






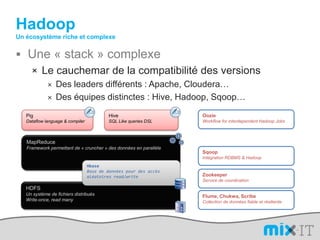
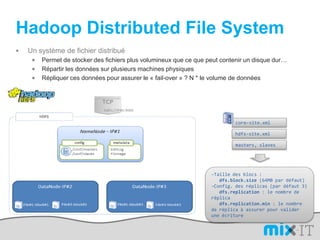
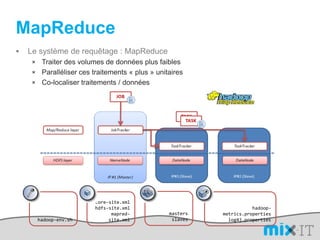
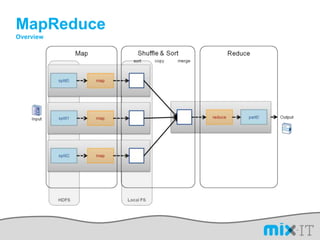

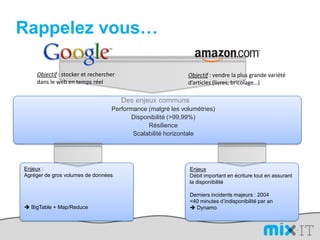
![L’avantage d’un DSLimport org.apache.hadoop.mapred; public static class MapextendsMapReduceBaseimplements Mapper { public voidmap(LongWritablekey, Text value, OutputCollector output, Reporter reporter) throwsIOException { String line = value.toString(); String[] lineAsArray = line.split("\t"); String currentCurrency = lineAsArray[4]; String amountAsString = lineAsArray[5]; String sens = lineAsArray[6];DoubleWritable data = null; if("Debit".equals(sens)){ data = new DoubleWritable(Double.parseDouble("-" + amountAsString)); }else if("Credit".equals(sens)) { data = new DoubleWritable(Double.parseDouble(amountAsString)); }output.collect(new Text(currentCurrency), data); } }SELECT Currency, SUM(Amount) FROMcash_flowWHERE Direction='Credit' AND DueDate < = unix_timestamp('2010-09-15 00:00:00') GROUP BY Currencypublic class CurrencyAggregateextendsConfiguredimplementsTool {@Overridepublic intrun(String[] args) throws Exception{JobConfconf = new JobConf(CurrencyAggregate.class);conf.setJobName("CurrencyAggregate"); //output of the Mapper );conf.setOutpconf.setOutputKeyClass(Text.classutValueClass(DoubleWritable.class);conf.setMapperClass(Map.class);conf.setReducerClass(Reduce.class);conf.setInputFormat(TextInputFormat.class);conf.setOutputFormat(TextOutputFormat.class);FileInputFormat.setInputPaths(conf, new Path(args[0]));FileOutputFormat.setOutputPath(conf, new Path(args[1]));JobClient.runJob(conf); return 0; }public staticvoid main(String[] args) throws Exception {intexitCode = ToolRunner.run(new CurrencyAggregate(), args);System.exit(exitCode);}/The reduce is called once per key in the output map of the map() function public static class Reduce extends MapReduceBase implements Reducer { public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException { double sum = 0; while (values.hasNext()) { double amount = values.next().get(); sum += amount; }output.collect(key, new DoubleWritable(sum)); }}](https://image.slidesharecdn.com/mix-it-110408082940-phpapp01/85/mix-it-2011-16-320.jpg)

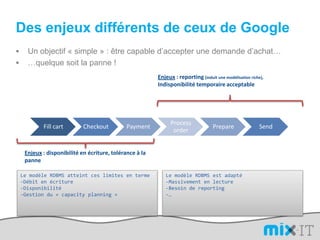

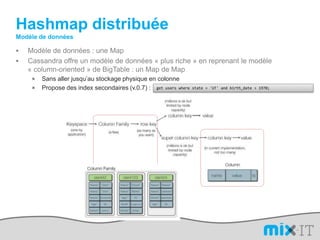
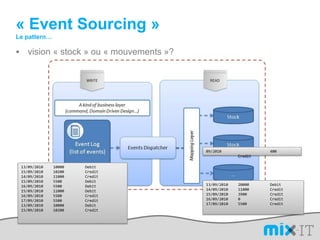
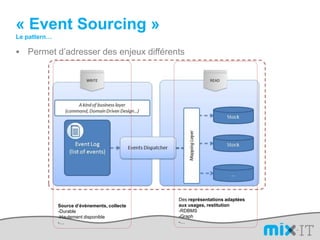
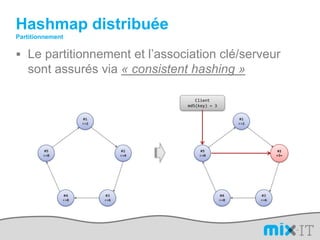
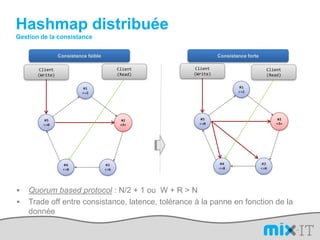







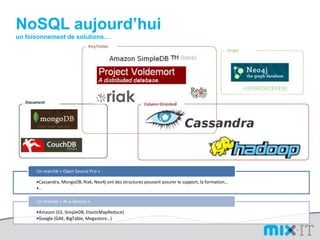
Le document présente une synthèse du paysage des bases de données NoSQL, abordant l'évolution depuis les fichiers séquentiels jusqu'aux systèmes complexes comme Hadoop et Dynamo. Il souligne l'importance de la performance, de la disponibilité et de la résilience dans le traitement de grandes quantités de données, tout en mettant en avant les différences entre les approches NoSQL et RDBMS. Enfin, il évoque l'émergence de nouveaux défis en matière de gestion des données, tels que la tolérance aux pannes et la modélisation flexible.






























































