Téléchargé 4 075 fois



















![Planification et conduite du projet
L’initiation de tout projet nécessite une phase de planification. Celle
out Celle-ci permet
de définir les tâches à réaliser, maîtriser les risques et rendre compte de l’état d’avancement
du projet.
« Planifier optimise ainsi les chances de réussite d'un projet en améliorant la
productivité grâce à une meilleure maîtrise de la qualité. » [Soler, 2001].
Pour garantir le bon déroulement du projet, tout en respectant les délais, nous avons
élaboré une planification globale de conduite du projet. Le diagramme suivant décrit cette
planification ainsi que l’ordonnancement prévu des phases du projet.
Conception E.T.L
Figure : Planification et conduite du projet.
Afin de présenter notre travail, le présent mémoire est organisé en trois parties et se
présente comme suit :
Après une introduction générale dans laquelle nous présentons le contexte général du
projet, ainsi que la problématique et les objectifs visés. La première partie présente les aspects
théoriques du domaine des systèmes d’information d’aide à la décision, en évoquant leurs
définitions et les concepts de bases relatifs aux « entrepôts de données » et à la modélisation
dimensionnelle.
12](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-20-320.jpg)


![I. Introduction
Toutes les entreprises du monde disposent d’une masse de données plus ou moins
considérable. Ces informations proviennent soit de sources internes (générées par leurs
systèmes opérationnels au fil des activités journalières), ou bien de sources externes (web,
partenaire, .. etc.).
Cette surabondance de données, et l’impossibilité des systèmes opérationnels de les
exploiter à des fins d’analyse conduit, inévitablement, l’entreprise à se tourner vers une
nouvelle informatique dite décisionnelle qui met l’accent sur la compréhension de
l’environnement de l’entreprise et l’exploitation de ces données à bon escient.
En effet, les décideurs de l’entreprise ont besoin d’avoir une meilleure vision de leur
environnement et de son évolution, ainsi, que des informations auxquelles ils peuvent se fier.
Cela ne peut se faire qu’en mettant en place des indicateurs « business » clairs et pertinents
permettant la sauvegarde, l’utilisation de la mémoire de l’entreprise et offrant à ses décideurs
la possibilité de se reporter à ces indicateurs pour une bonne prise de décision.
Le « Data Warehouse », « Entrepôt de données » en français, constitue, dans ces
conditions, une structure informatique et une fondation des plus incontournables pour la mise
en place d’applications décisionnelles.
Le concept de Data Warehouse, tel que connu aujourd’hui, est apparu pour la première
fois en 1980 ; l’idée consistait alors à réaliser une base de données destinée exclusivement au
processus décisionnel. Les nouveaux besoins de l’entreprise, les quantités importantes de
données produites par les systèmes opérationnels et l’apparition des technologies aptes à sa
mise en œuvre ont contribué à l’apparition du concept « Data Warehouse » comme support
aux systèmes décisionnels.
I.1. Les systèmes décisionnels
La raison d’être d’un entrepôt de données, comme évoqué précédemment, est la mise en
place d’une informatique décisionnelle au sein de l’entreprise. Pour cela il serait assez
intéressant de définir quelques concepts clés autour du décisionnel.
Afin de mieux comprendre la finalité des systèmes décisionnels, nous nous devons de les
placer dans leurs contextes et rappeler ce qu’est un système d’information.
«Le système d’information est l’ensemble des méthodes et moyens de recueil de contrôle
et de distribution des informations nécessaires à l’exercice de l’activité en tout point de
l’organisation. Il a pour fonction de produire et de mémoriser les informations, de l’activité
du système opérant (système opérationnel), puis de les mettre à disposition du système de
décision (système de pilotage)»[Le Moigne, 1977].
Les différences qui existent entre le système de pilotage et le système opérationnel, du
point de vue fonctionnel ou des tâches à effectuer, conduit à l’apparition des « systèmes
d’information décisionnels » (S.I.D.). Ces différences seront clairement illustrées un peu plus
loin dans notre document.
15](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-23-320.jpg)
![Les origines des SID remontent au début de l’informatique et des systèmes d’information
qui ont, tous deux, connu une grande et complexe évolution liée notamment à la technologie.
Cette évolution se poursuit à ce jour2.
Parmi les différentes définitions du décisionnel « business intelligence B.I. » qui ont été
données on trouve :
• "Le Décisionnel est le processus visant à transformer les données en informations et,
par l'intermédiaire d'interrogations successives, transformer ces informations en
connaissances." [Dresner, 2001].
I.1.1. La place du décisionnel dans l’entreprise:
Figure I.1 : Le décisionnel au sein du Système d’information [Goglin, 1998]
nnel 1998].
La figure ci-dessus illustre parfaitement la place qu revient au décisi
dessus qui décisionnel au sein
d’une entreprise. Cette place, comprend plusieurs fonctions clés de l’entreprise. Les finalités
,
décisionnelles, étant différentes selon le poste et la fonction occupée on pour but
occupée, ont
d’engendrer plusieurs composantes.
2
Synthétisation à partir de la thèse de Bouzghoub A. « Modélisation des entrepôts de données XML:
application au domaine de la sécurité sociale » [Bouzghoub, 2008].
16](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-24-320.jpg)
![I.1.2. Les différentes composantes du décisionnel
s
En relation étroite avec les nouvelles technologies de l’information et des
télécommunications, le système décisionnel se manifeste à différents niveaux selon leurs
e
utilités et leurs missions principales comme illustré dans la figure suivante :
principales,
Figure I.2 : Les différentes composantes du décisionnel [Goglin, 1998]
1998].
17](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-25-320.jpg)

![II. Le Data Warehouse
II.1 Qu’est ce qu’un Data Warehouse
Bill Inmon définit le Data Warehouse, dans son livre considéré comme étant la référence
dans le domaine “Building the Data Warehouse” [Inmon, 2002] comme suit:
« Le Data Warehouse est une collection de données orientées sujet, intégrées, non
volatiles et évolutives dans le temps, organisées pour le support d’un processus d’aide à
la décision. »
Les paragraphes suivants illustrent les caractéristiques citées dans la définition d’Inmon.
Orienté sujet : le Data Warehouse est organisé autour des sujets majeurs de l’entreprise,
contrairement à l’approche transactionnelle utilisée dans les systèmes opérationnels, qui sont
conçus autour d’applications et de fonctions telles que : cartes bancaires, solvabilité client…,
les Data Warehouse sont organisés autour de sujets majeurs de l’entreprise tels que : clientèle,
ventes, produits…. Cette organisation affecte forcément la conception et l’implémentation des
données contenues dans le Data Warehouse. Le contenu en données et en relations entre elles
diffère aussi. Dans un système opérationnel, les données sont essentiellement destinées à
satisfaire un processus fonctionnel et obéit à des règles de gestion, alors que celles d’un Data
Warehouse sont destinées à un processus analytique.
Intégrée : le Data Warehouse va intégrer des données en provenance de différentes sources.
Cela nécessite la gestion de toute incohérence.
Evolutives dans le temps : Dans un système décisionnel il est important de conserver les
différentes valeurs d’une donnée, cela permet les comparaisons et le suivi de l’évolution des
valeurs dans le temps, alors que dans un système opérationnel la valeur d’une donnée est
simplement mise à jour. Dans un Data Warehouse chaque valeur est associée à un moment
« Every key structure in the data warehouse contains - implicitly or explicitly -an element of
time » [Inmon, 2000].
Non volatiles : c’est ce qui est, en quelque sorte la conséquence de l’historisation décrite
précédemment. Une donnée dans un environnement opérationnel peut être mise à jour ou
supprimée, de telles opérations n’existent pas dans un environnement Data Warehouse.
Organisées pour le support d’un processus d’aide à la décision : Les données du Data
Warehouse sont organisées de manière à permettre l’exécution des processus d’aide à la
décision (Reporting, Data Mining…).
19](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-27-320.jpg)

