Presentation des outils traitements distribues
•Télécharger en tant que PPTX, PDF•
0 j'aime•146 vues

Comparaison des outils de traitements distribués

Recommandé
Recommandé
Contenu connexe
Tendances
Tendances (20)
Similaire à Presentation des outils traitements distribues
Similaire à Presentation des outils traitements distribues (20)
Plus de Lê Anh
Plus de Lê Anh (19)
Presentation des outils traitements distribues
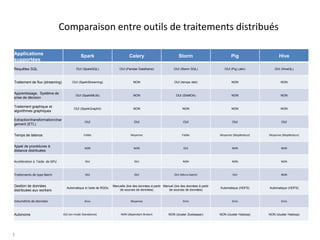
- 1. Comparaison entre outils de traitements distribués 1 Applications supportées Spark Celery Storm Pig Hive Requêtes SQL OUI (SparkSQL) OUI (Pandas Dataframe) OUI (Storm SQL) OUI (Pig Latin) OUI (HiveQL) Traitement de flux (streaming) OUI (SparkStreaming) NON OUI (temps réel) NON NON Apprentissage, Système de prise de décision OUI (SparkMLlib) NON OUI (SAMOA) NON NON Traitement graphique et algorithmes graphiques OUI (SparkGraphX) NON NON NON NON Extraction/transformation/char gement (ETL) OUI OUI OUI OUI OUI Temps de latence Faible Moyenne Faible Moyenne (MapReduce) Moyenne (MapReduce) Appel de procédures à distance distribuées NON NON OUI NON NON Accélération à l’aide de GPU OUI OUI NON NON NON Traitements de type Batch OUI OUI OUI (Micro-batch) OUI NON Gestion de données distribuées aux workers Automatique à l’aide de RDDs Manuelle (lire des données à partir de sources de données) Manuel (lire des données à partir de sources de données) Automatique (HDFS) Automatique (HDFS) Volumétrie de données Gros Moyenne Gros Gros Gros Autonome OUI (en mode Standalone) NON (dépendant Broker) NON (cluster Zookeeper) NON (cluster Hadoop) NON (cluster Hadoop)
- 2. Apache Spark • Tout calcul en mémoire – Pros: les traitements qui ont besoin de la vitesse – Cons: les besoins en mémoire doivent être pris en compte • Données distribuées RDD (Resilient Distributed Datasets) – Pros: gérer et optimiser les partitions de données distribuées aux machines de travail d’une approche paresseuse – Cons: une augmentation significative de la latence afin de préparer les données distribuées • Types de données supportés – Traiter les données structurées avec Spark SQL – Traiter les données issues de graphes (nœuds, arrêtes) grâce à Spark Graph X – Traiter les données non-structurées avec ses fonctions Map(), Filter(), Reduce() sur RDD • Tolérance – tolérance aux pannes basée sur les informations de lignage (un arbre des transformations et actions DAG) – Une répartition perdue va être recalculée à partir d’une RDD originale • Modèle de déploiement – Propre mécanisme de clusterisation (en mode Standalone) ou pouvoir l’intégrer à un cluster Hadoop • Langages de programmation supportés – Java, Python, Scala, R • Cas d’utilisation – Traitement une grande quantité de données de type Batch – Traitement de flux en temps réel (Spark Streaming) – Utilisation de Spark pour l'analyse avancée des données et la science des données • Apprentissage automatique (Spark MLlib) • Algorithmes itératifs grâce à la mécanisme de cacher les résultats intermédiaires (aux nœuds de DAG) • Analyse interactive des données grâce à la mode Spark Shell • Inconvénients – Les besoins de mémoire vivant doivent être pris en compte – Latence significative - 00/00/00 - Pied de page (titre ou service…) Page 2
