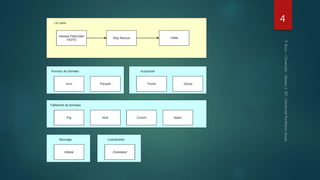
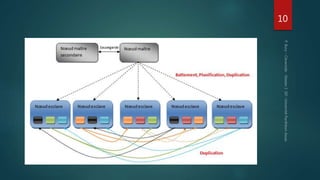
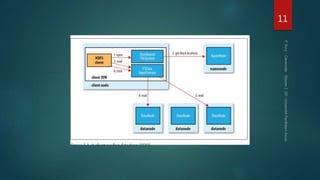
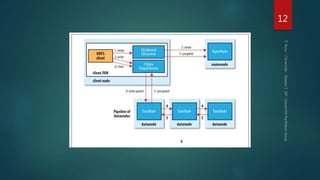
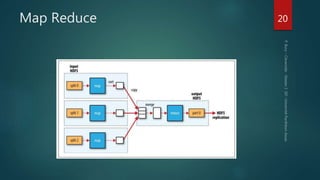
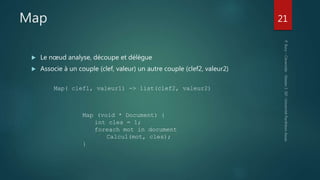
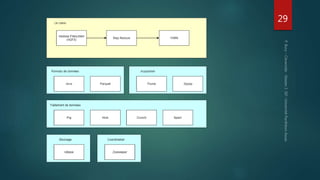
Hadoop est conçu pour traiter de gros volumes de données de manière distribuée, reposant sur des composants majeurs tels que HDFS pour le stockage et YARN pour la gestion des ressources. Le traitement des données s'effectue grâce à MapReduce, un cadre de programmation qui divise les tâches et distribue les traitements. Des outils comme Pig et Hive permettent d'interagir avec Hadoop en utilisant des langages plus familiers, tout en répondant à la nécessité de gérer de grandes quantités de données efficacement.