Téléchargé 78 fois



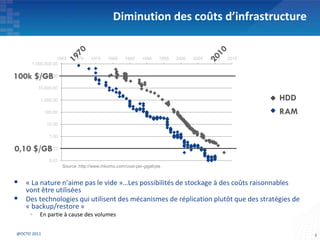
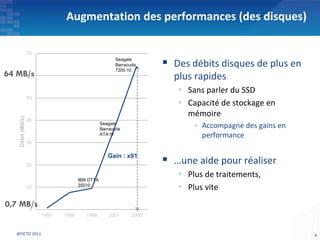



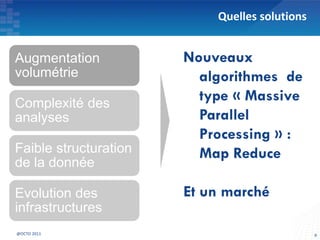

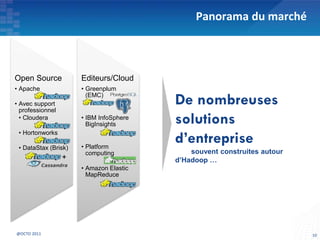
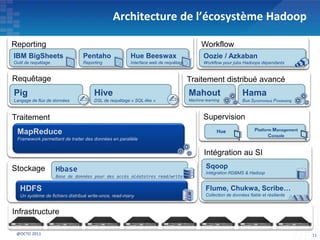
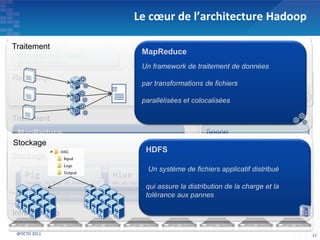
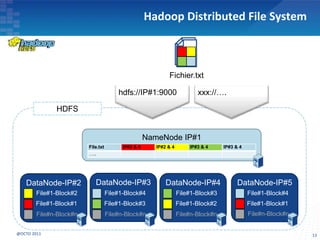
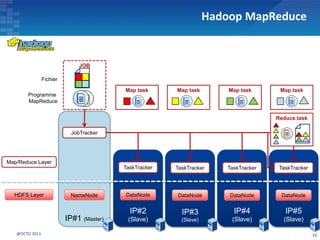

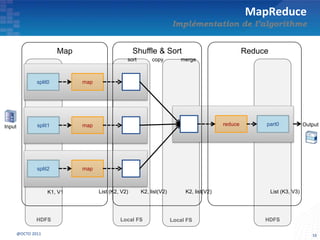
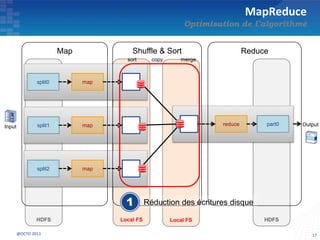
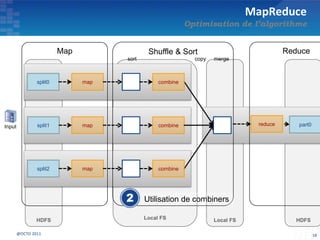
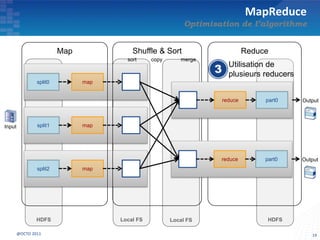

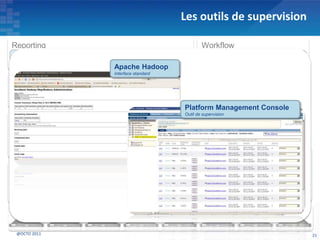
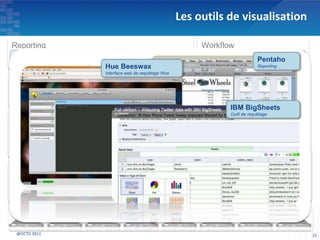
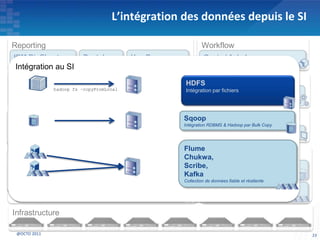
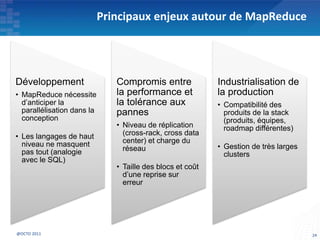

Le document présente les principes fondamentaux de MapReduce et Hadoop, soulignant l'évolution technologique permettant un traitement parallèle des données et une réduction des coûts d'infrastructure. Il aborde également les caractéristiques du 'big data', y compris la complexité des analyses et la variété des données, et il décrit l'écosystème Hadoop ainsi que les outils associés pour le traitement et la supervision des données. Enfin, il met en lumière les défis liés au développement et à l'industrialisation des solutions basées sur MapReduce.












































![Fac Sic Laboral Programa 2009[1]](https://cdn.slidesharecdn.com/ss_thumbnails/facsiclaboralprograma20091-090413180719-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































