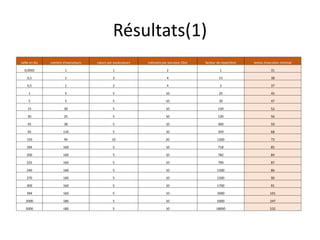
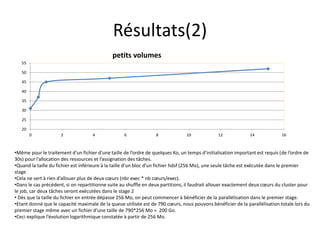
Téléchargé 93 fois


















![Le spark-submit
• Le format général :
bin/spark-submit [options] <app jar | python file> [app options]
• Les options](https://image.slidesharecdn.com/sparkprez2008-150831094442-lva1-app6891/85/spark_intro_1208-28-320.jpg)


![Algorithme spark : Object_func
rule_funct( rule : Rule, cdrs : Iterable[Cdr] ) : Boolean
Return
condition_func(rule.condition(1), cdrs) rule.binaryOperators(1) condition_funct(rule.condition(2),cdrs)
rule.binaryOperators(2) condition_funct(rule.condition(3),cdrs) ……..
condition_func (condition : Condition , cdrs : Iterable[Cdr] ) : Boolean
Condition.comparison_op match {
case « ge » => return operation_funct( condition.operations(1) , cdrs) >= operation_funct( condition.operations(2) ,cdrs)
case « le » => return operation_funct( condition.operations(1) , cdrs) <= operation_funct( condition.operations(2) ,cdrs)
case « g » => return operation_funct( condition.operations(1) , cdrs) > operation_funct( condition.operations(2) , cdrs)
case « l » => return operation_funct( condition.operations(1) , cdrs) < operation_funct( condition.operations(2) , cdrs)
case « eq » => return operation_funct( condition.operations(1) , cdrs) == operation_funct(condition.operations(2) , cdrs)
case « not » => return operation_funct( condition.operations(1) , cdrs) == 0 }
operation_func(Operation : operation , cdrs : Iterable[Cdr] ) : Float
Operation.operation_type match {
case « ratio » => return Function_funct( operations.functions(1) , cdrs) / Function_funct( operations.functions(2) , cdrs)
case « product » => return Function_funct( operations.functions(1) , cdrs) *Function_funct( operations.functions(2) , cdrs)
case « filter » | « static_threshlod » | « counter » => return Function_funct( operations.functions(1) , cdrs)
function_funct (function : Function , cdrs : Iterable[Cdr] ) : Float
Function.function_type match {
case « count » => return cdrs.count(cdr => function.fields.contains(cdr.recordType))
case « static_value » => return function.fields(0).toFloat
