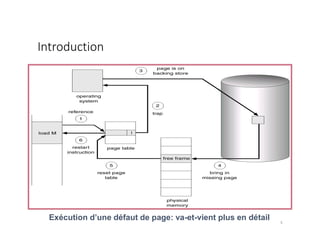
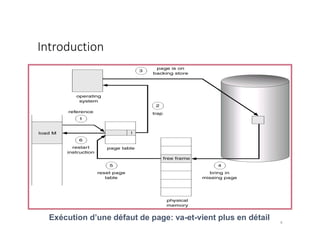
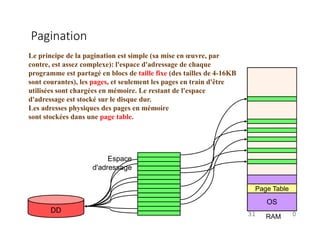
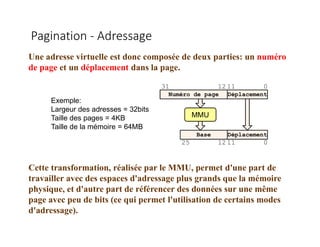
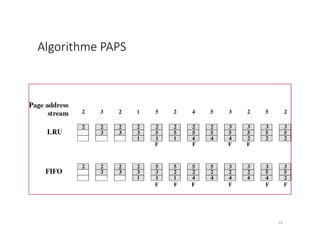
Le document traite de la gestion de la mémoire à travers des algorithmes de remplacement de pages et de pagination. Il explique les concepts de mémoire logique et physique, le processus de défaut de page, et les différentes méthodes pour choisir quelle page évincer afin de minimiser le taux de défauts. Les algorithmes LRU (Least Recently Used) et FIFO (First-In, First-Out) sont analysés en détail en termes de mise en œuvre et de performance.