Télécharger pour lire hors ligne



![2008 3
(1)
• [ ] (905 –1205): (905 )
(1205) 300 9500
( , 1998, p. 226)
• [ ]
( , 1977)
(Goodenough, 1991, p. 43)
85
...](https://image.slidesharecdn.com/ch2008slide01-111211080606-phpapp02/85/Ch2008slide01-3-320.jpg)










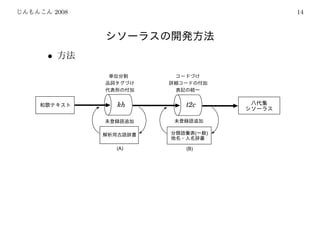









![2008 24
BG-01-4300
BG-01-43
BG-01-4300
BG-01-4310
BG-01-4320
BG-01-4321
BG-01-4322
BG-01-4323
BG-01-4330
BG-01-4340
BG-01-4350
BG-01-4360
BG-01-4370
% grep "BG-01-43[1-5]" hachidaishu.db](https://image.slidesharecdn.com/ch2008slide01-111211080606-phpapp02/85/Ch2008slide01-24-320.jpg)




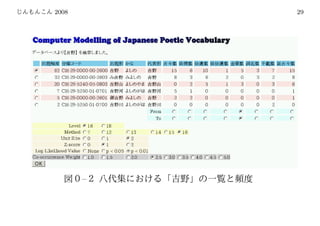






Le document contient des références et des notes en lien avec des protocoles et des systèmes de code, ainsi que des tableaux de données. Il semble aborder des aspects techniques concernant le traitement de données et les identifiants de base de données. Les informations sont éparpillées et manquent de structure narrative claire.







