![II.3 Structure des données d’un Data Warehouse
Le Data Warehouse a une structure bien définie, selon différents niveaux d’agrégation
et de détail des données. Cette structure est définie par Inmon [Inmon, 2000] comme suit :
Données fortement agrégées
M Données agrégées
E
T
A
D
O
N
N Données détaillées
É
E
S
Données détaillées archivées
Figure I.4 : Structure des données d’un Data Warehouse.
Données détaillées : ce sont les données qui reflètent les événements les plus récents,
fréquemment consultées, généralement volumineuses car elles sont d’un niveau détaillé.
Données détaillées archivées : anciennes données rarement sollicitées, généralement
stockées dans un disque de stockage de masse, peu coûteux, à un même niveau de détail que
les données détaillées.
Données agrégées : données agrégées à partir des données détaillées.
Données fortement agrégées : données agrégées à partir des données détaillées, à un niveau
d’agrégation plus élevé que les données agrégées.
21](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-29-320.jpg)
![Meta données : ce sont les informations relatives à la structure des données, les méthodes
d’agrégation et le lien entre les données opérationnelles et celles du Data Warehouse. Les
métadonnées doivent renseigner sur :
• Le modèle de données,
• La structure des données telle qu’elle est vue par les développeurs,
• La structure des données telle qu’elle est vue par les utilisateurs,
• Les sources des données,
• Les transformations nécessaires,
• Suivi des alimentations,
II.4 Les éléments d’un Data Warehouse
L’environnement du Data Warehouse est constitué essentiellement de quatre
composantes : les applications opérationnelles, la zone de préparation des données, la
présentation des données et les outils d’accès aux données.
Les applications opérationnelles : ce sont les applications du système opérationnel de
l’entreprise et dont la priorité est d’assurer le fonctionnement de ce dernier et sa performance.
Ces applications sont extérieures au Data Warehouse.
Préparation des données : la préparation englobe tout ce qu’il y a entre les applications
opérationnelles et la présentation des données. Elle est constituée d’un ensemble de processus
appelé ETL, « Extract, transform and Load », les données sont extraites et stockées pour subir
les transformations nécessaires avant leur chargement.
« Un point très important, dans l’aménagement d’un entrepôt de données, est
d’interdire aux utilisateurs l’accès à la zone de préparation des données, qui ne fournit aucun
service de requête ou de présentation » [Kimball, 2002].
Présentation des données : c’est l’entrepôt où les données sont organisées et stockées. Si les
données de la zone de préparation sont interdites aux utilisateurs, la zone de présentation est
tout ce que l’utilisateur voit et touche par le biais des outils d’accès.
L’entrepôt de données est constitué d’un ensemble de Data Mart. Ce dernier est défini
comme étant une miniaturisation d’un Data Warehouse, construit autour d’un sujet précis
d’analyse ou consacré à un niveau départemental3.
Cette différence de construction, autour d’un sujet ou au niveau départemental, définit
la façon d’implémentation du Data Mart au niveau de l’entrepôt. On distingue, en effet, deux
architectures internes du Data Warehouse :
3
Synthétisation [Chuck, 1998] page 86.
22](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-30-320.jpg)
![1. Data Mart indépendant
Les Data Mart sont des versions miniaturisées du Data Warehouse au niveau
départemental, alimentées par le Data Warehouse et basées sur les besoins départementaux en
s s
informations [Inmon, 2002].
Figure I.5 : les Data Mart dans un entrepôt de données selon l’architecture Entreprise Data
Warehouse (E.D.W) [Inmon, 2002].
23](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-31-320.jpg)
![2. Data Mart interconnectés
Les Data Mart sont construi autour de sujets, interconnectés grâce aux tables des
es construits
faits contenues dans le Data Warehouse, ce dernier se compose alors des Data Mart et ces
tables des faits, appelées bus4.
Figure I.6 : les Data Mart dans un entrepôt de données selon l’architecture bus de données
[Kimball, 2002].
Zone d’outils d’accès : c’est l’ensemble des moyens fournis aux utilisateurs du Data
Warehouse pour exploiter la zone de présentation des données en vue de la prise de décision.
Ces outils varient des simples requêtes ad hoc aux outils permettant l’application de forage de
données plus complexes. Environ 80 à 90% des utilisateurs sont desservis par des applications
.
d’analyses préfabriquées, consista essentiellement en des requêtes préétablies.
ant s.
4
Appellation proposée par R. Kimball dans son ouvrage [Kimball, 2002].
24](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-32-320.jpg)


![Figure I.9 : Un modèle dimensionnel typique [Kimball, 1996].
III.1.1 Concept de fait
Une table de faits est la table centrale d’un modèle dimensionnel, où les mesures de
performances sont stockées. Une ligne d’une table de faits correspond à une mesure. Ces
mesures sont généralement des valeurs numériques, additives ; cependant des mesures
textuelles peuvent exister mais sont rares. Le concepteur doit faire son possible pour faire des
mesures textuelles des dimensions, car elles peuvent êtres corrélées efficacement avec les
autres attributs textuels de dimensions.
Une table de faits assure les liens plusieurs à plusieurs entre les dimensions. Elles
comportent des clés étrangères, qui ne sont autres que les clés primaires des tables de
dimension.
III.1.2 Concept de dimension
Les tables de dimension sont les tables qui raccompagnent une table de faits, elles
contiennent les descriptions textuelles de l’activité. Une table de dimension est constituée de
nombreuses colonnes qui décrivent une ligne. C’est grâce à cette table que l’entrepôt de
données est compréhensible et utilisable; elles permettent des analyses en tranches et en dés.
Une dimension est généralement constituée : d’une clé artificielle, une clé naturelle et
des attributs.
« Une table de dimension établit l’interface homme / entrepôt, elle comporte une clé
primaire » [Kimball, 2002].
27](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-35-320.jpg)

