Le document traite des algorithmes de tri, en expliquant plusieurs méthodes, dont le tri à bulles, le tri par sélection, le tri par insertion, le tri fusion et le tri rapide. Chaque algorithme est décrit avec son principe de fonctionnement et sa complexité en temps. Les algorithmes de tri sont cruciaux pour organiser efficacement les données et améliorent la performance des algorithmes de recherche.











![2.4 Tri par insertion
(Insertion-sort)
12
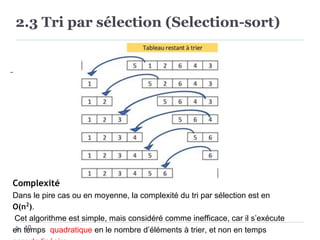
Exemple
Voici les étapes de l’exécution du tri par insertion sur le tableau
[6,5,3,1,8,7,2,4]. Le tableau est représenté au début et à la fin de
chaque itération.
i = 1 :[6,5,3,1,8,7,2,4] →
[5,6,3,1,8,7,2,4]
i = 2 : [5,6,3,1,8,7,2,4] →
[3,5,6,1,8,7,2,4]
i = 3 : [3,5,6,1,8,7,2,4] →
[1,3,5,6,8,7,2,4]
i = 4 : [1,3,5,6,8,7,2,4] →
[1,3,5,6,8,7,2,4]
i = 5 : [1,3,5,6,8,7,2,4] →](https://image.slidesharecdn.com/algorithmes-de-tri-insertion-rapide-fusion-241207162405-284fcd8e/85/algorithmes-de-tri-insertion-rapide-fusion-pdf-12-320.jpg)







![2.6 Tri rapide
(quick-sort)
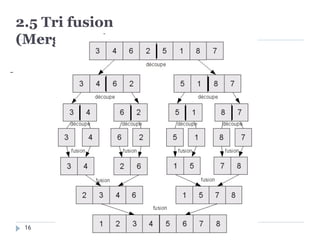
Le principe du tri rapide est le suivant, étant donné un tableau de T[1,
..., n] :
– si n=1,retourner le tableauT.
– sinon :
• Choisir un élément du tableau, élément que l’on nomme ensuite
pivot.
• Placer le pivot à sa position finale dans le tableau : les
éléments plus petits que lui sont à sa gauche, les plus grands à
sa droite.
• Trier, toujours à l’aide de cet algorithme, les sous-tableaux à
gauche et à droite du tableau.
(plus de fusion !)
Pour que cette méthode soit la plus efficace possible, il faut que le pivot
coupe le tableau en deux sous-tableaux de tailles comparables.
22](https://image.slidesharecdn.com/algorithmes-de-tri-insertion-rapide-fusion-241207162405-284fcd8e/85/algorithmes-de-tri-insertion-rapide-fusion-pdf-22-320.jpg)

![2.6 Tri rapide
(quick-sort)
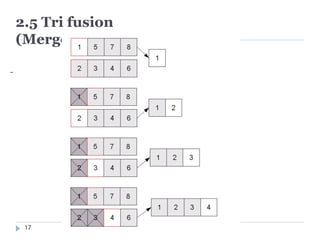
Exemple
Par exemple, pour trier [101, 115, 30, 63, 47, 20], on va avoir
les itérations suivantes :
[101(i), 115, 30(p), 63, 47, 20(j)]
[20, 115(i), 30, 63, 47(j), 101]
[20, 115(i), 30, 63(j), 47, 101]
[20, 115(i), 30(j), 63, 47, 101]
[20,30(j), 115(i), 63, 47, 101]
Et on relance le processus sur les deux sous tableaux [20] et
[115, 63, 47, 101]
[115(g), 63(p), 47, 101(d)]
Complexité
En moyenne et en meilleurs des cas, la complexité est en O(n
log(n))
24](https://image.slidesharecdn.com/algorithmes-de-tri-insertion-rapide-fusion-241207162405-284fcd8e/85/algorithmes-de-tri-insertion-rapide-fusion-pdf-24-320.jpg)






























































