Télécharger pour lire hors ligne






















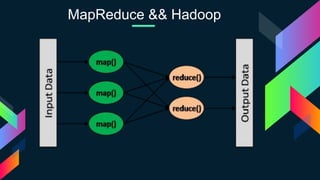














Le document présente une analyse détaillée des défis et solutions liés au Big Data, en mettant particulièrement l'accent sur Hadoop, une plateforme distribuée conçue pour stocker et traiter d'importantes quantités de données. Il décrit les concepts clés du Big Data, les technologies comme le cloud computing et MapReduce, ainsi que les divers cas d'utilisation de Hadoop dans des entreprises telles que Yahoo et Facebook. Enfin, il évoque l'importance croissante des métiers liés aux données dans le contexte de l'explosion des données numériques.































































![Final présention [recovered]](https://cdn.slidesharecdn.com/ss_thumbnails/yiss0uyqrcoxmmtmeayl-signature-53247b4a817d4ab0915f34047a536cc6bc0c9736ef61e157e239a5d80510ea9d-poli-160609193437-thumbnail.jpg?width=640&height=640&fit=bounds)