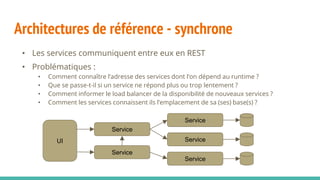
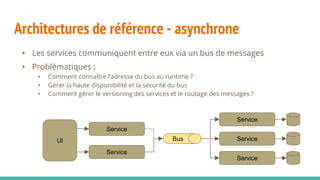
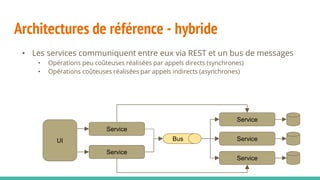
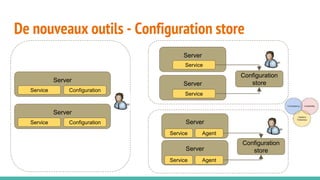
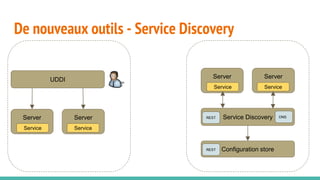
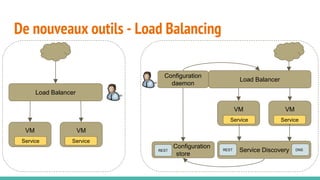
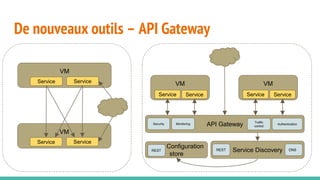
Le document traite des architectures de microservices, expliquant les approches synchrones et asynchrones pour la communication entre services, ainsi que les défis associés, tels que la gestion de l'adresse des services et la haute disponibilité. Il met en lumière la nécessité d'une conception axée sur la résilience, la dynamique des services, et l'importance des outils modernes pour le déploiement, la découverte de services, et la gestion des configurations. Enfin, il aborde de nouveaux modèles et pratiques pour assurer un fonctionnement robuste et scalable des applications distribuées.