Téléchargé 4 515 fois


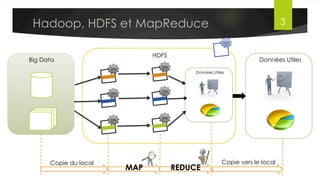
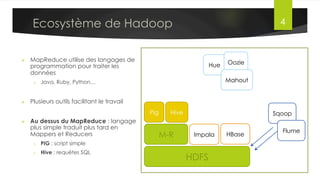
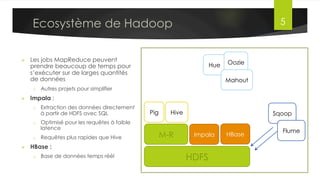
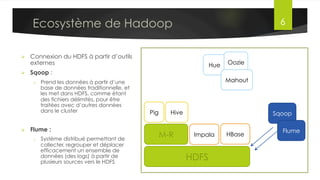
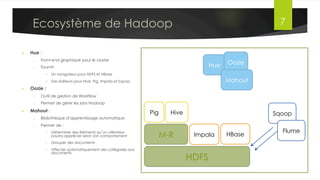
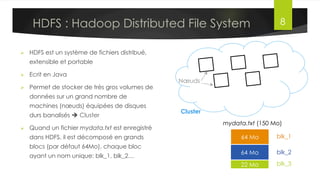
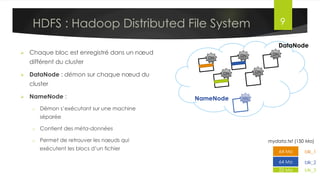
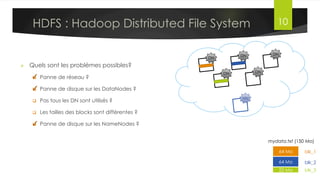
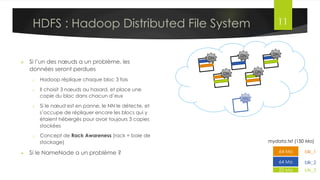

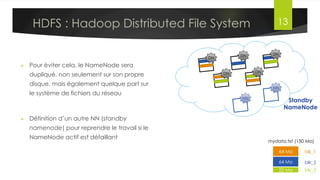
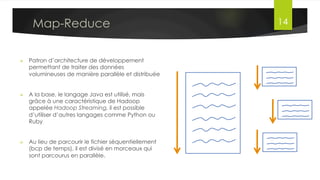






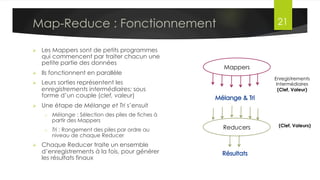
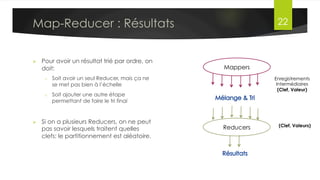
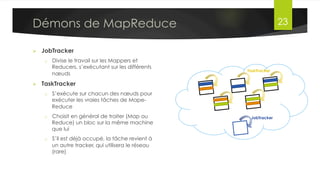














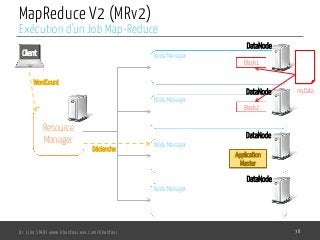
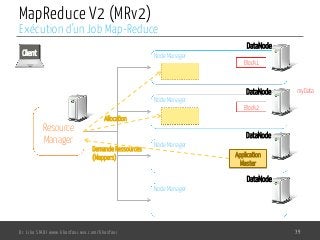
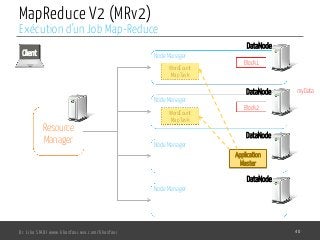
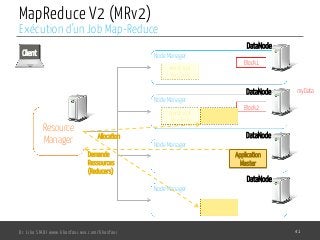
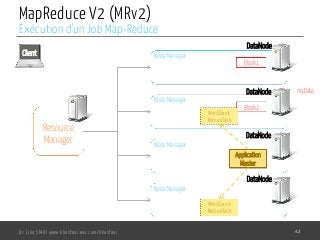
















Le document présente l'architecture et le fonctionnement du framework Hadoop, qui comprend le système de fichiers distribué HDFS et le modèle de traitement MapReduce. HDFS permet de stocker de grandes quantités de données sur un cluster, tandis que MapReduce facilite le traitement parallèle de ces données. Plusieurs outils et composants, tels que YARN et des bibliothèques comme Pig et Hive, viennent compléter Hadoop pour simplifier l'extraction, le stockage et le traitement des données.























































































