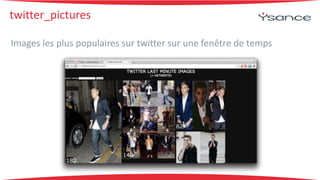
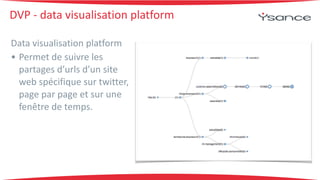
La soutenance présente un stage en big data axé sur l'utilisation de Hadoop et Spark. Un proof of concept a été réalisé pour l'extraction d'informations commerciales à partir de logs générés par des serveurs, avec un stockage sur Amazon S3. L'accent est mis sur le développement de compétences techniques pour répondre aux futurs besoins des clients dans un environnement big data en constante évolution.
















![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)








![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































