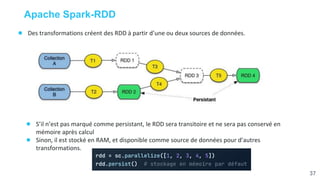
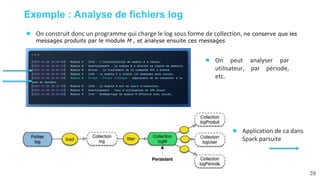
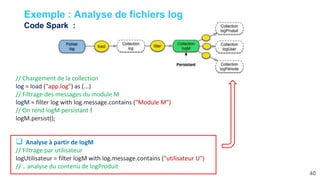
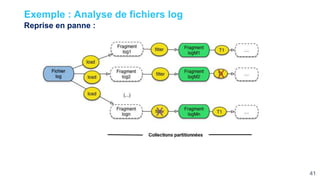
Ce document présente une étude approfondie d'Apache Spark, un moteur de traitement de données massives open source. Il aborde divers aspects tels que le traitement par lot et en continu, l'architecture de Spark, et la gestion des RDD (Resilient Distributed Datasets). Les caractéristiques clés de Spark, y compris sa capacité de traitement en mémoire et son intégration avec d'autres outils de big data, sont également discutées.











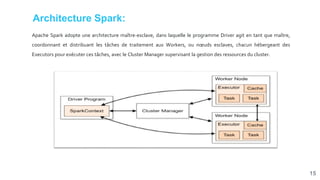
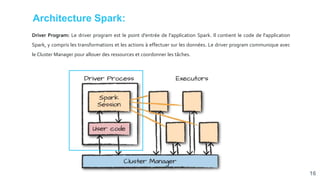
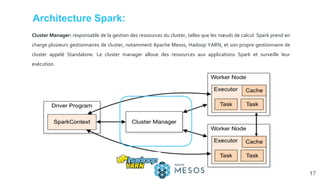
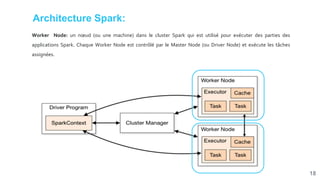
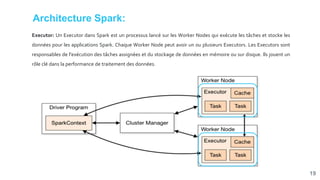
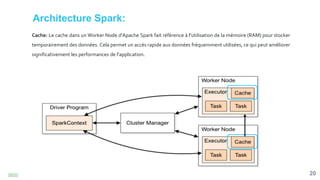
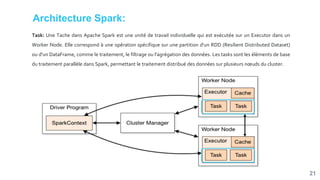
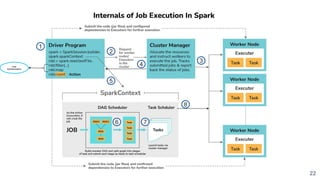
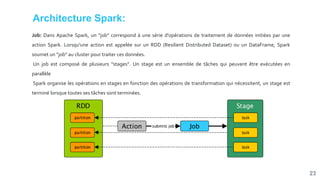






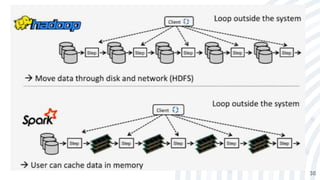
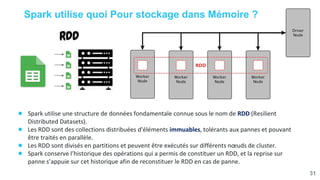

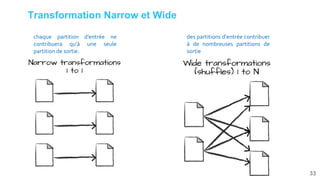













































![[Smile] atelier spark - salon big data 13032018](https://cdn.slidesharecdn.com/ss_thumbnails/smile-atelierspark-salonbigdata13032018-180328084149-thumbnail.jpg?width=640&height=640&fit=bounds)


