case « filter » => return sc.textFile(function.fields(0)).collect().contains(cdr.msisdn)
case « disitinct_count » => countList](https://image.slidesharecdn.com/sparkprez2008-150831094442-lva1-app6891/85/spark_intro_1208-35-320.jpg)
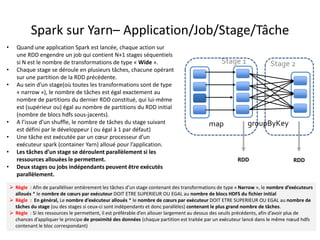
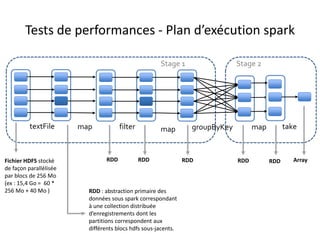
![map groupByKeytextFile
Stage 1 Stage 2
HDFS csv file (or hive
table) of n blocks
data : RDD [String] : primary data
abstraction in Spark. It contains a
distributed set of lines (rows)
Grouped_by_key_data :
Paired_RDD [(key : String
,value : Iterable[Tuple
[String]])]
paired_data : Paired_RDD [
(key : String , value :
Tuple[String]) ]
Result :
Array
[Strings]
Fraud_list: Paired_RDD [(key : String
,value : Iterable[Tuple [String]])]
collect
(*) : source : Learning spark - O'Reilly Media
filter
4 blocks => 4 Tasks in
stage 1
num_executors *
executors_cores > N
!!!!!
numPartions
given as in
input to
groupByKey_
function=>
numPartions
Tasks in
stage 2
numOfPari
tions >
queue_total
_cores (=790
for
« HQ_IST »
queue » !!!
(*)
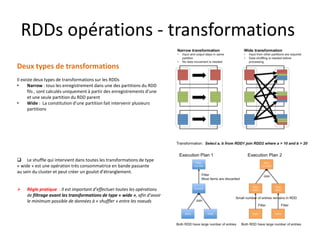
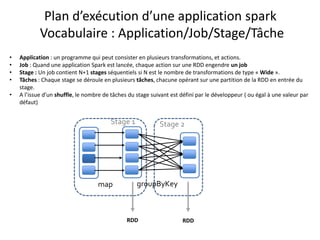
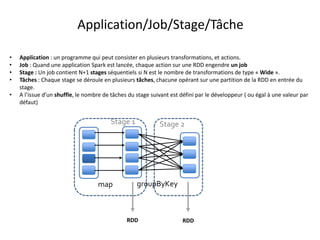
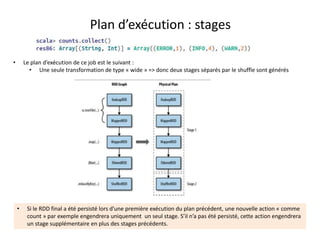
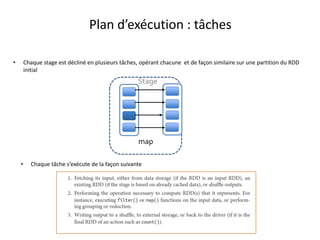
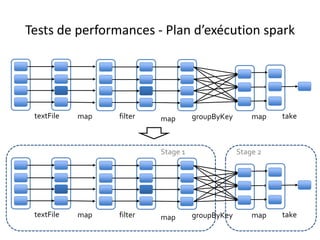
Plan d’exécution
• Supposons que le fichier en entrée est d’une taille de 1Go = 3 * 256Mo + 232Mo (4 blocs hdfs)
• L’application comporte plusieurs transformations sur le RDD et une seule action.
– Un Seul job est donc lancé
– Ce job comporte plusieurs transformations de type Narrow, et une seule transformation de type wide(groupByKey).
– Il comprend donc deux stages séparés par le shuffle
– Le premier stage se déroule sous forme de plusieurs tâches (4 tâches exactement)
– Dans une tâche de ce premier stage, la partition concernée du RDD initial subit toute les transformations du premier stage.
– Le second stage comprend un nombre de tâches exactement égal à la valeur de repartitionnement donnée en paramètre à la fonction
groupByKey (3 partitions dans l’illustration ci-dessous)](https://image.slidesharecdn.com/sparkprez2008-150831094442-lva1-app6891/85/spark_intro_1208-36-320.jpg)



