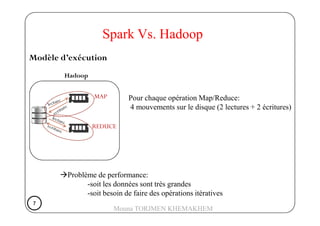
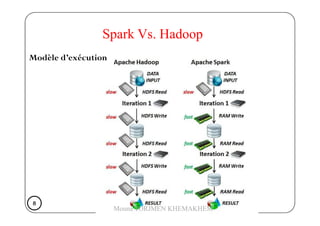
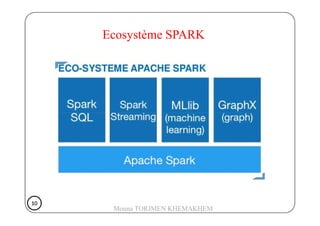
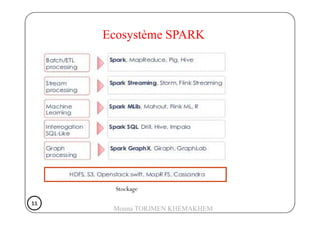
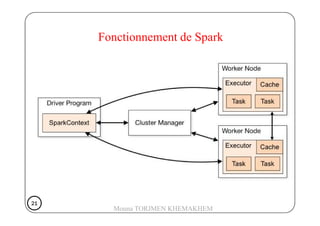
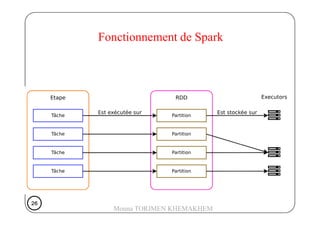
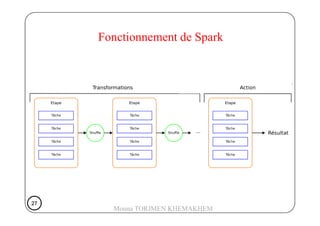
Le document présente Spark, un moteur de traitement de données distribué, développé à Berkeley en 2009, qui surpasse Hadoop en rapidité et en efficacité. Spark utilise des RDD (Resilient Distributed Datasets) pour manipuler des données de manière tolérante aux pannes et propose un modèle de programmation plus flexible que celui de Hadoop. Il détaille aussi le fonctionnement de Spark dans un cluster, impliquant des workers, des executors, et un cluster manager pour la gestion des ressources.











![Exemple de transformations [la librairie standard de
Spark] :
map(func): applique une fonction à chacune des données.
filter(func): permet d'éliminer certaines données.
distinct(): supprime les doublons.
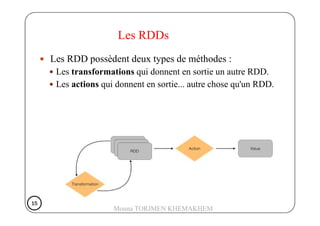
Les RDDs
distinct(): supprime les doublons.
groupByKey(): transforme des clés-valeurs (K, V) en (K, W)
où W est un object itérable. (K, U) et (K, V) seront
transformées en (K, [U, V]).
16161616
Mouna TORJMEN KHEMAKHEM](https://image.slidesharecdn.com/chapitre3-spark-180327112931/85/Chapitre-3-spark-16-320.jpg)
![Exemple d’actions [la librairie standard de Spark] :
reduce(func): applique une réduction à l'ensemble des
données.
collect(): retourne toutes les données contenues dans le RDD
sous la forme de liste.
Les RDDs
count(): retourne le nombre de données contenues dans RDD
takeOrdered(n, key_func): retourne lesnpremiers éléments du
RDD ordonnés selonkey_func.
17171717
Mouna TORJMEN KHEMAKHEM](https://image.slidesharecdn.com/chapitre3-spark-180327112931/85/Chapitre-3-spark-17-320.jpg)

































































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)