![III.3 Le concept OLAP
III.3.1 Généralités
Le terme OLAP (On-Line Analytical Processing) désigne une classe de technologies
conçue pour l’accès aux données et pour une analyse instantanée de ces dernières, dans le but
de répondre aux besoins de Reporting et d’analyse.
R. Kimball définit le concept « OLAP » comme «Activité globale de requêtage et de
présentation de données textuelles et numériques contenues dans l’entrepôt de données; Style
d’interrogation spécifiquement dimensionnel » [Kimball, 2005].
C’est en continuant sur sa lancée, qui lui a permis de définir le model OLTP pour les
bases de données relationnelles, que le concept OLAP fut introduit et défini6 en 1993 par E.F
Codd, le père des bases de données relationnelles, dans un document technique portant le titre
de « Providing OLAP (On-Line Analytical Processing) to User-Analysts : An IT Man-date »
[Codd, 1993].
III.3.2 Architectures des serveurs OLAP
Le noyau d’un système OLAP est son serveur. Ces serveurs sont classés selon la politique
régissant l’architecture du serveur. Ainsi, ces architectures peuvent être distinguées comme
suit:
III.3.2.1 Les systèmes à architecture MOLAP
Ces systèmes MOLAP « Multidimentional On-line Analytical Processing » sont
conçus exceptionnellement pour l’analyse multidimensionnelle.
R. Kimball définit ces systèmes comme étant un « Ensemble d’interfaces utilisateur,
d’applications et de technologies de bases de données propriétaire dont l’aspect dimensionnel
est prépondérant » [Kimball, 2005].
Ainsi donc cette base adopte réellement la structure multidimensionnelle, exploitant de
ce fait ces capacités au maximum. En effet MOLAP offre des temps d’accès optimisés et cela
en prédéfinissant les opérations de manipulation et de chemin d’accès prédéfinis.
Autre caractéristique du MOLAP c’est qu’il agrège tout par défaut, pénalisant du coup
le système lorsque la quantité de données à traiter augmente. On parle généralement de
volume de l’ordre du giga-octet pas plus.
6
Cette définition passe par l’introduction de 12 règles. Six autres règles furent par la suite, en 1995, ajoutées
aux 12 précédentes et le terme « règles » remplacé par dispositif «features » par le même auteur à savoir
Codd (Voir annexe B).
29](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-37-320.jpg)
![Data Warehouse Moteur MOLAP Aide à la décision
Données Traitements Présentation
Stockage des Rapports
données détaillées (et Multi-Dimensionnel
agrégées)
Figure I.10 :Principe de l’architecture MOLAP [Nakache, 1998].
III.3.2.2 Les systèmes à architecture ROLAP
« Ensemble d’interfaces utilisateurs et d’applications qui donnent une vision
dimensionnelle à des bases de données relationnelles » [Kimball, 2005].
Les systèmes ROLAP « Relationnel On-line Analytical Processing » sont en mesure
de simuler le comportement d’une SGBD multidimensionnel en exploitant un SGBD
relationnel. L’utilisateur aura ainsi l’impression d’interroger un cube multidimensionnel alors
qu’en réalité il ne fait qu’adresser des requêtes sur une base de données relationnelles.
ROLAP n’agrège rien. Les règles d’agrégations sont crées au préalable et représentées
dans une table relationnelle ce qui cause une lourdeur d’administration mais confère une
certaine performance et un gage de cohérence lors de l’utilisation.
Cette structure est généralement adoptée dans le but de se dispenser de l’acquisition
d’un SGBD relationnel.
Data Warehouse Moteur ROLAP Aide à la décision
Données Traitements Présentation
Stockage des Génération de plans Rapports
données détaillées (et d'exécution SQL Multi-Dimensionnel
agrégées) et afin d'obtenir des
des méta-données fonctionnalités OLAP.
Figure I.11 : Principe de l’architecture ROLAP [Nakache, 1998].
30](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-38-320.jpg)
![III.2.2.3 Les systèmes à architecture HOLAP
Les systèmes HOLAP « Hybride On-line Analytical Processing » sont une sorte de
compromis entre les différents systèmes précités. Cette combinaison donne à ce type de
système les avantages du ROLAP et du MOLAP en utilisant tour à tour l’un ou l’autre selon
le type de données.
III.2.2.4 Autres architecture OLAP
Bien que les architectures évoquées ci-dessus soient les plus répandues et les plus
adoptées par les fournisseurs de solutions OLAP, d’autres systèmes se basent sur des
architectures différentes telles que l’architecture OOLAP « Object On-line Analytical
Processing », ou alors DOLAP « Desktop On-line Analytical Processing » qui décrit une
catégorie de produits qui ne sont pas nécessairement connectés à un serveur et qui s’appuient
sur une source de données (un cube) construites, stockées et exploitées en local sur la machine
de l’utilisateur.
III.4 La navigation dans les données
Une fois que le serveur OLAP a construit le cube multidimensionnel « ou simulé ce
cube selon l’architecture du serveur », plusieurs opérations sont possibles sur ce dernier
offrant ainsi la possibilité de naviguer dans les données qui le constituent. Ces opérations de
navigation « Data Surfing » doivent être, d’une part, assez complexes pour adresser
l’ensemble des données et, d’autre part, assez simples afin de permettre à l’utilisateur de
circuler de manière libre et intuitive dans le modèle dimensionnel.
Afin de répondre à ces attentes, un ensemble de mécanismes est exploité, permettant
une navigation par rapport à la dimension et par rapport à la granularité d’une dimension.
III.4.1 Slice & Dice
Le « Slicing » et le « Dicing » sont des techniques qui offrent la possibilité de faire
des tranches « trancher » dans les données par rapport à des filtres de dimension bien précis,
se classant de fait comme des opérations liées à la structure « se font sur les dimensions ». La
différence entre eux se manifestent dans le fait que :
Le Slicing consiste à faire une sélection de tranches du cube selon des prédicats et
selon une dimension « filtrer une dimension selon une valeur » [Chouder, 2008].
31](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-39-320.jpg)

