Introduction to Hidden Markov Models
•
2 j'aime•612 vues

This document provides an introduction to hidden Markov models (HMMs). It discusses that HMMs are a statistical machine learning technique that can model and explain implicit stochastic processes. The key elements of an HMM are presented as state space, transition model, prior probabilities, output symbol space, and sensor model. Common tasks performed by HMMs include learning models from training data, predicting state sequences, and evaluating observation probabilities. Applications discussed include information extraction from text documents and web pages.

Recommandé
Recommandé
Contenu connexe
En vedette
En vedette (20)
Similaire à Introduction to Hidden Markov Models
Similaire à Introduction to Hidden Markov Models (20)
Introduction to Hidden Markov Models
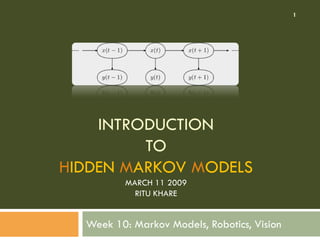
- 1. INTRODUCTION TO HIDDEN MARKOV MODELS MARCH 11 2009 RITU KHARE Week 10: Markov Models, Robotics, Vision 1
- 2. Order of Presentation Background Blending Statistics with Machine Learning Why do we need HMMs? What precisely is an HMM? The A B C of an HMM Elements of an HMM Notation of HMM Frequent Tasks performed by HMM Other Tasks performed by HMM Application: Information Extraction References 2
- 3. Background Hidden Markov Models (HMMs) fall under: Originated with Statistics, and evolved into full- fledged Machine Learning technique. Thus, HMM is a statistical machine learning technique. 3
- 4. Blending Statistics & Machine Learning Markov’s assumption: Current state depends only on a finite history of previous states. HMMs are used to model Markov’s processes (the processes that satisfy Markov’s assumption) It is important to distinguish between the process that produces a signal output: An HMM is used to “model” this. (Training) signal output : An HMM is used to “explain” this. (Testing) Statistics Machine Learning e.g. Signal Output: A complete and continuous spoken sentence Process that produces a Signal Output: The process of generating a spoken sentence. 4 q0 q1 q2
- 5. Why do we need HMMs? For processes that are: implicit and unobservable Human being speaking a sentence To model such processes The way a sentence is spoken is unobservable for a machine and the process of speaking one word after another is implicit. An HMM is used to model the process of generating a spoken sentence. To explain such processes An HMM, trained to model the process of generating a spoken sentence, can then be used for “explaining” the spoken sentence. I.e. to identify different words in the sentence. or to segment a signal into individual words 5
- 6. What precisely is an HMM? Formally defined as “a finite state automaton with stochastic state transitions and symbol emissions” (Rabiner, 1989). In an HMM (Kushmerick, 2002), there are 2 stochastic process: State Transitions: Transitions among states occur based on a fixed distribution Symbol Emissions: States emit symbols based on a fixed state-specific distribution First stochastic process is unobservable and can only be observed by second stochastic process. 6
- 7. The A B C of HMM: Elements q0 q1 q2 q3 q4 σ0 σ1 σ2 σ3 σ4 STATE (hidden) SYMBOL (observable) TRANSITION EMISSION 7
- 8. 5 Elements of an HMM State Space (size N): A finite set of states (q0, q1, q2 …qn) denoted by an unobservable state variable q . Transition Model (A): The set of transitions is captured in a state transition matrix. Each cell contains the state transition probability P (q → q’) of transitioning from a state q to q’. Prior Probability (π): The prior probability for each state qi is the probability that it is the start state i.e. the state of the process at time t=0. 8
- 9. 5 Elements of an HMM Output Symbol Space (size M): Vocabulary of output symbols is a set (σ0, σ1, …, σm). It is denoted by an observable evidence variable σ. A state can produce an observation symbol from this set. Sensor Model (B): Output emission probabilities P (q ↑ σ) denotes the state q’s probability of emitting the symbol σ. 9
- 10. Notations of HMM Rabiner(1989) writes the HMM as λ= (A, B, π) where A, B and π are the model parameters. q(t) denotes the state that model undergoes at time t. σ (t) denotes the symbol produced at time t In a first-order HMM, a q(t) depends only on q(t-1). σ(t) depends only on q(t). An HMM is thus describes as a two-step stochastic process (Fink, 2008): P(q(t)|q(1) q(2) …q(t-1)) = P(q(t)|q(t-1)) P (σ(t)| σ(1) … σ(t-1), q(1) …q(t))) = P(σ(t)| q(t)) q(t-1) q(t) σ(t) 10
