Télécharger en tant que PDF, PPTX

















![Spark - Exemple
JavaSparkContext sc = new JavaSparkContext("local", "arbres");
sc.textFile("data/arbresalignementparis2010.csv")
.filter(line -> !line.startsWith("geom"))
.map(line -> line.split(";"))
.mapToPair(fields -> new Tuple2<String, Integer>(fields[4], 1))
.reduceByKey((x, y) -> x + y)
.sortByKey()
.foreach(t -> System.out.println(t._1 + " : " + t._2));
[... ; … ; …]
[... ; … ; …]
[... ; … ; …]
[... ; … ; …]
[... ; … ; …]
[... ; … ; …]
u
m
k
m
a
a
textFile mapToPairmap
reduceByKey
foreach
1
1
1
1
1
u
m
k
1
2
1
2a
...
...
...
...
filter
...
...
sortByKey
a
m
2
1
2
1u
...
...
...
...
...
...
geom;...
1 k](https://image.slidesharecdn.com/spark-prsentationfranais-150519161540-lva1-app6891/85/Spark-v1-3-Presentation-Francais-17-320.jpg)




![JavaRDD<Row> rdd = trees.map(fields -> Row.create(
Float.parseFloat(fields[3]), fields[4]));
● Création de données tabulaires
○ Type Row
○ Type personnalisé
DataFrames - Exemple
---------------------------------------
| 10.0 | Aesculus hippocastanum |
| 15.0 | Tilia platyphyllos |
| 0.0 | Platanus x hispanica |
| 10.0 | Paulownia tomentosa |
| ... | ... |
JavaRDD<Row> rdd = trees.map(fields -> new Tree(
Float.parseFloat(fields[3]), fields[4]));](https://image.slidesharecdn.com/spark-prsentationfranais-150519161540-lva1-app6891/85/Spark-v1-3-Presentation-Francais-22-320.jpg)









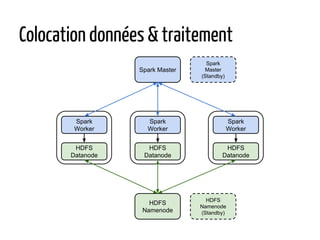


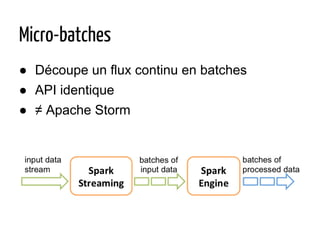
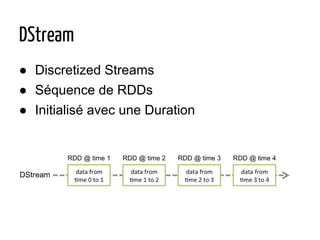
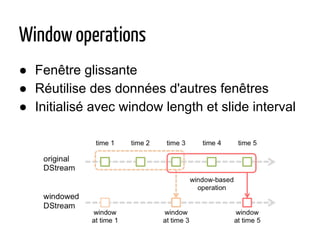






Le document présente Apache Spark, un système de traitement de données distribué, capable de traiter de grandes quantités de données sur du matériel standard, écrit en Scala avec des bindings pour Java et Python. Il explique les divers cas d'utilisation de Spark, notamment l'analyse de logs, le traitement de données et le machine learning, ainsi que la structure de son écosystème et des fonctionnalités telles que les RDD et DataFrames. Le document fait également mention des performances de Spark par rapport à Hadoop, de ses capacités de streaming et de son intégration avec d'autres technologies comme YARN et HDFS.















