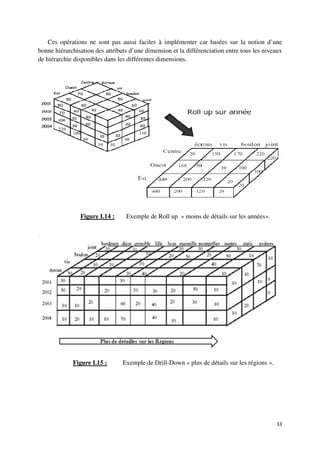
![IV. Démarche de Construction d’un Data Warehouse
Plusieurs chercheurs ou équipes de recherche ont essayé de proposer des démarches
pour la réalisation d’un projet Data Warehouse, ces démarches se croisent essentiellement
dans les étapes suivantes :
• Modélisation et conception du Data Warehouse,
• Alimentation du Data Warehouse,
• Mise en œuvre du Data Warehouse,
• Administration et maintenance du Data Warehouse,
IV.1 Modélisation et conception du Data Warehouse
Les deux approches les plus connues dans la conception des Data Warehouse sont :
• L’approche basée sur les besoins d’analyse,
• L’approche basée sur les sources de données,
Aucune des deux approches citées n’est ni parfaite, ni applicable à tous les cas. Toutes
deux doivent être étudiées pour choisir celle qui s’adapte le mieux à notre cas.
Quelque soit l’approche adoptée pour la conception d’un Data Warehouse, la
définition de celui-là reste la même. En étant un support d’aide à la décision, le Data
Warehouse se base sur une architecture dimensionnelle.
IV.1.1 Approche « Besoins d’analyse »
Le contenu du Data Warehouse sera déterminé selon les besoins de l’utilisateur final.
Cette approche est aussi appelée « approche descendante » (Top-Down Approach) et est
illustrée par R. Kimball grâce à son cycle de vie dimensionnel comme suit :
Figure I.16 : illustration de l’approche « Besoins d’analyse » grâce au cycle de vie
dimensionnel de Kimball [Kimball, 2004].
34](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-42-320.jpg)
![Avantages Inconvénients
Aucun risque de concevoir une solution Pas de prise en compte de l’évolution des
obsolète avant d’être opérationnelle besoins de l’utilisateur. Nécessite une
modification de la structure du Data
Warehouse en cas de nouveau besoin
Négligence du système opérationnel
Difficulté de déterminer les besoins des
utilisateurs
Tableau I.3 : Avantages et inconvénients de l’approche « Besoins d’analyse ».
IV.1.2 Approche « Source de données »
Le contenu du Data Warehouse est déterminé selon les sources de données. Cette
approche est appelée : Approche ascendante (Bottom-up Approach).
Figure I.17 : Illustration de l’approche « Source de données » grâce au cycle de
développement du DW de Inmon [Inmon, 2002].
35](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-43-320.jpg)
![Inmon considère que l’utilisateur ne peut jamais déterminer ses besoins dès le départ,
« Donnez moi ce que je vous demande, et je vous direz ce dont j’ai vraiment besoin »7, il
considère que les besoins sont en constante évolution.
Avantages Inconvénients
Meilleure prise en charge de l’évolution des Risque de concevoir une solution obsolète
besoins avant qu’elle soit opérationnelle
Evolution du schéma des données source
Complexité de source de données
Tableau I.4 : Avantages et inconvénients de l’approche « Sources de données».
IV.1.3 Approche mixte
Une combinaison des deux approches appelée hybride ou mixte peut s’avérer efficace.
Elle prend en considération les sources de données et les besoins des utilisateurs.
Cette approche consiste à construire des schémas dimensionnels à partir des structures
des données du système opérationnel, et les valider par rapport aux besoins analytiques. Cette
approche cumule les avantages et quelques inconvénients des deux approches déjà citées,
telles que la complexité des sources de données et la difficulté quant à la détermination des
besoins analytiques.
Figure I.18 : Illustration de l’approche mixte.
“Give me what I tell you I want, then I can tell you what I really want.”[Inmon, 2002]
7
36](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-44-320.jpg)
![Cette étape aboutit à l’établissement du modèle dimensionnel validé du Data
Warehouse. Ce modèle dimensionnel sera transformé en modèle physique, qui différera du
modèle dimensionnel.
IV.2 Alimentation du Data Warehouse
Une fois le Data Warehouse conçu, il faut l’alimenter et le charger en données. Cette
alimentation (le plus souvent appelée processus ETL « Extract-Transform-Load ») se déroule
en 3 phases qui sont :
• Extraction des données primaires (issues par exemple des systèmes de production),
• Transformation des données,
• Le chargement des données traitées dans l’entrepôt de données,
Ces trois étapes décrivent une mécanique cyclique qui a pour but de garantir
l’alimentation du Data Warehouse en données homogènes, propres et fiables.
IV.2.1 Les phases de l’alimentation « E.T.L. »
Les phases du processus E.T.L. représentent la mécanique d’alimentation du Data
Warehouse. Ainsi elles se déroulent comme suit :
a) L’extraction des données
« L’extraction est la première étape du processus d’apport de données à l’entrepôt de
données. Extraire, cela veut dire lire et interpréter les données sources et les copier dans la
zone de préparation en vue de manipulations ultérieures. » [Kimball, 2005].
Elle consiste en :
• Cibler les données,
• Appliquer les filtres nécessaires,
• Définir la fréquence de chargement,
Lors du chargement des données, il faut extraire les nouvelles données ainsi que les
changements intervenus sur ces données. Pour cela, il existe trois stratégies de capture de
changement :
• Colonnes d’audit : la colonne d’audit, est une colonne qui enregistre la date
d’insertion ou du dernier changement d’un enregistrement. Cette colonne est mise à jour soit
par des triggers ou par les applications opérationnelles, d’où la nécessité de vérifier leur
fiabilité.
• Capture des logs : certains outils ETL utilisent les fichiers logs des systèmes sources
afin de détecter les changements (généralement logs du SGBD). En plus de l’absence de cette
fonctionnalité sur certains outils ETL du marché, l’effacement des fichiers logs engendre la
perte de toute information relative aux transactions.
37](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-45-320.jpg)

