Téléchargé 387 fois



![4 ENIS – GI 3 – 2017/2018 Mme. Amal ABID
Ouvrez le fichier /home/etudiant/.bashrc (avec la commande « nano » ou « gedit »)
$ nano /home/etudiant/.bashrc
Puis ajoutez à la fin du fichier les lignes suivantes :
(PS : Vérifiez le chemin de Java dans votre machine)
# Java Environment Variable
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Pour que le système prenne en compte la modification, redémarrez la machine : [sudo reboot] ou bien
recharger le fichier ~/.bashrc : [source ~/.bashrc].
Le fichier $HADOOP_HOME/etc/hadoop/hadoop-env.sh contient des variables d'environnement
utilisées par Hadoop. Décommentez (ou modifiez) celle de la variable JAVA_HOME.
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Vérifiez que Hadoop s'exécute en tapant :
$ hadoop version
Hadoop 2.7.4
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r
cd915e1e8d9d0131462a0b7301586c175728a282
Compiled by kshvachk on 2017-08-01T00:29Z
Compiled with protoc 2.5.0
From source with checksum 50b0468318b4ce9bd24dc467b7ce1148
This command was run using
/usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.4.jar](https://image.slidesharecdn.com/installation-hadoopv2-170927121338/85/Installation-hadoopv2-7-4-amal-abid-4-320.jpg)



