Télécharger en tant que PDF, PPTX





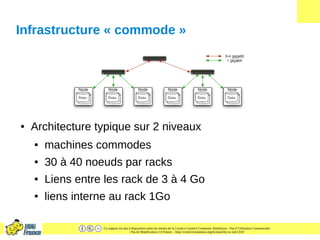


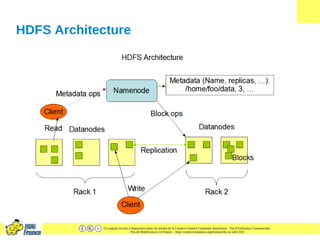













Le document présente HDFS (Hadoop Distributed File System), un système de fichiers distribué conçu pour gérer de larges ensembles de données avec tolérance aux pannes. Il décrit son architecture, les fonctions des composants comme le namenode et les datanodes, ainsi que des exemples d'applications et de commandes HDFS. Les caractéristiques clés incluent la réplication des données, la gestion des métadonnées et une structure optimisée pour le traitement par lots.























































































