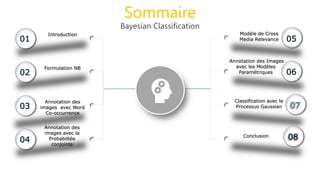
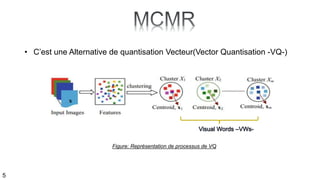
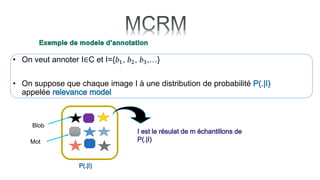
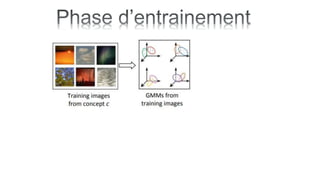
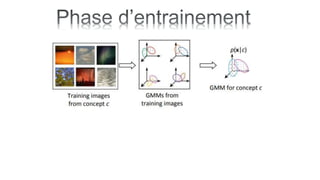
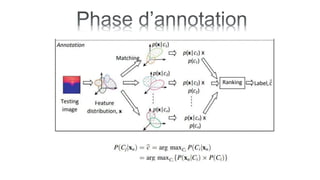
Le document traite de l'annotation d'images, en expliquant différentes méthodologies, y compris la segmentation en régions et l'utilisation de modèles paramétriques pour l'annotation. Il décrit également l'application du k-means pour segmenter des régions d'image et les principes de classification bayésienne et de mélange de gaussiennes. Les étapes de l'entraînement et de l'annotation sont abordées, soulignant l'importance de séparer ces processus.