![Aussi, le processus d’alimentation doit répondre à certaines exigences illustrées par la
figure suivante :
Être correctif
Être rapide Être sûr
Processus
ETL
Être transparent
Figure I.19 : Objectif de qualité de données dans un processus ETL [Kimball, 2004].
• Sûr : assure l’acheminement des données et leur livraison.
• Rapide : la quantité de données manipulées peut causer des lenteurs. Le processus
d’alimentation doit palier à ce problème et assurer le chargement du Data Warehouse dans des
délais acceptables.
• Correctif : le processus d’alimentation doit apporter les correctifs nécessaires pour
améliorer la qualité des données.
• Transparent : le processus de l’ETL doit être transparent afin d’améliorer la qualité
des données.
39](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-47-320.jpg)
![IV.2.3 Les outils E.T.L.
Les outils E.T.L, en français E.T.C « Extraction-Transformation-Chargement » [Kimball,
2005], sont des outils qui garantissent la faisabilité et facilitent le déroulement des trois phases
citées précédemment. D’où leur importance dans un projet Data Warehouse.
IV.3 Mise en œuvre du Data Warehouse
C’est la dernière étape d’un projet Data Warehouse, soit son exploitation. L’exploitation
du Data Warehouse se fait par le biais d’un ensemble d’outils analytiques développés autour
du Data Warehouse. Donc cette étape nécessite l’achèvement du développement, ou de la
mise en place, de ces outils qui peuvent accomplir les fonctions suivantes:
a. Requêtage ad-hoc :
Le requêtage ad-hoc reste très fréquent dans ce type de projet. En effet, les utilisateurs
de l’entrepôt de données, et spécialement les analystes, seront amenés à interagir avec le DW
via des requêtes ad-hoc dans le but de faire les analyses requises par leurs métiers et,
d’élaborer aussi, des rapports et des tableaux de bords spécifiques.
L’accès à ce genre de service peut se faire via différentes méthodes et outils.
Cependant, les spécialistes en la matière préconisent de laisser la possibilité à l’utilisateur de
choisir les outils qui lui paraissent les plus adéquats.
b. Reporting :
Destiné essentiellement à la production de rapports et de tableaux de bord, « il est la
présentation périodique de rapports sur les activités et résultats d'une organisation, d'une
unité de travail ou du responsable d'une fonction, destinée à en informer ceux chargés de les
superviser en interne ou en externe, ou tout simplement concernés par ces activités ou
résultants »9.
Ces outils de Reporting ne sont pas, à proprement parler, des instruments d'aide à la
décision, mais, lorsqu’ils sont utilisés de manière appropriée, ils peuvent fournir une précieuse
vue d’ensemble.
Les rapports sont alors crées par le biais d’outils de Reporting qui permettent de leur
donner un format prédéterminé. Les requêtes sont constituées lors de l’élaboration des
rapports qui seront ensuite diffusés périodiquement en automatique ou ponctuellement à la
demande.
9
http://fr.wikipedia.org/wiki/Reporting
40](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-48-320.jpg)
![c. Analyse dimensionnelle des données:
L’analyse dimensionnelle est sans doute celle qui exploite et fait ressortir au mieux les
capacités de l’entrepôt de données. Le but par l’analyse dimensionnelle est d’offrir aux
utilisateurs la possibilité d’analyser les données selon différents critères afin de confirmer une
tendance ou suivre les performances de l’entreprise.
Cette analyse se fait selon le principe OLAP, offrant de ce fait aux utilisateurs les
possibilités de recourir à différentes opérations facilitant la navigation dans les données. La
mise en place de ces outils est une option très intéressante dans la mesure où les données
seront accessibles en analyses instantanées. Plusieurs fournisseurs de solution OLAP existent
sur le marché et offrent des solutions construites sur des méthodes et technologies différentes.
C’est d’ailleurs pour cela que le choix de la solution doit se faire au préalable, selon les
besoins en utilisation, la taille de l’entrepôt et les moyens techniques disponibles.
d. Tableaux de bord :
Les tableaux de bord sont un outil de pilotage qui donne une vision sur l’évolution
d’un processus, afin de permettre aux responsables de mettre en place des actions correctives.
« Le tableau de bord est un ensemble d’indicateurs peu nombreux conçus pour
permettre aux gestionnaires de prendre connaissance de l’état et de l’évolution des systèmes
qu’ils pilotent et d’identifier les tendances qui les influenceront sur un horizon cohérent avec
la nature de leurs fonctions » [Bouquin, 2003].
Cette forme de restitution a la particularité de se limiter à l’essentiel, c'est-à-dire la
mise en évidence de l’état d’un indicateur par rapport à un objectif, tout en adoptant une
représentation graphique de l’information.
e. Data Mining :
Au sens littéral du terme, le Data Mining signifie le forage de données. Le but de ce
forage est d’extraire de la matière brute qui, dans notre cas, représente de nouvelles
connaissances. L’idée de départ veut qu’il existe dans toute entreprise des connaissances
utiles, cachées sous des gisements de données. Le Data Mining permet donc, grâce à un
certain nombre de techniques, de découvrir ces connaissances en faisant apparaître des
corrélations entre ces données.
Le Data Warehouse constituera alors la première source de données sur laquelle
s’exécutera le processus de découverte de connaissances. Dans la majeure partie du temps,
l’entrepôt de données représente un pré requis indispensable à toute fouille de données.
Le recours à ce genre de méthode est de plus en plus utilisé dans les entreprises
modernes. Les applications et outils implémentant ces solutions sont rarement développés en
interne. En effet, les entreprises préfèrent se reposer sur des valeurs sûres du marché afin
d’exploiter au plus vite les données en leur possession.
41](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-49-320.jpg)
![IV.4 Maintenance et expansion
La mise en service du Data Warehouse ne signifie pas la fin du projet, car un projet
Data Warehouse nécessite un suivi constant compte tenu des besoins d’optimisation de
performance et ou d’expansion. Il est donc nécessaire d’investir dans les domaines suivants
[Kimball, 2002] :
Support : assurer un support aux utilisateurs pour leur faire apprécier l’utilisation de
l’entrepôt de données. En outre, la relation directe avec les utilisateurs permet de détecter les
correctifs nécessaires à apporter.
Formation : il est indispensable d’offrir un programme de formation permanant aux
utilisateurs de l’entrepôt de données.
Support technique : un entrepôt de données est considéré comme un environnement
de production. Naturellement le support technique doit surveiller avec la plus grande vigilance
les performances et les tendances en ce qui concerne la charge du système.
Management de l’évolution : il faut toujours s’assurer que l’implémentation répond
aux besoins de l’entreprise. Les revues systématiques à certain point de contrôle sont un outil
clé pour détecter et définir les possibilités d’amélioration. En plus du suivi et de la
maintenance du Data Warehouse, des demandes d’expansion sont envisageables pour de
nouveaux besoins, de nouvelles données ou pour des améliorations.
Ces travaux d’expansion sont à prévoir de façon à faciliter l’évolution du schéma du
Data Warehouse.
42](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-50-320.jpg)







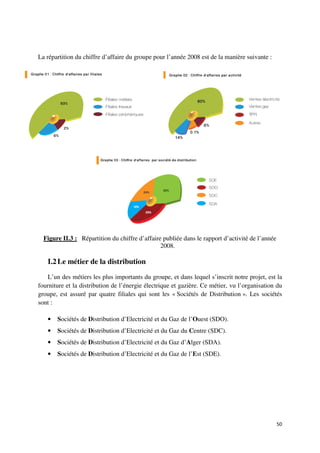








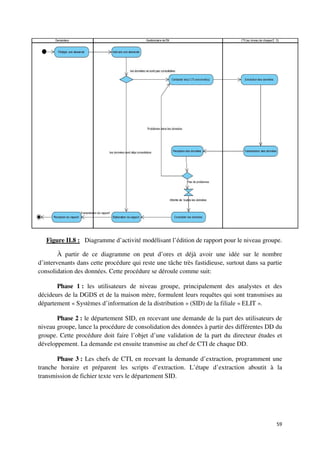




![I. Introduction
Tout Data Warehouse doit être en mesure de répondre aux attentes des utilisateurs.
Cela ne peut, évidemment, se faire sans une étude approfondie de leurs besoins.
e
Ainsi, il existe deux démarches qui ont été décrites lors de notre synthèse
bibliographique, et qui sont: l'approche « Buttom Up » et l'approche « Top Down ».
L'application exclusive de l
e l'une de ces deux approches ne produit nullement des
résultats satisfaisants. La démarche généralement adoptée est une démarche mixte, qui allie
entre les deux précédentes dans un souci de prise en considération des besoins des décideurs
sans perdre de vue toute possibilit et opportunité offerte par les données sources Cette
possibilité sources.
approche permet donc de recueillir, corriger et de modérer les attentes des utilisateurs dès le
départ, tout en détectant d'éventuels besoins non exprimés.
Durant l’étude des besoins on ne peut se limiter aux interviews avec les utilisateurs
limiter utilisateurs,
néanmoins, il faudrait absolument prendre en compte l’avis des Administrateurs des bases de
données des systèmes sources« Les DBA sont les principaux experts sur les applications
existantes susceptibles d'aliment
d'alimenter l'entrepôt de données. Leurs interviews servent à
confronter aux réalités certains des thèmes qui surgissent lors des rencontres avec les
utilisateurs finaux. » [Kimball, 96]
Figure II.9 : La place de l’étape d’étude des besoins dans un projet Data Warehouse.
64](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-72-320.jpg)