- 3. Celery • Traitement en mode asynchrone – File d’attente de tâches distribuées – Rendre l’interface utilisateur plus réactive sans attente • Transmission de données aux machines de travail (workers): – Il faut avoir en quelque sorte transférer de manière indépendante les données à la machine de travail d’abord, puis d’exécuter le code à traiter ces données • Flexible: – Programmable de répartition des calculs – Repartir les données à traiter sur chaque worker • Modèle de déploiement: – Broker (ex: Redis, RabitMQ) • Tolérance – Une tâche est gardée dans la liste d’attente jusqu’à elle est finie avec succès par un worker – Si un worker est en panne, ses tâches seront récupérées par un ou des autres workers actifs. • Langages de programmation supportés – Python • Cas d’utilisation – Lancer une tâche en arrière-plan. Par exemple, pour terminer la requête Web dès que possible, mettre à jour la page des utilisateurs de manière incrémentielle – Traitement une grande quantité de données de type Batch – Traitement en temps réel • Inconvénients – Seul Python est supporté comme langage de programmation – Non autonome de déploiement - 00/00/00 - Pied de page (titre ou service…) Page 3
- 4. Apache Storm • Calculs en temps réel distribué et tolérant aux pannes de flux de données – Latence faible: il peut traiter 100 messages par second par noeud – Fiable: il garantit que chaque unité de données sera exécutée au moins une fois ou exactement une fois. • Conception: – Nimbus - ordonnanceur de tâches sur le cluster: analyser et distribuer les tâches aux superviseurs – Superviseurs: lancer et surveiller les workers – Workers: sont des machines de travail qui eux-mêmes exécutent des tâches sur les messages reçus, à l’infini. Une tâche est un enchaînement d’unités de travail (une topologie Storm) sous forme d’un graphe orienté acyclique (DAG) qui se compose des spouts et des bolts: • Spout: c’est le point d’entrée du flux d’information, l’endroit par lequel les données arrivent. Les spouts ont donc pour rôle de se connecter à une source de données • Bolt: c’est un nœud de traitement des données fournies par le Spout. C’est ici qu’on fait des manipulations sur les données telles que des filtres, des jointures, des agrégations. • La communication entre spouts et bolts se fait sous forme de tuple – une structure de données dans Storm. • Stream: est une séquence de tuples qui circule dans une topologie • Tolérance – Pas un point unique de défaillance SPOF – Si un worker est mort, son superviseur va le redémarrer. Si le superviseur est mort, il s’est redémarrera en récupérant ses statuts sauvegardés dans Zookepper. • Modèle de déploiement: – Cluster Zookeeper • Cas d’utilisation – Traitement de flux de données ou d’information en continue – L’appel de procédures à distance distribuées (PRC) – Les fonctions d’extraction/transformation/chargement (ETL) • Inconvénients – Impossible d’exécuter des tâches planifiées - 00/00/00 - Pied de page (titre ou service…) Page 4
- 5. Apache Pig • Modèle de développement plus haute niveau pour écrire de traitements MapReduce – Auto-générer des tâches Hadoop Map-Reduce à partir des requêtes similaire SQL sur des données non structurées – MapReduce est un modèle de calcul massivement parallèle sur de données massives – Programme en le langage procédural Pig Latin – Créé chez Yahoo • Pig Latin – Un langage de haute niveau orienté traitement par flux de données, axé sur le traitement parallèle – Simple, efficace, proche du scripting – Fournit les opérations standards pour la manipulation de données (filters, joins, ordering), des types primitifs, des types complexe (tuples, bags, maps) – Déclare le plan d’exécution – Il ouvre Hadoop au non-programmeur-java • Pig Engine – Un moteur d’exécution au sommet de Hadoop – Parse, optimise et exécute automatiquement les scripts PigLatin comme une série de jobs MapReduce au sein d’un cluster Hadoop • Modèle de déployment – Cluster Hadoop • Cas d’utilisation – C'est particulièrement bon si l’on a accès à un cluster Hadoop qui existe déjà – Les fonctions d’extraction/transformation/chargement (ETL) – Développement d’un programme d’analyser un volume important de données • Inconvénients – Pas mature, il est encore dans la phase de développement – Besoin d’apprendre la syntaxe Pig Latin - 00/00/00 - Pied de page (titre ou service…) Page 5
