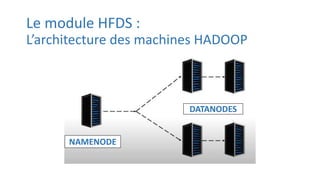
Hadoop est un logiciel de traitement distribué permettant le stockage et le traitement de grandes quantités de données via des grappes d'ordinateurs. Il comprend plusieurs modules comme HDFS pour la gestion des fichiers, YARN pour la gestion des ressources, et MapReduce pour le traitement de données à grande échelle. Hadoop est utilisé par des entreprises telles que Netflix et Amazon pour diverses applications, notamment l'analyse de données et la prédiction de fraudes.