![I. Introduction
Une fois les besoins des utilisateurs connus, nous pouvons commencer à concevoir les
volets de notre Data Warehouse. Pour cela, nous avons eu recours à la modélisation
dimensionnelle qui est souvent associée aux entrepôts de données compte tenu de ses
avantages.
Cependant, avant de se lancer dans la modélisation, il est intéressant de classer les
sujets recensés selon l’intérêt qu’ils représentent pour l’entreprise et les facilités de
s
réalisation. Ce classement nous aidera à choisir l’activité à modéliser en premier lieu de
manière à garantir des résultats satisfaisant pour l’entreprise.
satisfaisants
II. Processus de la modélisation dimensionnelle
La conception d’un modèle dimensionnel passe par cinq étapes essentielles :
• Choix de l’activité à modéliser : ce choix se fait après classement des activités dans
une matrice dite d’analyse des priorités [Kimball, 2004]. Cette matrice permet de
’analyse
connaître quelle activité choisir en premier. Le classement des sujets recensés, qui
s’est fait en collaboration avec les décideurs et les techniciens de l’entreprise, est
illustré dans la figure suivante :
Figure II.10 : Analyse des priorités du cas « Distribution SONELGAZ ».
ONELGAZ
• Définition de l’activité et de son grain,
• Définition des dimensions qui décrivent une ligne de la table de fait,
• Définir les mesurables du fait,
éfinir
• Définir les agrégats.
73](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-81-320.jpg)
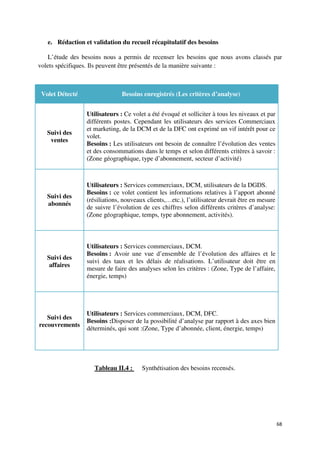
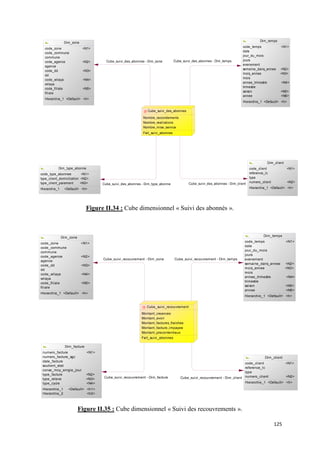
![II.1 Volet « Vente »
a) Présentation de l’activité « Vente »
« Une vente est la cession d’un bien ou d'un service en échange d'une somme d’argent
convenue entre le vendeur, celui qui cède le bien ou le service, et l'acheteur, celui qui paie »
[Larousse, 2008].
SONELGAZ, par le biais de ses quatre filiales, propose la vente d’énergie, (électricité ou
gaz), livré par canalisation jusqu’au lieu de consommation, dans le cadre d’un contrat de
fourniture.
La vente d’énergie, électrique ou gazière, demeure comme l’activité principale des filiales
de distribution du groupe SONELGAZ, réalisant la plus grande partie du chiffre d’affaire du
groupe. Les chiffres liés aux ventes se présentent comme des indicateurs d’une grande
signification par rapport à la performance du groupe. Ainsi la disponibilité de ces
informations s’avère indispensable pour les décideurs de l’entreprise.
b) Grain de l’activité
Le choix du grain le plus fin donne un maximum de flexibilité. Dans le cas des ventes
le grain le plus fin, ou le niveau de détail le plus bas, correspond à une opération de
facturation12, d’où une ligne de table de fait correspondant à :
Suivi de la quantité et du montant de la vente d’une énergie par tarif à un client
activant dans un certain domaine à une date donnée.
12
Ce n’est qu’après facturation que la quantité et le montant consommé sont arrêtés, d’où la vente.
74](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-82-320.jpg)
![c) Les dimensions participantes du modèle
sions
Les dimensions ont pour objectif de décrire le fait, donc on essaye de recens toutes les
recenser
informations qui décrivent une vente et qui peuvent intéresser les décideurs.
formations
1. Dimension Temps
La dimension temps est « la seule dimension qui figure systématiquement dans tout
entrepôt de données, car en pratique tout entrepôt de données est une série temporelle. Le
temps est le plus souvent la première dimension dans le classement sous jacent de la base de
données » [Kimball, 2001].
La dimension temps se présente com suit :
comme
Figure II.11 : La Dimension Temps de l’activité « Vente ».
11
Le niveau de détail le plus bas de cette dimension est la journée. En effet, les utilisateurs
ont fait ressortir le besoin de suivre les chiffres au jour le jour et d
d’en garder l’historique de
ces derniers.
Dans cette dimension, il est utilisé une clé artificielle comme clé primair Cette clé
primaire.
artificielle sert à faciliter la manipulation de la dimension. Le tableau suivant donne plus de
détails sur cette dimension :
75](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-83-320.jpg)










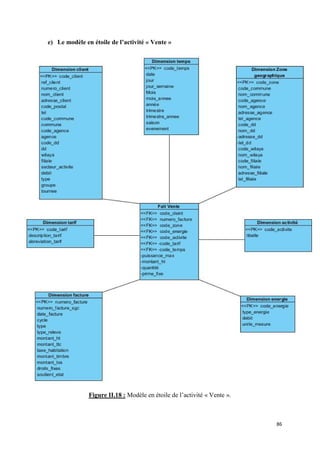


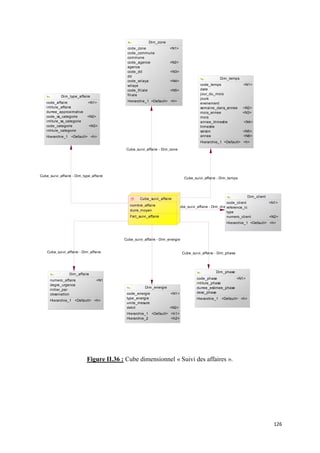
![II.2 Volet « Recouvrement »
a) Présentation de l’activité « Recouvrement »
« Action de recouvrer, de retrouver ce qui était perdu, des sommes dues ». [Larousse,
2008]
Une suite logique au fait de vente, c’est le recouvrement des sommes dues aux clients.
Une somme peut passer par plusieurs phases ou états : facturée, impayée, payée, prés-
contentieux, contentieux et apurée. Cette terminologie obéit à un jargon au sein de
l’organisation pour définir une créance ou un avoir.
Ces états correspondent aux différents comptes de recouvrement. Le mouvement d’un
compte à l’autre se fait par rapport aux délais de recouvrement. L’entreprise s’intéresse au
suivi de l’état journalier de ces comptes afin de suivre de près cette activité très importante.
b) Grain de l’activité :
Le grain le plus fin de l’activité correspond à :
Suivi du montant et de l’état d’une facture d’un client appartenant à une zone
géographique et activant dans un certain domaine à une date donnée
c) Les dimensions participantes du modèle
Les dimensions communes
Après la détection des dimensions de la nouvelle étoile, on procède à une mise en
conformité des dimensions communes. Pour ce faire, on construit un tableau qui croise les
étoiles conçues avec leurs dimensions. Le but étant de détecter les dimensions communes
pour leurs mises en conformité. Le tableau suivant illustre cela :
Etoile Vente Recouvrement
Dimensions
Client √ √
Zone géographique √ √
Temps √ √
Facture √ √
Activité √ √
Nature √
Tableau II.14 : Détection des dimensions communes entre les volets « Vente » et
« Recouvrement ».
A cette étape il existe quatre dimensions communes. Ces dimensions étant très
détaillées dans la première étoile, il n’y a pas eu nécessité de recourir à une mise en
conformité. Cette remarque reste valable pour l’ensemble du document, ainsi il n’y a pas lieu
de détailler les dimensions communes à la présentation de chaque étoile.
89](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-97-320.jpg)

