Téléchargé 102 fois
![{ name : ‘MongoDB’, type : ‘NoSQL’ }
{
speakers : [‘Oussama MAHJOUB, ‘Oussama ZOGHLAMI ],
date : ‘16/12/2014’
}](https://image.slidesharecdn.com/mongodb-141219042752-conversion-gate01/75/Mongo-DB-1-2048.jpg)


![JSON Style :
{
_id : "10001",
loc : [-73.99670500000001,40.74838],
pop : 18913,
state : "NY",
city : {
name : "NEW YORK",
description : “Cool description goes here !”
}
}
MONGODB : DATA MODELING : DOCUMENT
{ number : 3 }
Unique Document ID
Key
Value
Sub Document](https://image.slidesharecdn.com/mongodb-141219042752-conversion-gate01/75/Mongo-DB-5-2048.jpg)

![MONGODB : DATA MODELING : INDEXES
{ number : 6 }
{
_id : "10001",
area : 5
pop : 18913,
state : "NY",
loc : [-73.99670500000001,40.74838],
city : {
name : "NEW YORK",
description : “Cool description goes here !”
}
}
● Single Field Index
● Compound Index
● Multikey Index
● Geospatial Index
● Text Index](https://image.slidesharecdn.com/mongodb-141219042752-conversion-gate01/75/Mongo-DB-8-2048.jpg)