- 11. Frequent Tasks Performed by HMM Learning Transition (A) and Sensor models (B) The transition and emission probabilities can be learnt from training data. HMMs have well established training algorithms (Seymore, McCallum, and Rosenfeld, 1999). Some systematic algorithms are(Freitag & Mccallum, 1999) : Baum Welch Viterbi Maximum Likelihood The process of determination of the best sequence of states given an observation symbol sequence. Also known as state recovery algorithm. It is an explanation of how a given observation symbol sequence was generated by an appropriate HMM The most popular method Viterbi algorithm Parameter Learning (Training) Sequence Prediction (Testing) 11
- 12. Other Tasks performed by HMM Evaluating Observation Sequence Probability: Evaluation of probability of a sequence of observation given a specific HMM (Fink, 2008) is another popular problem. The forward algorithm is used to calculate the probability of generating a string ( a sequence of observations ) given a specific model. Topology Structure Modeling: The decisions related to the number of states, and the possible state transitions, make up the topological structure of an HMM. Structure learning is another research area in itself. Seymore et al.(1999) present a method for learning model structure from training data. Miscellaneous Problems: Filtering (the probability of having a state q(t), given a sequence of observations till current time t) Prediction (the probability of having a state q (t+k), given a sequence of observations till current time t) Smoothing or Hindsight (the probability of having a state q (k) (k<t), given a sequence of observations till current time t ) 12
- 13. Applications: Information Extraction HMM started to be used for Speech Recognition in 1970. From last decade, they have grown popular among Information Extraction community. For Traditional Documents Sparse Extraction : The documents in which target fields are sparsely located require sparse extraction techniques. One HMM per target field is to be created (Freitag and McCallum, 1999). Dense Extraction: The documents, in which the target fields are densely located, require dense extraction techniques. Generally, one HMM for the entire document is created and different fields are modeled as different states (Seymore, McCallum, and Rosenfeld, 1999). 13
- 14. Applications: Information Extraction For Web Pages Generalized HMM: Zhong and Chen (2006) have generalized an HMM to extract blocks from Web pages. They model a page as a sequence of blocks; traverse the page in a 2-D order as a tree using depth first search; and perceive the emitted observation as a composite symbol having multiple attributes with individual symbol values. Synset-based HMM: Tran-Le et al. (2008) perform text segmentation to extract important fields from result pages of commercial websites. The domain is camera product information and the target fields are price, product name, resolution etc. They use Synset-based HMM wherein the emission probability of a particular state is distributed over the elements in a set of synonyms of a word (in the symbol space). For Deep Web Search Interfaces!!!! ( 2009 To be continued … Final Week) 14
- 15. References Fink, G. A. (2008). Markov models for pattern recognition: From theory to applications (hardcover) Springer. Freitag, D., & Kushmerick , N. (2000). Boosted wrapper induction. Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, Austin, Texas. 577 - 583. Freitag, D., & Mccallum, A. K. (1999). Information extraction with HMMs and shrinkage. AAAI-99 Workshop on Machine Learning for Information Extraction, Orlando, Florida. 31-36. Kushmerick , N. (2002). Finite-state approaches to web information extraction. 3rd Summer Convention on Information Extraction, 77-91. Leek, T. R. (1997). Information extraction using hidden markov models. (Masters, Department of Computer Science and Engineering, Univ. of California, San Diego). Rabiner, L., R. (1989). A tutorial on hidden markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), 257–286. Russell, S., J., & Norvig, P. (2002). Artificial intelligence: Modern approach Prentice Hall. Seymore, K., Mccallum, A. K., & Rosenfeld , R. (1999). Learning hidden markov model structure for information extraction. AAAI 99 Workshop on Machine Learning for Information Extraction, Orlando, Florida. 37- 42. Tran-Le, M. S., Vo-Dang , T. T., Ho-Van , Q., & Dang, T. K. (2008). Automatic information extraction from the web: An HMM-based approach. Modeling, simulation and optimization of complex processes (pp. 575-585) Springer Berlin Heidelberg. Zhong, P., & Chen, J. (2006). A generalized hidden markov model approach for web information extraction Web Intelligence, 2006. WI 2006, Hong Kong, China. 709-718. 15