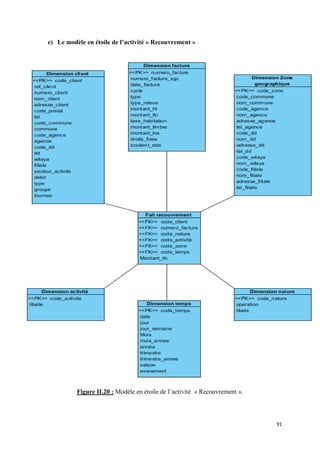





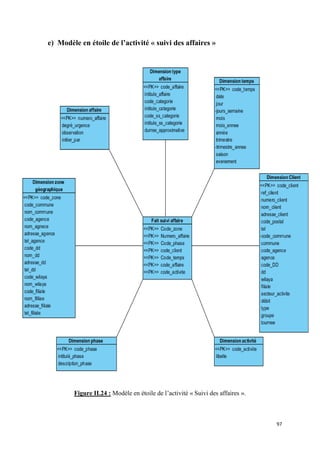



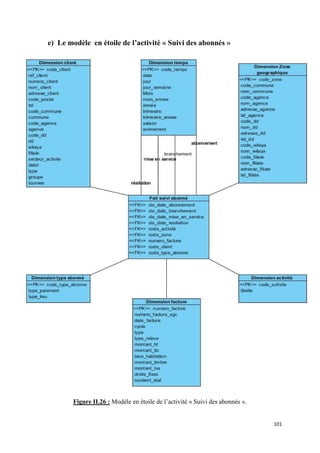
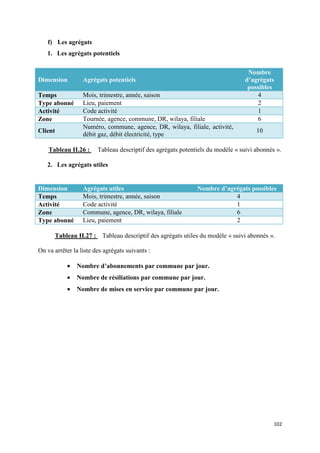



![II.2 Détection des emplacements des données sources :
Afin de définir l’emplacement des informations dans les différents systèmes source et
d’en choisir les emplacements les plus fiables, nous avons travaillé de manière étroite avec les
DBA et les gestionnaires.
Le nombre important de tables, la redondance des données et l’intervention de
différents systèmes, rendent cette tâche très ardue. Afin de mener à bien cette détection, nous
devons :
• Lister les données nécessaires à partir des étoiles conçues,
• Lister les emplacements de chaque donnée,
• Choisir la source la plus fiable et la valider comme source de chargement,
• Dresser un tableau14 qui établi le lien entre données sources et donnée cibles avec
les transformations nécessaires,
Cette étape s’achève par l’élaboration d’une carte logique entre données sources et
données cibles15.
Il est important de valider les sources de données (donc le tableau cité
précédemment), afin de vérifier leurs intégrités et leurs fiabilités.
II.3 Définition de la périodicité de chargement
La périodicité de chargement est étudiée pour chaque étoile séparément. , ce qui
n’empêche pas une synchronisation dans les chargements des dimensions communes.
Avant de décider de la périodicité du chargement, les contraintes suivantes doivent
être prises considération :
• La quantité de données à charger,
• Le temps de non activité des systèmes sources,
L’étoile qui engendrera les chargements les plus importants, en termes de volume,
n’est autre que l’étoile des ventes. En effet, le système de facturation, établit annuellement
plus de six millions de factures, ce qui représente plus de dix millions de lignes de faits
« ventes ». Ce processus s’exécute de façon journalière (soixante-dix mille lieux de
consommation par jour). Aussi, le module de gestion des affaires (Système source) présente
une forte volatilité de ses données. Cette volatilité est due au fait que le passage, d’une affaire
donnée, d’une phase à une autre, ne laisse aucune trace sur la base de données opérationnelle.
14
Ce tableau est décrit dans le livre [Kimball 2004].
15
Voire Annexe D
106](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-114-320.jpg)


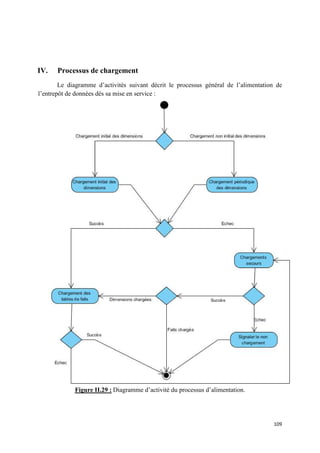

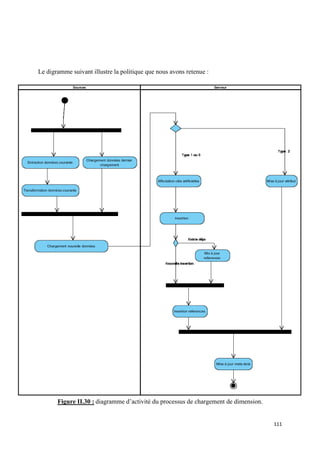

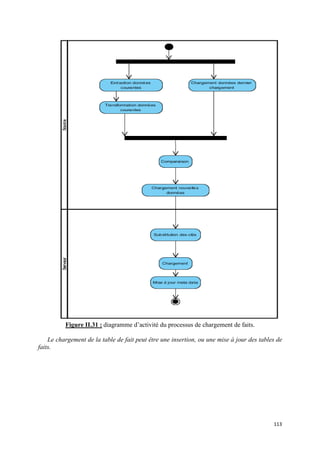
![IV.3 Processus de chargement particulier
Dans un entrepôt de données il y a des tables particulières, soit : la table de la dimension
temps et les tables d’agrégats, nécessites un traitement à part.
IV.3.1 Processus de chargement de la dimension temps
Contrairement aux autres dimensions, la dimension temps contient uniquement des dates
qui ne sont pas forcément extraites à partir des systèmes sources. Cette dimension doit
contenir, en effet, toutes les dates qui coïncident, ou coïncideront, avec un fait donné. Elle
participe à toutes les étoiles et assure l’historisation. Dès lors, il est préférable de construire un
calendrier :
« La dimension date est plus souvent construite comme étant un calendrier avec une
granularité journalière ». [Kimball, 2004].
IV.3.2 Processus de construction d’agrégats
Après le chargement d’une étoile, les tables d’agrégats doivent être chargées par le biais
de l’ETL et à partir des données détaillées. En plus du calcul des agrégats et de leur insertion,
des mises à jour fréquentes de ces tables sont indispensables.
114](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-122-320.jpg)




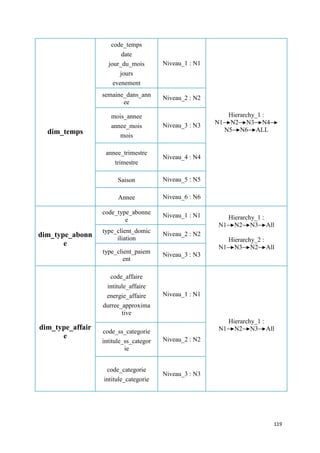

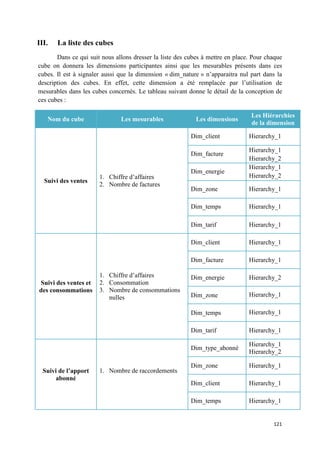
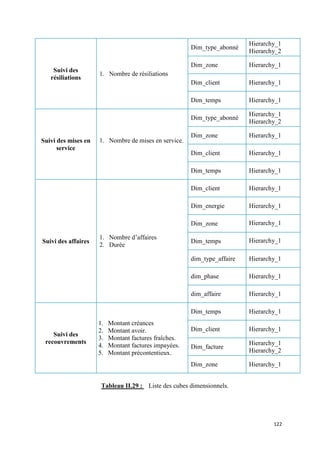










