Télécharger en tant que PDF, PPTX





![Technologie de stockage et traitement de données en mode distribué, parallèle
et extensible
Basé sur le framework de programmation distribuée MapReduce
Fonction Map (phase amont): décomposition des tâches et traitement de données en tant que paires (k, v)
Fonction Reduce (phase aval): consolidation des résultats et traitement de données en tant que paires (k, [vv])
Open source, écrit en langage Java et soutenu par la fondation Apache
http://hadoop.apache.org/
Prévu initialement pour le traitement de données non structurées
Peut être installé sur du matériel informatique standard
S’impose comme la solution open source de référence pour le « Big Data » déjà
adoptée par Facebook, eBay, Linkedin, Twitter, Yahoo, etc.](https://image.slidesharecdn.com/gur11-10-2012rhadoop-121013045844-phpapp02/85/HADOOP-R-6-320.jpg)
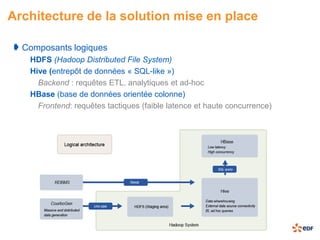

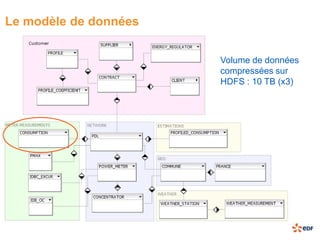

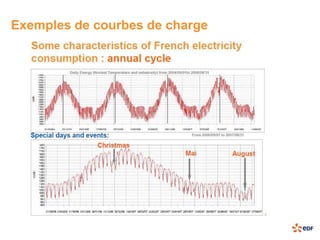











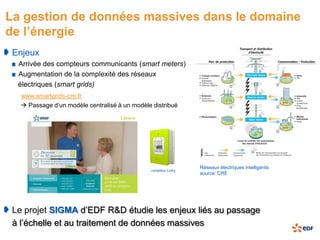
Le document présente une étude sur le traitement de données massives avec Hadoop dans le cadre du projet Sigma d'EDF R&D, soulignant l'importance croissante des données dans le secteur de l'énergie. Il traite des enjeux liés à la gestion de volumes massifs de données, en utilisant des exemples pratiques de traitement avec les outils Rhadoop et Mahout, notamment à travers la méthode k-means. En conclusion, bien que Hadoop offre une solution prometteuse avec des avantages tels que la tolérance aux pannes et la capacité de gestion des données non structurées, il souffre encore de limitations en termes de maturité industrielle et de disponibilité des compétences.



































































