Téléchargé 363 fois






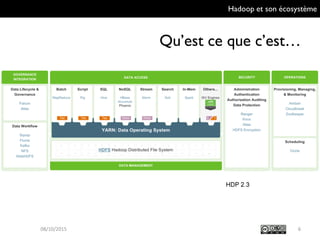

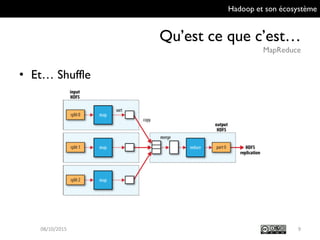
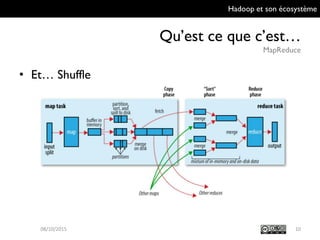



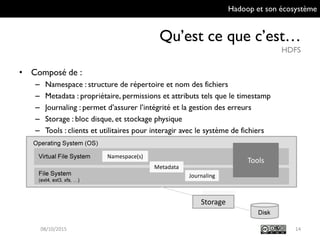
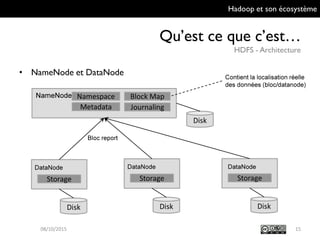
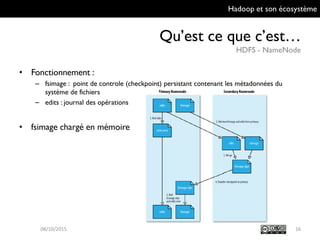
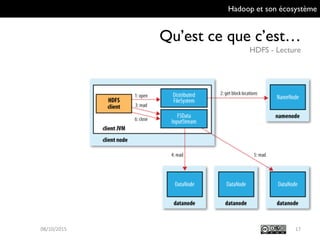
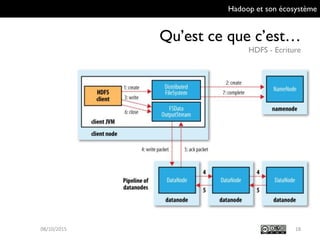
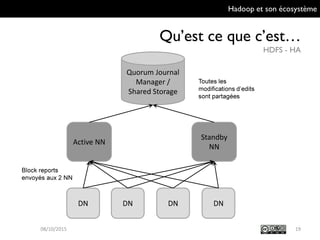

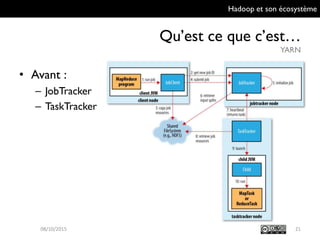
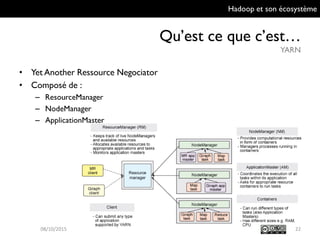
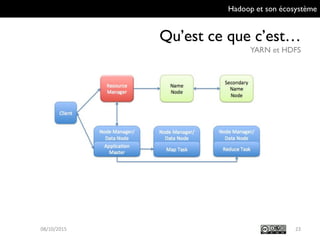





















































Le document présente Hadoop et son écosystème, traitant notamment de MapReduce, HDFS, YARN et divers outils d'intégration de données. Il décrit également des composants de traitement de données tels que le traitement par lots, SQL analytique, et le machine learning, tout en mentionnant des systèmes de gestion de bases de données non relationnelles. Enfin, il aborde des outils supplémentaires pour la gestion et la supervision de clusters Hadoop.










































































