Télécharger en tant que PDF, PPTX











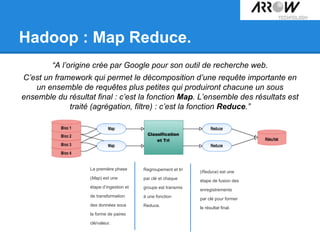
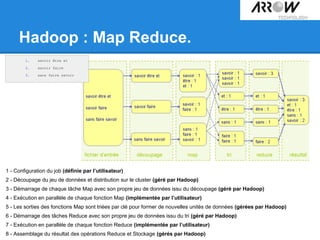
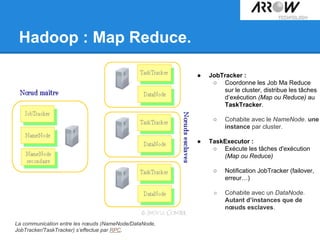
![Hadoop : Map Reduce.
public class WordCountReducer extends MapReduceBase implements
Reducer {
public void reduce(Text key, Iterator values,
OutputCollector output, Reporter reporter )
throwsIOException {
int nbOcc = 0;
while (values.hasNext ()) {
nbOcc += values.next ().get();
}
output.collect (key, new IntWritable (nbOcc));}}
class WordCountMapper extends MapReduceBase implementsMapper{
private final static IntWritable mDefOcc = newIntWritable (1);
private Text mWord = new Text();
public void map(LongWritable key, Text value, OutputCollector
output, Reporter reporter ) throwsIOException {
String lLine = value.toString ();
StringTokenizer lIt = new StringTokenizer(lLine);
while (lIt.hasMoreTokens()) {
mWord.set(lIt.nextToken());
output.collect(mWord, mDefOcc);}}}
public class WordCount {
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf (WordCount. class);
conf.setJobName ("Compteur de mots" );
conf.setMapperClass (WordCountMapper. class);
onf.setReducerClass (WordCountReducer. class);
conf.setInputFormat (TextInputFormat. class);
conf.setOutputFormat (TextOutputFormat. class);
FileInputFormat.setInputPaths (conf, newPath(args[0]));
FileOutputFormat.setOutputPath (conf, newPath(args[1]));
JobClient.runJob (conf);
}](https://image.slidesharecdn.com/techdayhadoop-140523034412-phpapp01/85/Tech-day-hadoop-Spark-18-320.jpg)

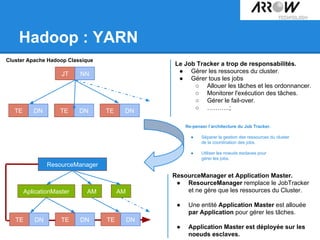
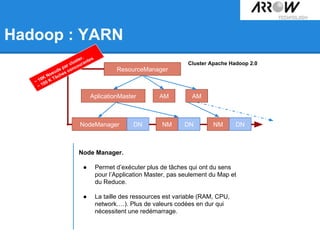
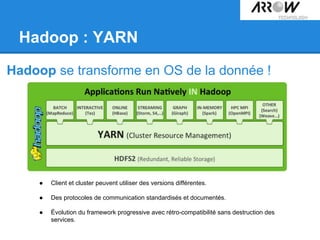
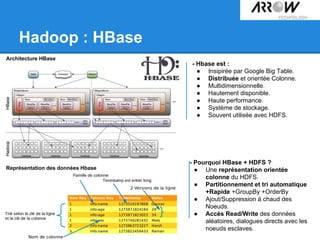
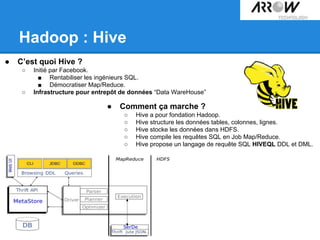

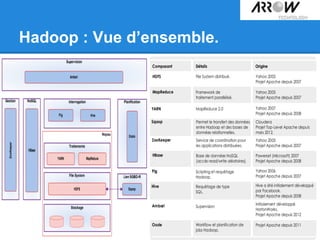
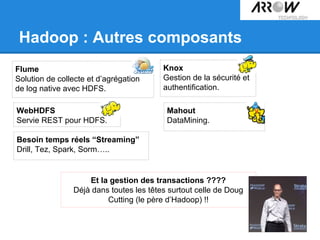

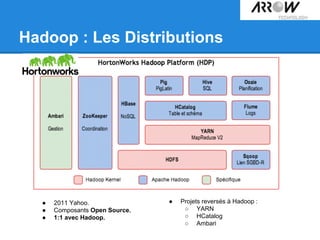

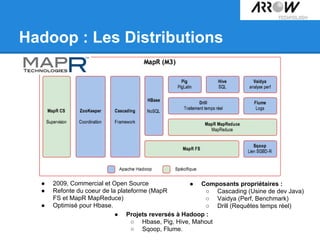









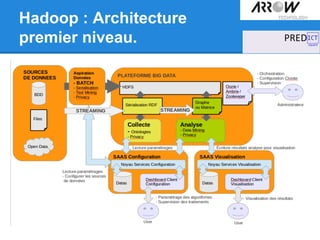
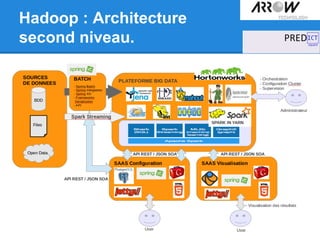


Le document traite de Hadoop, un framework open source essentiel pour la gestion des données massives, connu sous le terme 'big data'. Il explore les différents composants de Hadoop, tels que HDFS pour le stockage de données distribuées et MapReduce pour le traitement des données, ainsi que des outils connexes comme HBase et Hive. Le texte souligne également des applications concrètes, notamment le projet 'Square Predict', visant à tirer parti des données pour des analyses précises dans le secteur de l'assurance.



































































