL doit être traitée avec une approche différente. Pour
rappel, le contact d’une API se fait par l’envoi d’une requête http. L’API écoute sur un port
particulier.
Le schéma 5.7 résume la cohésion entres les différents éléments physiques au moment
où un administrateur envoie une requête sur l’interface web Horizon écoutant sur le port 80.
Pour mettre en place ce scénario, je me suis basé sur la documentation fournie par RedHat 15
et Mirantis 16 (société fournissant des services dans l’implémentation d’OpenStack).
2.1 Schéma du scénario 2a :
Schéma 5.7 : HA au sein de l'API OpenStack
2.2 But du Scénario :
Sans intégration de HA, avec l’infrastructure du Scénario 1, au moment où l’on stoppe
un des services d’API OpenStack tel que Nova API nous obtenons ce message d’erreur :
Horizon Port : 80
Nova-API Port : 8774
Cinder-API Port : 8776
Keystone Port : 5000
HAProxy
Eth0 10.2.4.101
KeepAlived
Horizon Port : 80
Nova-API Port : 8774
Cinder-API Port : 8776
Keystone Port : 5000
HAProxy
Eth0 10.2.4.106
KeepAlived
Cloud Controller 1
Cloud Controller 2
Utilisateur
Navigateur
Web
Echange Multicast
pour savoir où
est placé l'IP virtuelle
Redirection
depuis le HAProxy
vers les 2 API
disponibles
IP Virtuelle : 10.2.4.100](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-110-320.jpg)









![CHAPITRE 5 : Branche Fonctionnelle : Analyse et Spécification des Besoins
98
Comme nous pouvons le voir, les lignes générées dans ce fichier centralisent les Logs
de tous les services indexant leur journal d’événement. De plus le formatage des lignes est
généré en suivant le standard proposé par la RFC3164. Le message est constitué d’un
HEADER :
▪ Dec 1 03:27:37 : Timestamp, à quelle date et heure a été généré le message
▪ Network : La machine physique qui a généré le message
▪ Nova-network [10131] : Le nom du processus avec son numéro de PID qui a
généré cette ligne
Au final, les Logs sont centralisés sur notre serveur de Logs, mais sous la forme de
fichier. A ce stade, pour analyser le comportement des services OpenStack, nous sommes
toujours limités par la lisibilité des Logs. Pour ce faire, l’idéal serait de pouvoir les interroger
depuis une interface Web. De plus le stockage des Logs sous forme de fichiers est un grand
consommateur d’espace disque.
3.2 Variante 2 : Logstash-‐> ElasticSearch :
Schéma 5.11 : Producteurs de logs -> Consommateurs
Le schéma 5.11 représente la chaîne de traitement qui va acheminer les Logs contenus
sous forme de fichier jusqu’à une DB dédiée à ce stockage.
Cette variante permet :](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-120-320.jpg)















![114
Bibliographie :
Chapitre 2 :
[1] Alain-B. TCHANA .Système d'Administration Autonome Adaptable: application au Cloud,
novembre 2011
[2] Bhaskar Prasad Rimal, Eunmi Choi, and Ian Lumb. A taxonomy and survey of cloud
computing systems. In Proceedings of the 2009 Fifth International Joint Conference on INC,
IMS and IDC, NCM '09, pages 44_51, Washington, DC, USA, 2009. IEEE Computer Society.
[3] EuroCloud France. L'évolution maitrisée vers le IaaS/PaaS. novembre 2011
[4] Ignacio M. LlorenteBorja Sotomayor, Ruben S. Montero and Ian Foster.
[5] JunjiePeng, Xuejun Zhang, Zhou Lei, Bofeng Zhang, Wu Zhang, and Qing Li. Comparison
of several cloud computing platforms. In Proceedings of the 2009 Second International
Symposium on Information Science and Engineering, ISISE '09, pages 23_27, Washington,
DC, USA, 2009. IEEE Computer Society.
CHAPITRE 3 :
[1] le cloud computing une nouvelle filière fortement structurante, septembre2012
[2] Marvin Rambhadjan and Arthur Schutijser. SURFnet cloud computing solutions.
[3] Peter Sempolinski and Douglas Thain. A comparison and critique of eucalyptus, opennebula
and nimbus. In Proceedings of the 2010 IEEE Second International Conference on Cloud
Computing Technology and Science, CLOUDCOM '10, pages 417_426, Washington, DC,
USA, 2010. IEEE Computer Society.
[4] ThiagoDamascenoCordeiro, Douglas BritoDamalio, NadilmaCintra
[5] Vivansas.p.r.l.Cloud Computing Enjeux, Perspectives et Impacts métiers, septempre 2009
[6] WygwanLe Cloud Computing : Réelle révolution ou simple évolution ? Webographie
[7] Abicloud. http://community.abiquo.com/.
[8] Amazon web srrvice. http://aws.amazon.com/fr/.
[9] Eucalyptus. http://www.eucalyptus.com/.
CHAPITRE 4 :
[1] Microsoft. http://www.microsoft.com/.
[2] Microsoft. Windows azure http://www.microsoft.com/windowsazure/.
[3] Microsoft hyperv. http://www.microsoft.com/hyper-v-server/en/us/default.aspx.
[4] Nimbus. http://www.nimbusproject.org/.](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-137-320.jpg)
![115
CHAPITRE 5 :
[1] Openstack. http://www.openstack.org/.
[2] Opennebula. http://opennebula.org/.
[3] redhat. http://www.redhat.com/products/cloud-computing/cloudforms/.
[4] Salesforce. http://www.salesforce.com/fr/.
CHAPITRE 6 :
[1] Vmwarevsphare. http://www.arumtec.net/fr/outils-virtualisation/outils-devirtualisation/
vmware-vsphere-4.1/presentation-de-vmware-vsphere-4.1.
[2] Xen. http://www.xen.org/.
[3] Xen. http://wiki.xen.org/.](https://image.slidesharecdn.com/r8hpjsstwapcy7d7xw5g-signature-2d0e9cecdbf4b99e57b5c3069a7d9c171f9bdf7048ef439d27666f6d3ed85ae0-poli-200608010423/85/Deploiement-solution_ha_de_stockage_ceph_sous_une_plateforme_virtualisee_vsphere-openstack_-_bts_encadre_par_djebbari-138-320.jpg)









































