Télécharger en tant que PDF, PPTX



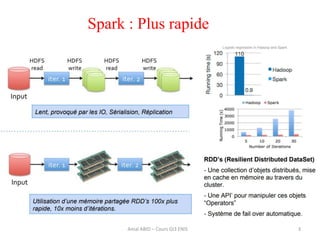


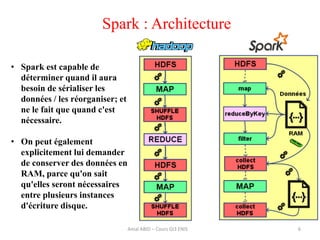

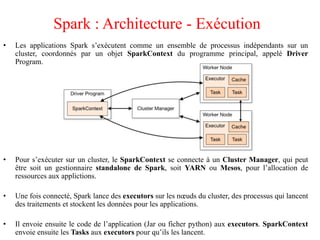


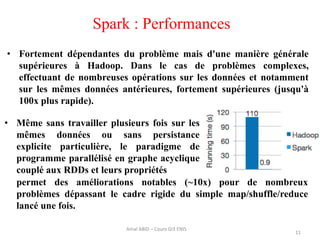







Spark est un framework open source de traitement de données à grande échelle, développé à l'origine à l'université de Berkeley et maintenant sous la fondation Apache. Il offre des performances supérieures à Hadoop grâce à l'utilisation de la mémoire pour des traitements optimisés, et propose des API simples pour la manipulation des données via des Resilient Distributed Datasets (RDD). Bien que plus rapide, Spark nécessite plus de mémoire et est souvent déployé sur des clusters Hadoop existants.

























































![[Smile] atelier spark - salon big data 13032018](https://cdn.slidesharecdn.com/ss_thumbnails/smile-atelierspark-salonbigdata13032018-180328084149-thumbnail.jpg?width=640&height=640&fit=bounds)