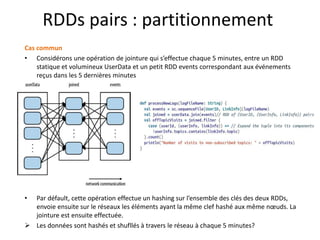
![Créer un RDD pair (implicite)
Principe de la conversion Implicite :
certaines transformations de RDD ne sont applicables que sur certains types particuliers de RDD. (ex : mean() and variance() sur
les RDD[Double] ou join() sur les RDDs “(clef,valeur)” .
Il s’agit en effet de types différents de RDD, chacun avec sa propre API. En appliquant la transformation groupByKey sur un RDD
contenant des tuples (clef/valeur), il s’agit de la méthode groupByKey de la classe « PairedRDD » qui s’exécute et non pas celle
de la classe « RDD » (car elle n’existe pas dans cette classe). Aucune déclaration explicite n’est nécessaire.
Aussi faudrait il faire attention à ne pas consulter la sclaladoc de la classe RDD pour chercher une transformation qui s’applique
uniquement sur les RDD pairs.](https://image.slidesharecdn.com/sparkprez2008-150831094442-lva1-app6891/85/spark_intro_1208-40-320.jpg)





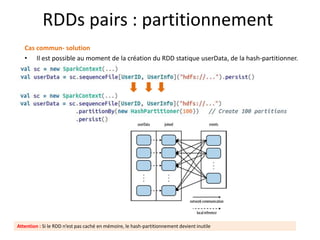












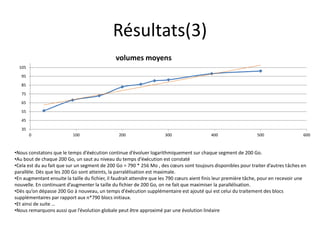
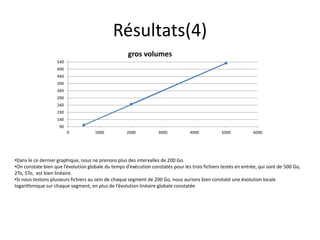

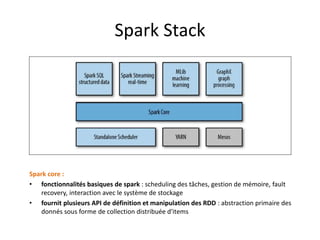
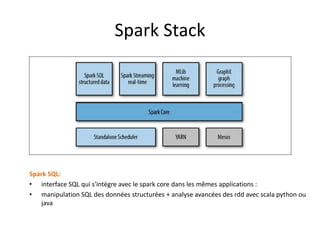
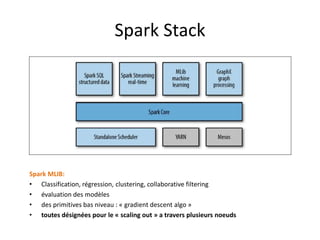
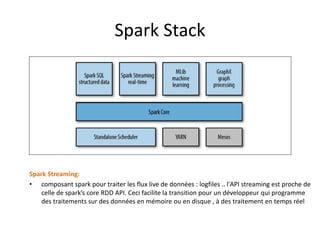
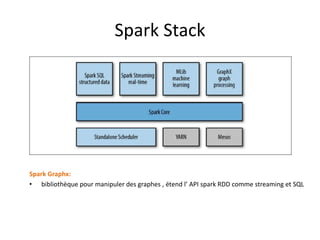
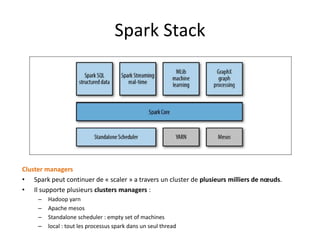
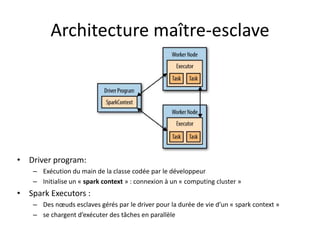
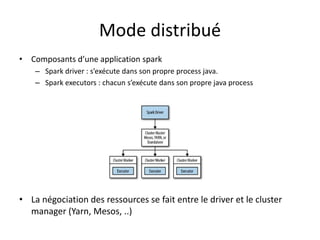
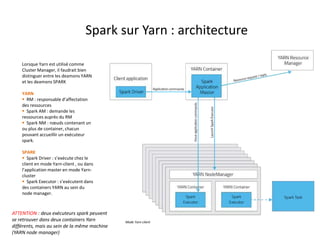
Spark est une plateforme de traitement distribué conçue pour une grande rapidité et une flexibilité d'utilisation via des APIs pour manipuler des données. Elle intègre différentes bibliothèques pour des tâches comme le traitement en temps réel (Spark Streaming), l'analyse de graphes (GraphX), et le machine learning (MLlib). Spark fonctionne efficacement en utilisant des RDDs (Resilient Distributed Datasets) qui représentent des collections de données distribuées, et emploie un modèle maître-esclave pour la gestion des tâches au sein d'un cluster.



































