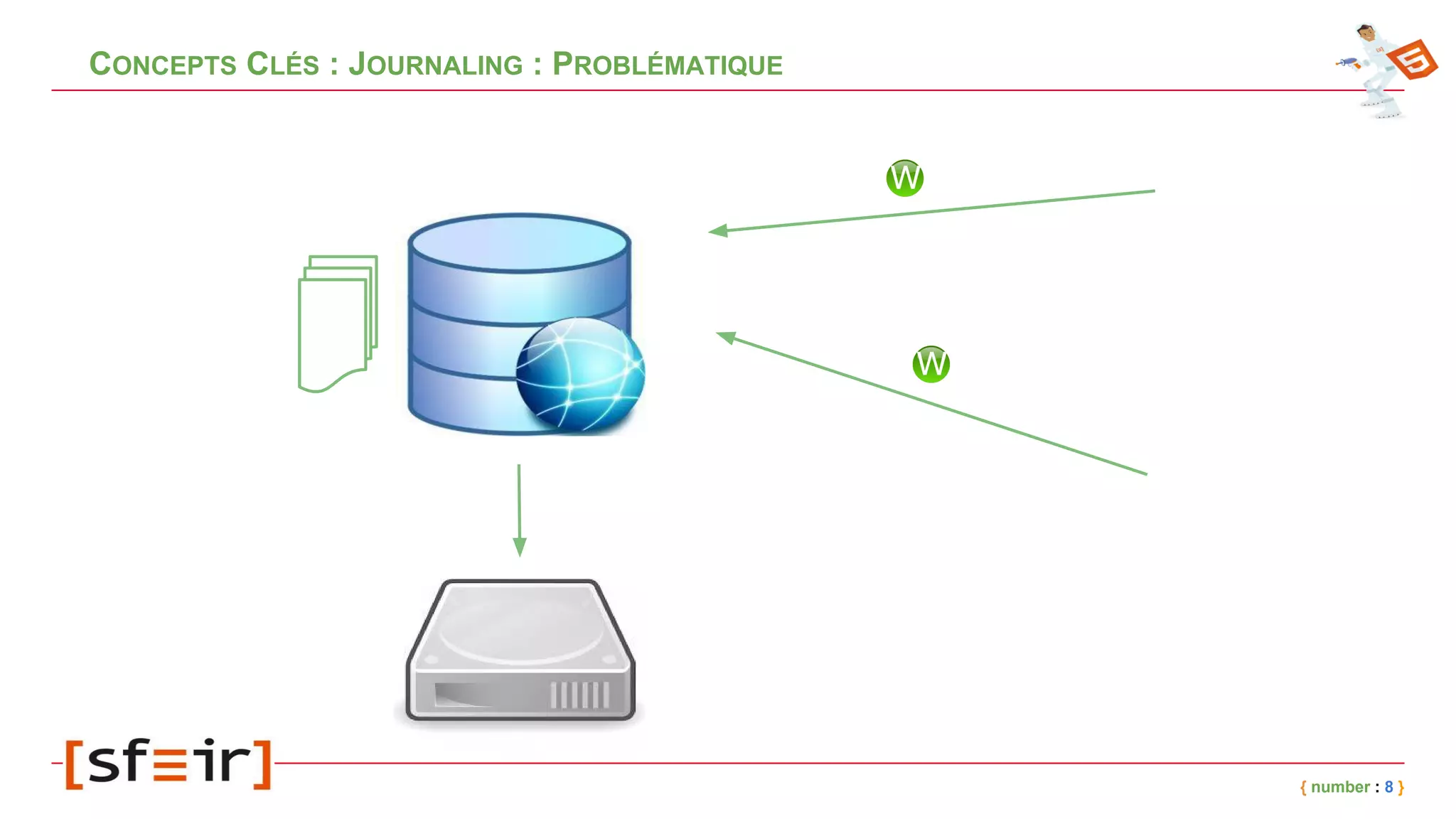
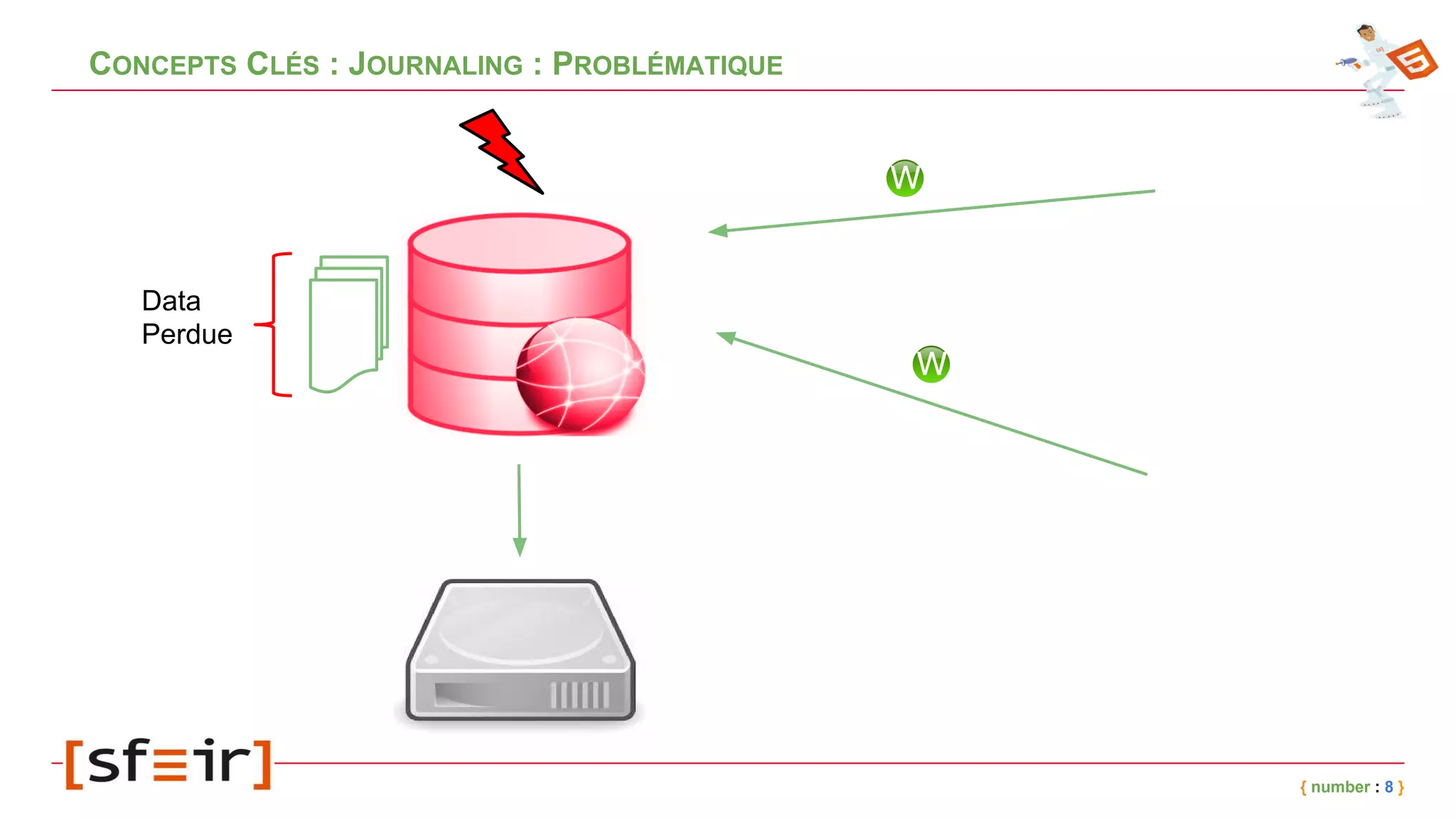

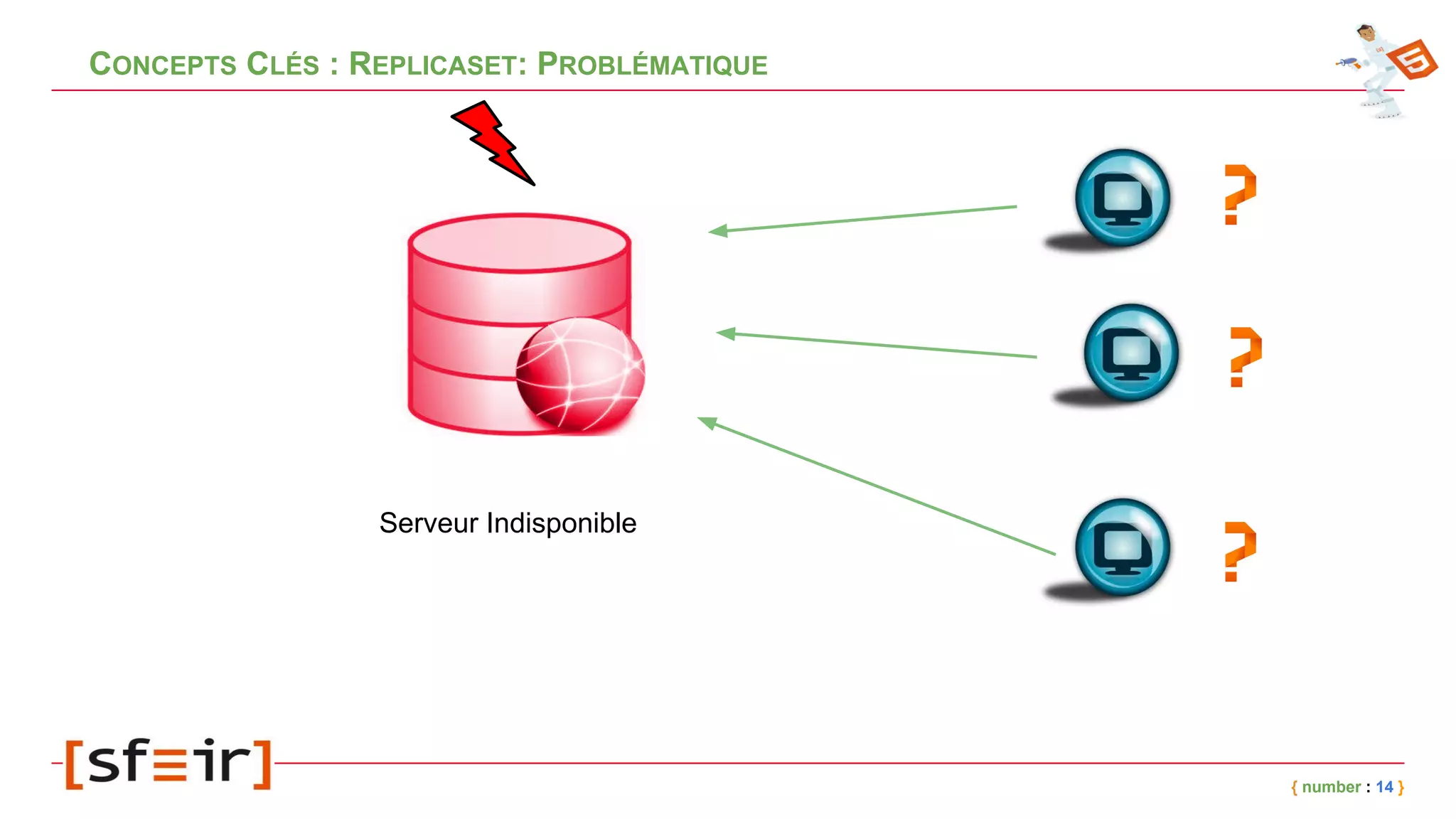
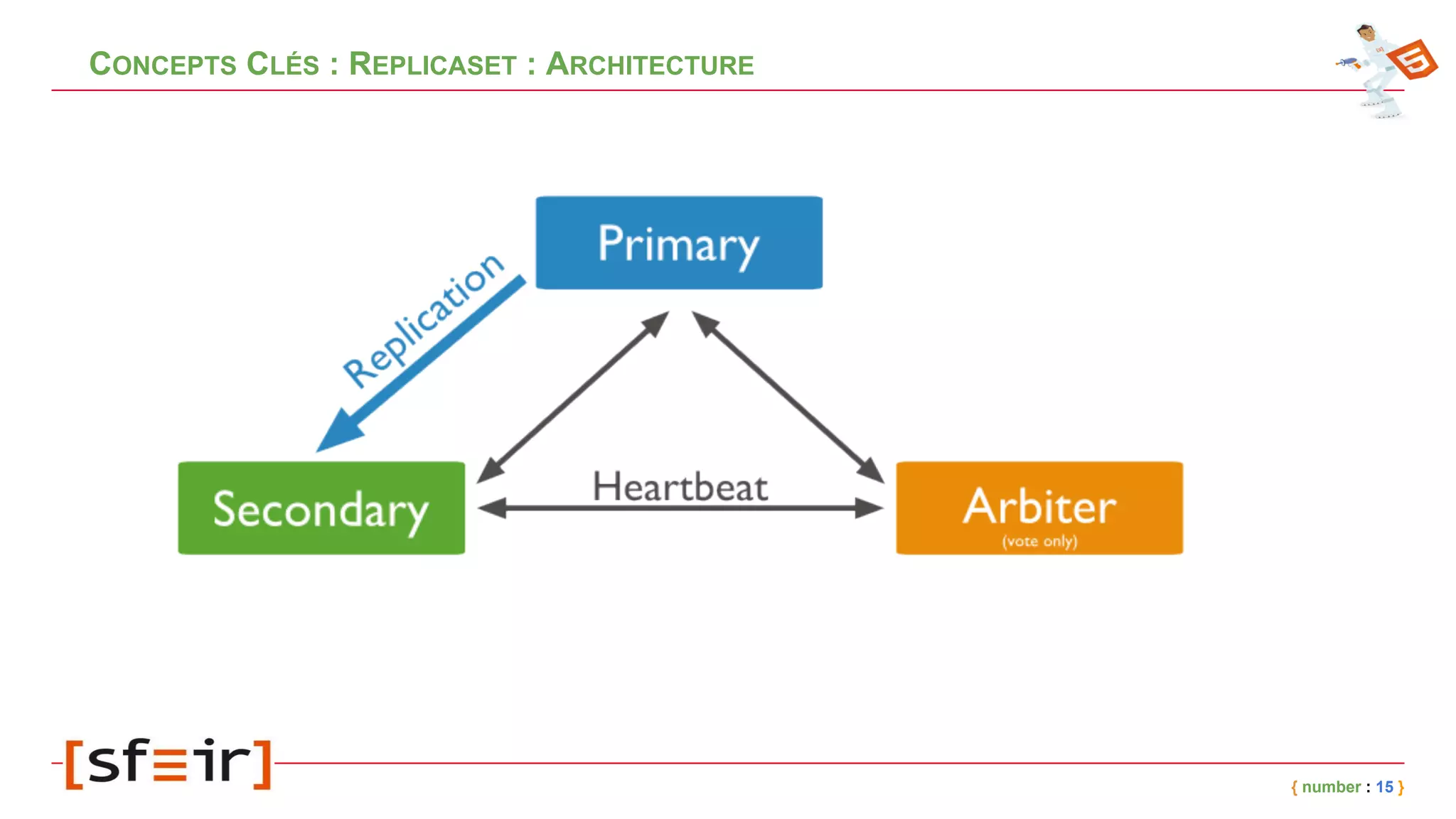



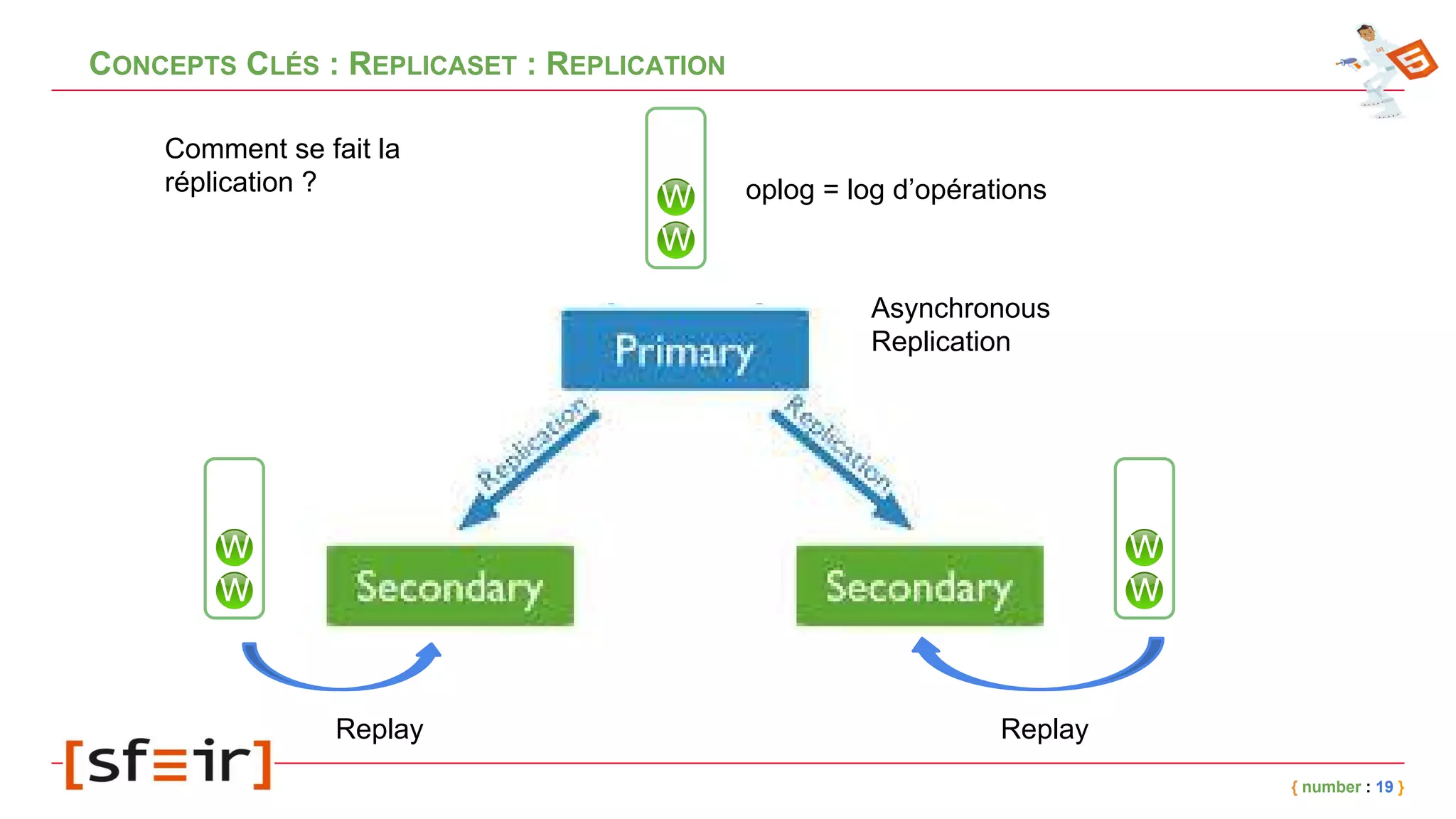