![2) Base de données Meta Data :
La base de données, Meta data, a été implémentée sous le SGBD MySQL, qui est
un SGBD open source simple d’utilisation et performant pour les petites bases de
données.
II.4 Zone d’alimentation de l’entrepôt
L’implémentation du processus de chargement peut se faire par le biais d’outils
disponibles sur le marché. Une multitude de choix s’offre à nous. Cependant, et vu
l’orientation de l’entreprise vers l’open source notre étude s’est limité à cette classe de
produit.
Après une étude comparative, le choix a été porté sur « Talend Open Studio » dans sa
version « 3.1.4r2 », connu comme l’outil le plus performant de sa catégorie open source
[Daan, 2007]. Ce dernier basé sur l’IDE « Eclipse » intègre un ensemble de composants
implémentés en JAVA et permet de rajouter son propre code JAVA.
Les points forts de cet outil sont :
• Assurer une indépendance totale vis-à-vis du SGBD source, ou celui
implémentant l’entrepôt de données.
• Sa richesse en nombre de composants, permet l’extraction de toute source de
données connue et standard.
• Génère des programmes en java s’exécutant sur différentes plateformes.
• Développé par une communauté importante qui ne cesse d’augmenter.
• Permet d’ajouter du code java afin d’implémenter notre solution telle qu’elle a été
conçue.
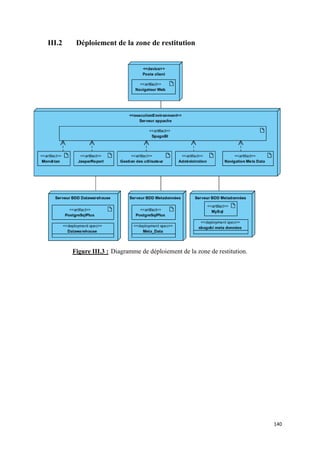
II.5 Zone de restitution
Cette zone représente l’interface entre l’utilisateur et le Data Warehouse. Elle est
constituée d’un ensemble d’outils qui doivent permettre aux utilisateurs d’exploiter le
système mis en place dans les meilleures conditions possibles. . Ainsi plusieurs outils et
serveurs ont été mis en place:
• Un serveur web Apache permettant un accès distant.
• Une plateforme BI « SpagoBI » pour la gestion et la diffusion des documents, ainsi
que pour son module de création de requêtes à la demande « Querry by exemple ».
• Un moteur ROLAP « Mondrian », pour l’implémentation des cubes conçus pour
l’analyse multidimensionnelle. Ce dernier est connu comme leader des moteurs
ROLAP open source.
137](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-145-320.jpg)






![Bibliographie
Ouvrages
[Bouquin, 2003] : Bouquin Henry ; « Le contrôle de gestion » ; P.U.F ; 2003.
[Dresner, 2001] : H. Dresner ; « BI : Making the Data Make Sens » ; Gartner Group 2001.
[Franco, 1997] : Jean-Michel Franco; « Le Data Warehouse, le Data Mining » ; Eyrolles
1997.
[Goglin, 1998] : J.F. Goglin; « La Construction du Datawarehouse : du Datamart au
Dataweb »; Hermes 1998.
[Inmon, 2002]: W. H. Inmon ; « Building the Data Warehouse Third Edition» ; Wiley
Computer Publishing 2002.
[Kimball, 2004] : R. Kimball et J. Caserta ; « The Data warehouse ETL Toolkit» ;Wiley
Publisshing, INC 2004
[Kimball, 2002] : R. Kimball et M. Ross ; « Entrepôts de Données : Guide Pratique de
Modélisation Dimensionnelle 2ème édition » ; Vuibert 2002.
[Kimball,1996] : R. Kimball ; « Entrepôts de données : Guide pratique du concepteur de
Data Warehouse » ;Wiley Computer Publishing 1996.
[Le Moigne, 1977] : Le Moigne J.L., « La théorie du système général, théorie de la
modélisation », P.U.F., 1977.
[Nakache, 1998] : Didier Nakache; « Data Warehouse et Data Mining »; Conservatoire
National des Arts et Métiers de Lille; Version 1.1; 15 juin 1998.
145](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-153-320.jpg)
![Articles et Thèses
[Bouzghoub, 2008] : Abdenour Bouzghoub ; « Modélisation des Entrepôts de données
XML : Application au domaine de la sécurité sociale » ; Thèse de
Magistère Option : SISCSD ; Institut National de Formation en
Informatique (I.N.I) 2008.
[Chouder, 2007] : Lamri Chouder ; « Entrepôt Distribué de Données » ; Thèse de
Magistère Option : SI; Institut National de Formation en
Informatique (I.N.I) 2007.
[Chuck, 1998] : Chuck Ballard, Dirk Herreman, Don Schau, Rhonda Bell, Eunsaeng
Kim, Ann Valencic; Data Modeling Techniques for Data
Warehousing; International Technical Support Organization;
http://www.redbooks.ibm.com; février 1998.
[Codd, 93] : E. F. Codd ; « Providing OLAP (On-Line Analytical Processing) to
User- Analysts : an IT mandate. » ; Technical report ; E.F. Codd &
Associates; 1993.
[Daan, 2007] : Daan Van Beck, Norman Manley, The ETL product survey 2007, A
passionned International research paper, 2007.
[Favre, 2008] : Cécile Favre; «Évolution de schémas dans les entrepôts de données»;
Thèse de doctorat ; Université Lumière Lyon 2 «École
Doctorale Informatique et Information pour la Société» ; Décembre
2007.
[Haciane, 2006] : Ahmed Haciane ; « Conception d’un datawarehouse Orienté CRM »;
Thèse de magistère Option : SI ; Institut National de Formation en
Informatique (I.N.I); 2006.
[Hugh, 2009] : Hugh Watson, Dorothea L. Abraham, Daniel Chen, David Preston;
Dominic Thomas,Data Warehousing ROI: Justifying and Assessing a
Data Warehouse; http://www.bi-bestpractices.com/view-
articles/4780; 2009.
[Inmon, 2000]: B. Inmon; What is a Data Warehouse; Article;
http://www.billinmon.com; 2000.
[Inmon, 1998]: B. Inmon ;Data Mart Does Not Equal Data Warehouse;
http://www.information- management.com/infodirect/19991120/1675-
1.html ;1998.
[Soler, 2001] : Y.Soler; PLANIFICATION ET SUIVI D'UN PROJET ; Centre
national de la recherche scientifique Direction des systèmes
d'information ; http://www.dsi.cnrs.fr/conduite-
146](https://image.slidesharecdn.com/document1295639592-121019094856-phpapp01/85/Conception-et-Realisation-d-un-Data-Warehouse-154-320.jpg)


Le document présente un mémoire de fin d'études sur la conception d'un data warehouse pour le groupe Sonelgaz, visant à améliorer son système décisionnel dans la distribution d'électricité et de gaz. Il aborde les enjeux et défis rencontrés dans la gestion des données client, ainsi que les solutions proposées pour faciliter l'analyse et le reporting. Ce projet a pour objectif d'implémenter une base de données dédiée répondant aux besoins d'analyse du groupe.






























































