Télécharger en tant que PDF, PPTX











































![05/11/2019 Spark 52
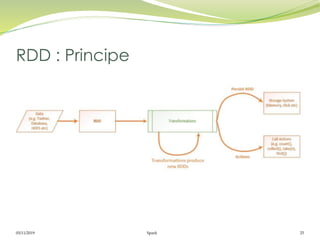
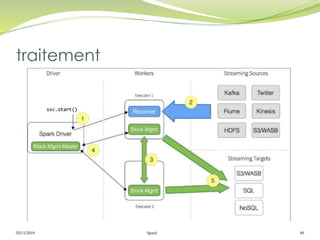
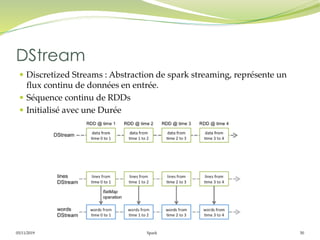
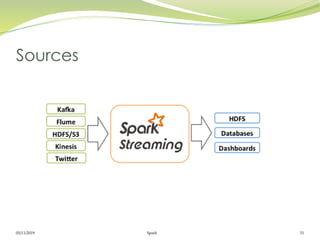
Operations de transformation
Similaire aux RDD
map(), flatMap(), filter(), repartition(numPartitions), union(otherStream),
count(), reduce(), countByValue(), reduceByKey(func, [numTasks]),
join(otherStream, [numTasks]), cogroup(otherStream, [numTasks]),
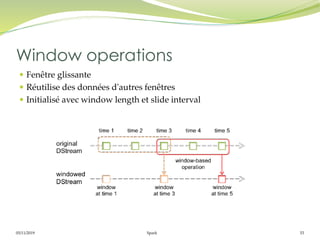
transform(), updateStateByKey(), Window()
Operations de sortie (Output Operations)
Les données Dstream sont envoyées à un système externe comme une bd
ou un système de fichier en utilisant les opérations de sortie.
print(), saveAsTextFiles(prefix, [suffix]), saveAsObjectFiles(prefix, [suffix]),
saveAsHadoopFiles(prefix, [suffix]), foreachRDD(func)
Operations](https://image.slidesharecdn.com/spark-200309132216/85/Spark-52-320.jpg)















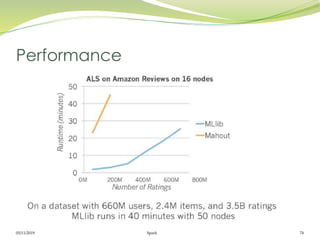
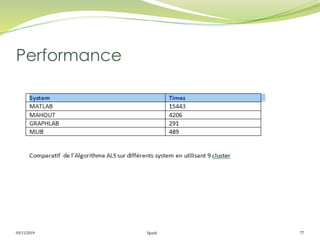
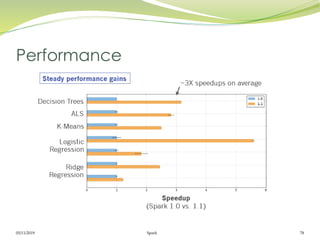

Le document présente Apache Spark, un framework unifié pour le traitement des big data, permettant d'exécuter des applications jusqu'à 100 fois plus vite qu'Hadoop. Il couvre des aspects tels que les RDD, Spark Streaming, Spark SQL, et son architecture master/slave, tout en mettant en avant sa capacité à maintenir des résultats intermédiaires en mémoire. Enfin, il détaille les principaux composants et fonctionnalités qui rendent Spark adapté pour le traitement parallèle et distribué des données.





































