- 6. Apache Hive • Une plateforme haute niveau pour la création de programme MapReduce – Auto-générer des tâches Hadoop MapReduce à partir des requêtes HQL sur les données structurées – Une infrastructure pour Entrepôt de données (Data Warehouse) – Créé chez Facebook • Langage HiveQL – Syntaxe similaire à celle du SQL avec un schéma relationnel – Support DDL (Data Definition Language - Create, Alter, Drop): par exemple création de tables avec la commande CREATE TABLE .. – DML (Data Manipulation Language - Load, Insert, Select) : par exemple chargement de données depuis HDFS avec la commande LOAD DATA… – Fonction utilisateurs – Appel à des programmes externe MapReduce • Conception – Stock ses données dans HDFS – Charger et convertir HDSF en un entrepôt de données et agit comme un dialecte SQL – Compile des requêtes HiveQL en plan qui constitue une suite de DAG de jobs MapReduce et les exécute sur le cluster Hadoop • Modèle de déployment – Cluster Hadoop • Cas d’utilisation – C'est particulièrement bon si l’on a accès à un cluster Hadoop qui existe déjà. – Créer des rapports – Analyser un volume important de données structurées par des data scientistes en langage HQL • Inconvénients – La mise à jour des données est compliquée – Pas d’accès en temps réel aux données – Latence significative - 00/00/00 - Pied de page (titre ou service…) Page 6
Notes de l'éditeur
- Les RDD sont immutables. C’est-à-dire pour obtenir une modification d'une RDD, il faut y appliquer une ou des transformations, qui retourneront une nouvelle RDD et la RDD originale restera inchangée. Deux questions sont posées ici: 1. Est-ce qu'il y a une option "Inplace" pour modifier une RDD et récupérer cette RDD elle-même changée au lieu d'une nouvelle RDD? 2. Est-ce que Spark crée les nouvelles RDDs autant de fois que le nombre des transformations? La réponse pour la première question est NON. Pour la deux question, on peut prendre une exemple "Word Count" ci-dessous. Il y a trois transformation "flatMap", "map" et "reduceByKey" et une action "saveAsTextFile". 1. text_file = sc.textFile("hdfs://...")2. words = text_file.flatMap(lambda line: line.split(" ")) 3. pairs = words.map(lambda word: (word, 1)) \4. counts = pairs.reduceByKey(lambda a, b: a + b)5. counts.saveAsTextFile("hdfs://...") Jusqu'à ligne 4, il n'y a aucun calcul effectué mais une chaîne DAG de trois transformations est créée (Directed Acyclic Graph). Cette chaîne est une séquence de calculs à effectuer sur les données. Une fois que l'action "saveAsTextFile" à ligne 5 est applée, toute la chaîne DAG sera calculée ensemble. C'est une mécanisme "lazy" de Spark pour optimiser le mémoire et les calculs. Cette mécanisme permet de créer une seule nouvelle RDD pour toutes les transformations. Le mémoire n'est pas donc multiplié 3 fois mais une fois pour les trois transformations. Le résultat, c-a-d la nouvelle RDD, peut être stocké dans le mémoire cache. Dans l'avenir, si la même chaîne est exécutée encore une fois, le système cherchera tout d'abord dans le mémoire cache: s'il trouve le résultat, il le prendra, sinon, la chaîne sera recaculée à partir de la RDD originale. La cache des résultats est préconisée car une fois une RDD est cachée, elle est stockée dans le mémoire local de chaque worker. Il évite donc de récaculer et de réenvoyer les résultats par réseaux au worker. La mécanisme "immutable" assure donc une tolérance aux pannes du système. Il peut récréer et récalculer son ensemble de données à partir des RDDs originales s'il trouve encore la chaîne DAG.