


































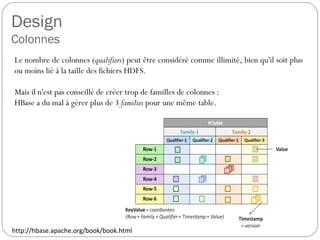
![Design
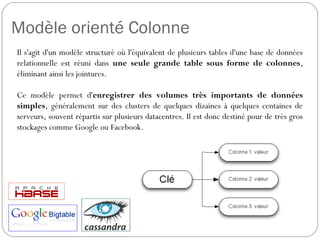
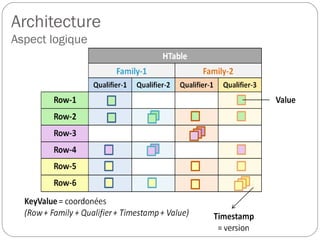
Colonnes
Les données sont enregistrées par leur keyValue, donc avec toutes leurs
coordonnées. De ce fait pour toutes les valeurs d'une même ligne, le
nom des families, qui représente le nom du fichier HDFS au format
string, et celui des qualifiers, stocké en bytes[ ] dans le fichier, seront
systématiquement répétés. Pour optimiser la place mémoire, il est donc
recommandé d'employer des noms de familles de colonnes les plus
petits possible (donc en un seul caractère) et de rentabiliser ceux des
colonnes en les utilisant comme un complément d'information.
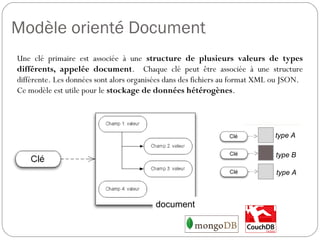
Exemple :
ligne (ou row) = date arrondie à l'heure
familles de colonnes = t (température d'un composant),
e (état activé ou non du composant)
colonne (ou qualifier) = temps en minutes
N. Dimiduk, A. Khurana- 2012
"HBase in action" - Manning](https://image.slidesharecdn.com/hadoop-hbase-150218090939-conversion-gate02/85/Hadoop-Hbase-Introduction-53-320.jpg)





![HBase Shell
Commandes principales
créer une table T avec ses familles de colonnes F1 et F2
create 'T', 'F1', 'F2'
déverrouiller une table disable 'T' ,
déverrouiller toutes les tables disable_all '*.*'
ajouter une famille de colonnes à une table alter 'T', NAME =>'F3'
reverrouiller une table enable 'T'
ajouter ou remplacer une valeur à certaines coordonnées
put 'T', 'R1', 'F1:C1', 'V1'
savoir si une table existe exist 'T'
compter le nombre de valeurs dans des colonnes
count 'T', {COLUMNS => [F1:C2, F1:C3]}](https://image.slidesharecdn.com/hadoop-hbase-150218090939-conversion-gate02/85/Hadoop-Hbase-Introduction-60-320.jpg)
![HBase Shell
Commandes principales
lister toutes les tables list
décrire une table describe 'T'
lire toutes les lignes d'une table scan 'T'
lire des familles de colonnes scan 'T', {COLUMNS => ['F1', 'F2']}
lire des colonnes scan 'T', { COLUMNS => [F1:C3', F2:C1']}
lire des colonnes au départ d'une ligne précise
scan 'T', { COLUMNS => [F1:C3', F2:C1'], STARTROW => 'R2'}
lire des colonnes jusqu'à une ligne précise
scan 'T', { COLUMNS => [F1:C3', F2:C1'], STOPROW => 'R6'}](https://image.slidesharecdn.com/hadoop-hbase-150218090939-conversion-gate02/85/Hadoop-Hbase-Introduction-61-320.jpg)


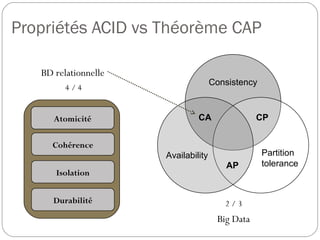
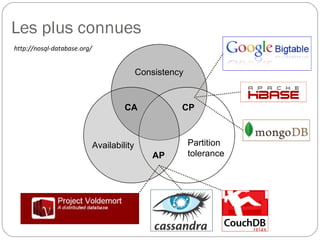
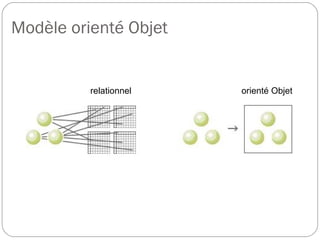
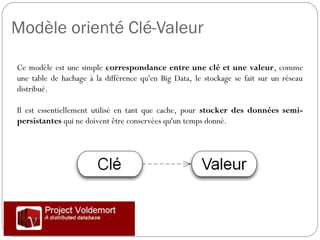
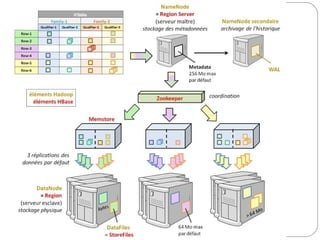
Cette présentation introduit les concepts fondamentaux de Hadoop et HBase, des technologies essentielles dans le domaine des big data. L'auteure, Blandine Larbret, partage sa compréhension personnelle des systèmes de gestion de données distribuées et de la dénormalisation, soulignant l'évolution des besoins en stockage et la croissance exponentielle des données. Elle mentionne les modèles de données utilisés dans les big data, ainsi que le principe d'architecture et de fonctionnement de Hadoop et HBase.



































