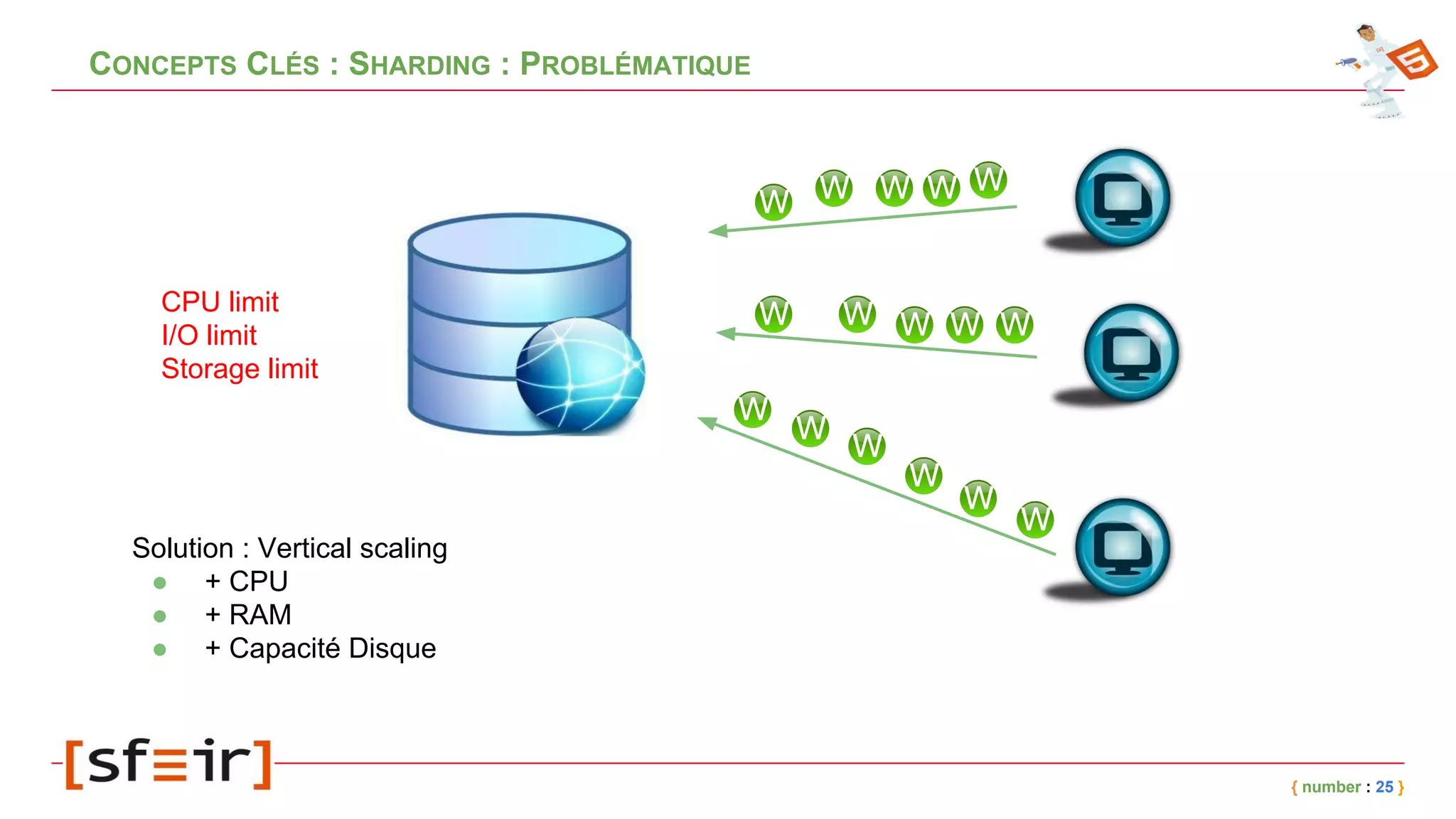


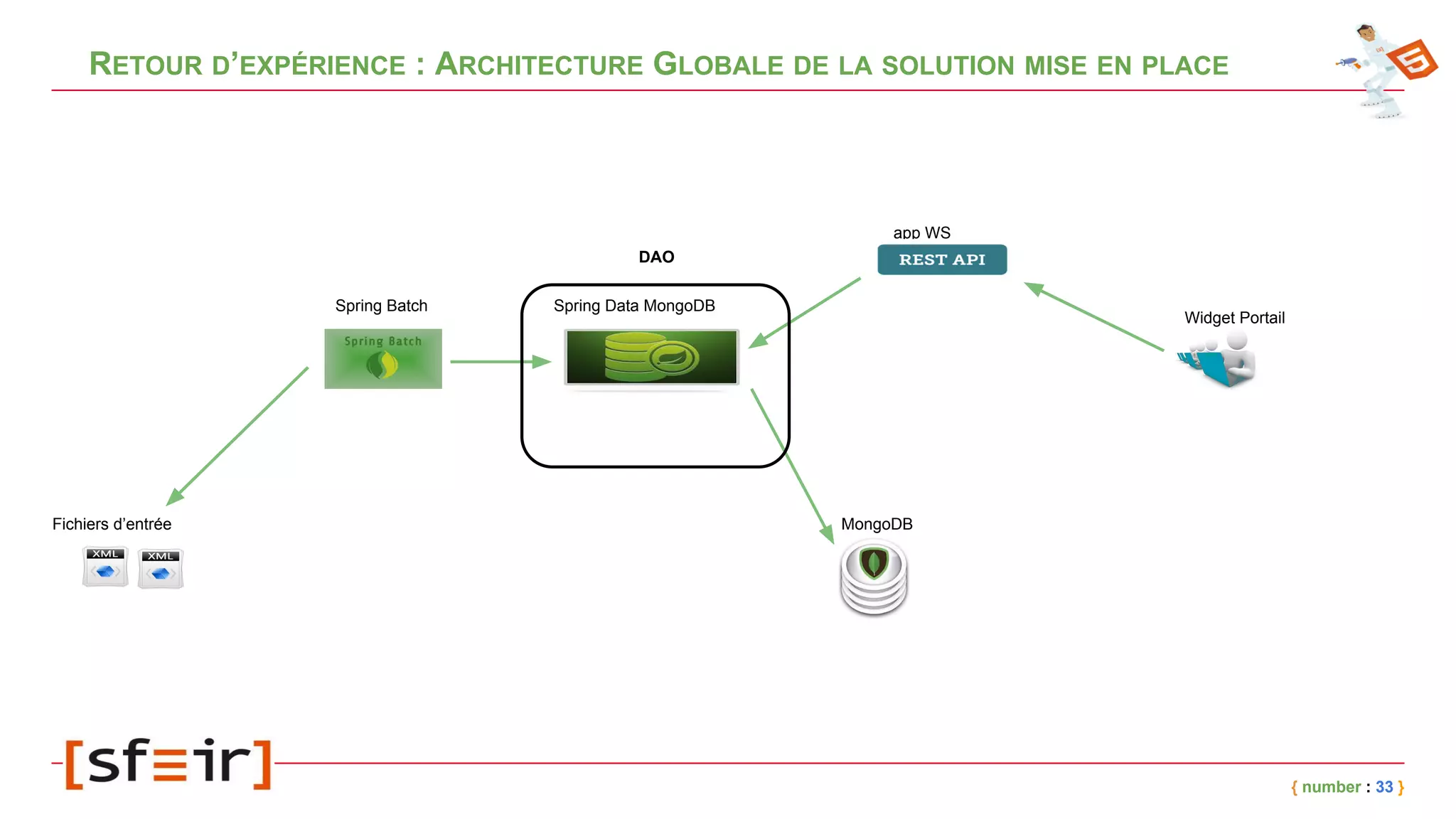



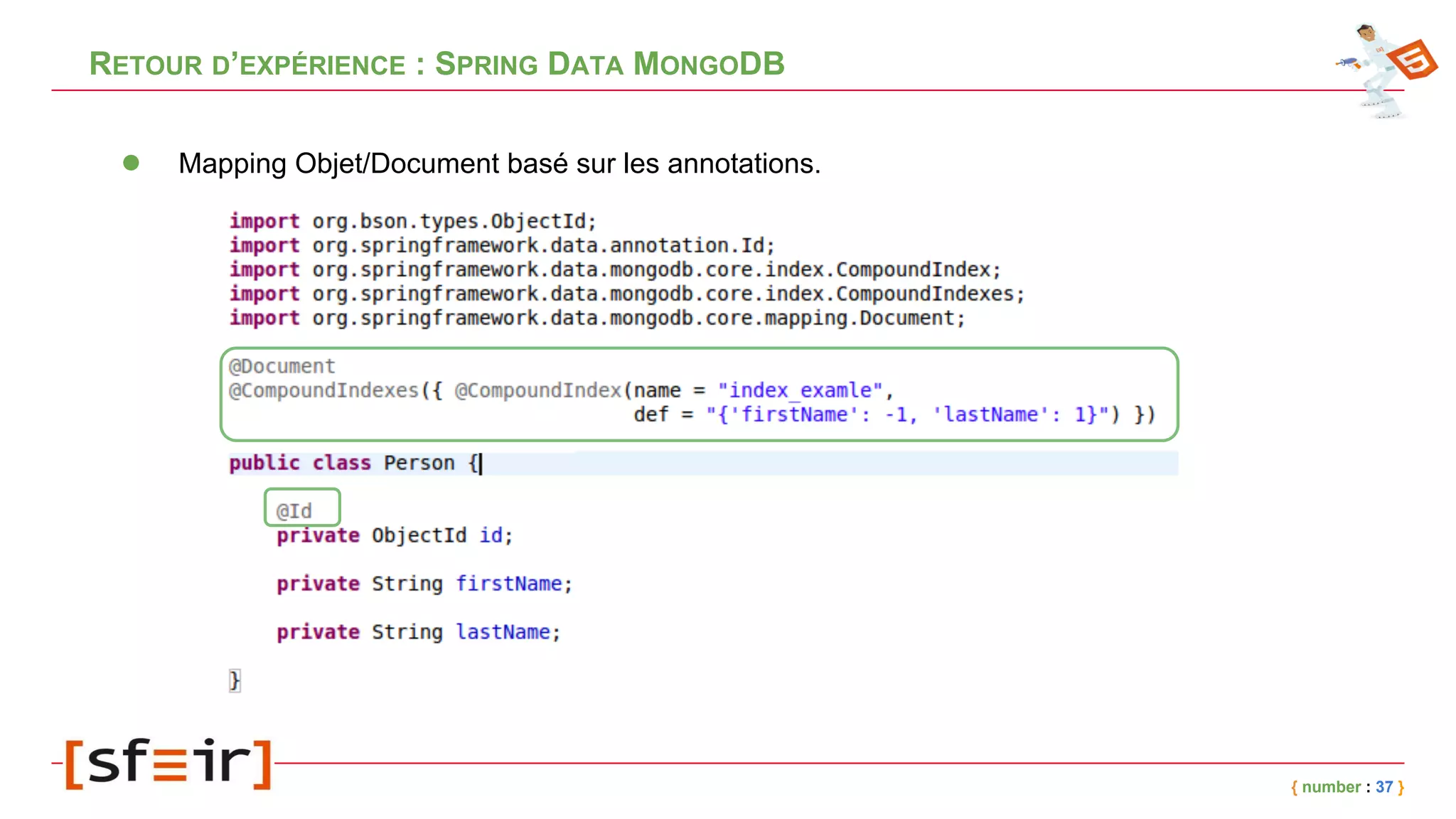




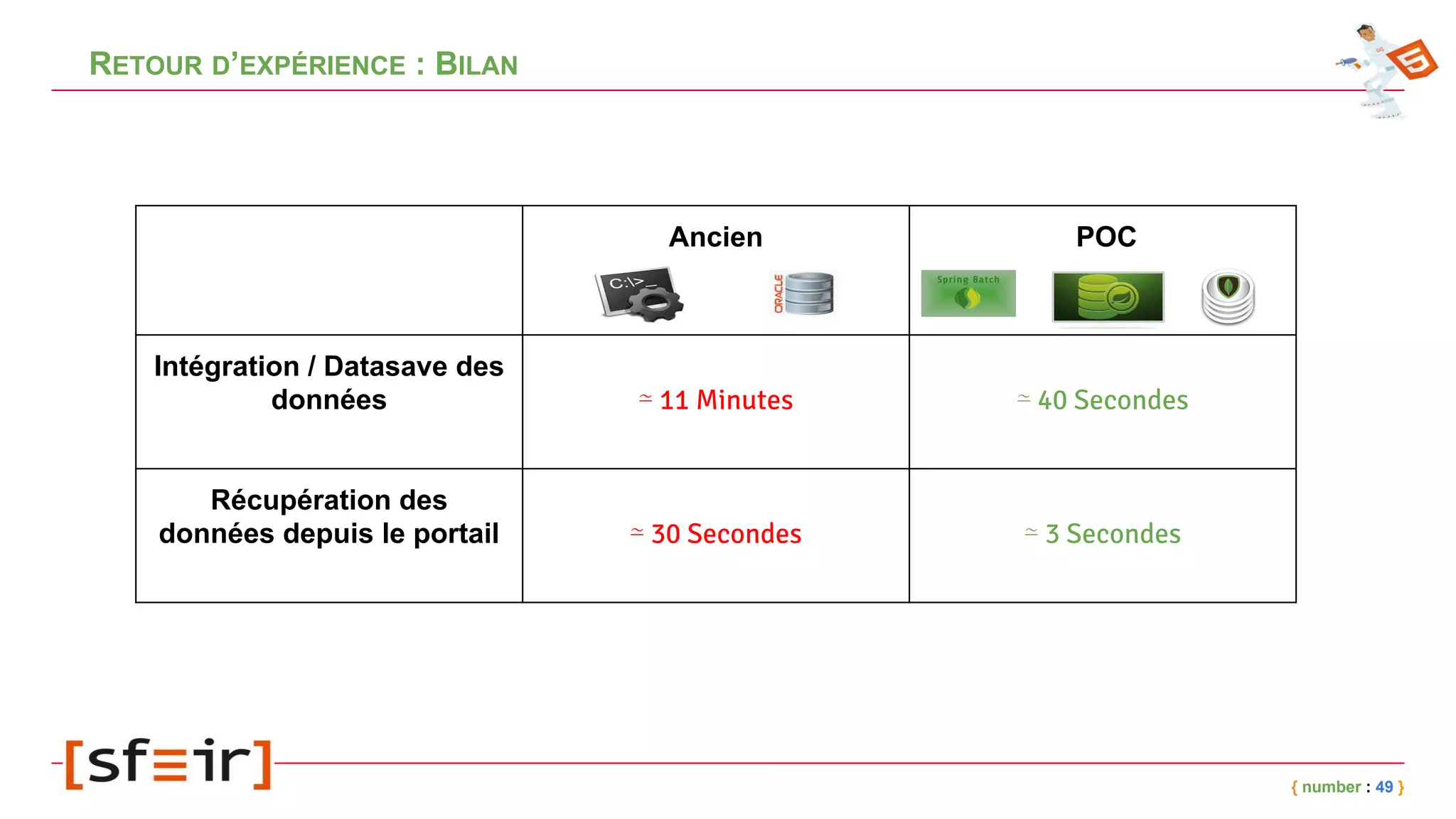



Le document présente MongoDB, une base de données NoSQL orientée documents, en détaillant son modèle de données, ses concepts clés comme le journaling, le replicaset et le sharding, ainsi que des exemples d'application. Il fournit également un retour d'expérience sur l'intégration de MongoDB avec Spring et les bénéfices en matière de performance et de disponibilité. Enfin, des conclusions soulignent l'efficacité de la solution mise en place et les améliorations notables en termes de temps de traitement.















