![8 ENIS – GI 3 – 2017/2018 Mme. Amal ABID
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
! Plus d'informations sur les paramètres autorisés dans yarn-site.xml sont disponibles ici : yarn-
default.xml.
2. Configuration SSH
Hadoop nécessite un accès SSH pour gérer les différents nœuds. Bien que nous soyons dans une
configuration simple nœud, nous avons besoin de configurer l'accès vers localhost.
Tout d'abord, assurez-vous que SSH est installé et un serveur est en cours d'exécution. Sur Ubuntu, ce
résultat est obtenu avec :
$ sudo apt-get install ssh
Puis, pour activer un login sans mot de passe, générez une nouvelle clé SSH avec un mot de passe vide.
$ ssh-keygen -t rsa -P ""
Generating public/private rsa key pair.
Enter file in which to save the key (/home/amal/.ssh/id_rsa):
Created directory '/home/amal/.ssh'.
Your identification has been saved in /home/amal/.ssh/id_rsa.
Your public key has been saved in /home/amal/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:6x4uPYsRJ6/J3bYAGmccyyv+QRFm8UGsYtoSir2e5M8 amal@amal-virtual-
machine
The key's randomart image is:
+---[RSA 2048]----+
| =+o |
| o o.. |
| o.. |
| . oo.+ |
|.o =..@ S |
|o + .* B . |
| .oo +.= |
| o.+ o.Xo+. |
| .+.E.*o*+o. |
+----[SHA256]-----+
Cette commande va créer une paire de clés RSA (publique/privée) avec un mot de passe vide. Dans
notre cas de test et de virtualisation, l'absence de mot de passe n'a pas d'importance. Assurez-vous d'en
fixer un si votre serveur est accessible depuis l'extérieur.
Vous devez ensuite autoriser l'accès au SSH de la machine avec cette nouvelle clé fraîchement créée.](https://image.slidesharecdn.com/installation-hadoopv2-170927121338/85/Installation-hadoopv2-7-4-amal-abid-8-320.jpg)
![9 ENIS – GI 3 – 2017/2018 Mme. Amal ABID
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
La dernière chose à réaliser est de tester la connexion SSH.
$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be
established.
ECDSA key fingerprint is
SHA256:0Xdp/TXQvQKT9nzZ434ieIvIsbU8f0YbnbVr5wIIZes.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known
hosts.
Welcome to Ubuntu 16.04.1 LTS (GNU/Linux 4.4.0-31-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
537 paquets peuvent être mis à jour.
272 mises à jour de sécurité.
Last login: Mon Sep 18 21:31:55 2017 from 192.168.32.1
En cas de succès, vous ne devriez pas taper un mot de passe.
3. Initialisation du système de fichier HDFS
Avant de démarrer le serveur Hadoop, vous devez formater le système de fichiers HDFS. Comme tout
système de fichiers, il est nécessaire de le formater avant son utilisation. Dans le cas de cette installation
d'un cluster simple nœud, seul le système de fichiers HDFS de votre machine locale sera formaté. Pour
cela, il suffit d’exécuter la commande hadoop système suivante :
$ hdfs namenode –format
L'exécution du formatage devrait ressembler à cela :
17/09/18 22:38:54 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = amal-virtual-machine/127.0.1.1
STARTUP_MSG: args = [–format]
STARTUP_MSG: version = 2.7.4
STARTUP_MSG: classpath =
/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/jaxb-
api-2.2.2.jar:/usr/local/hadoop/share/hadoop/common/lib/gson-
…
…
…
STARTUP_MSG: build = https://shv@git-wip-
us.apache.org/repos/asf/hadoop.git -r
cd915e1e8d9d0131462a0b7301586c175728a282; compiled by 'kshvachk' on 2017-08-](https://image.slidesharecdn.com/installation-hadoopv2-170927121338/85/Installation-hadoopv2-7-4-amal-abid-9-320.jpg)
![10 ENIS – GI 3 – 2017/2018 Mme. Amal ABID
01T00:29Z
STARTUP_MSG: java = 1.8.0_131
************************************************************/
17/09/18 22:38:54 INFO namenode.NameNode: registered UNIX signal handlers
for [TERM, HUP, INT]
17/09/18 22:38:55 INFO namenode.NameNode: createNameNode [–format]
Usage: java NameNode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-upgradeOnly [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-rollback] |
[-rollingUpgrade <rollback|downgrade|started> ] |
[-finalize] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby] |
[-recover [ -force] ] |
[-metadataVersion ] ]
17/09/18 22:38:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at amal-virtual-machine/127.0.1.1
************************************************************/
Remarque :
Si la commande « hdfs namenode –format » n’a pas fonctionné convenablement, essayez la commande
suivante :
$ hadoop namenode –format
4. Démarrage et arrêt d'un serveur Hadoop
Pour démarrer Hadoop, vous aurez besoin de démarrer le système de fichiers HDFS et le serveur
MapReduce dans le cas où vous souhaitez utiliser des jobs MapReduce.
La commande suivante démarre le système de fichiers HDFS.
$ start-dfs.sh
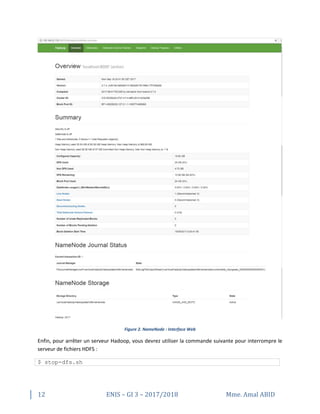
Affichage obtenu :
Starting namenodes on [localhost]
localhost: starting namenode, logging to
/usr/local/hadoop/logs/hadoop-amal-namenode-amal-virtual-machine.out
localhost: starting datanode, logging to
/usr/local/hadoop/logs/hadoop-amal-datanode-amal-virtual-machine.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to
/usr/local/hadoop/logs/hadoop-amal-secondarynamenode-amal-virtual-
machine.out](https://image.slidesharecdn.com/installation-hadoopv2-170927121338/85/Installation-hadoopv2-7-4-amal-abid-10-320.jpg)

![13 ENIS – GI 3 – 2017/2018 Mme. Amal ABID
et la commande suivante pour interrompre le serveur MapReduce :
$ stop-yarn.sh
Remarque :
Pour utiliser la ligne de commande sous HDFS (hadoop fs –[generic option]), n’oublierez jamais de
démarrer HDFS (start-dfs.sh).
Même remarque pour l’utilisation de yarn (start-yarn.sh).
Remarques :
Si l’interface web du ResourceManager n’a pas été affichée vous devez vérifier la configuration
des fichiers « mapred-site.xml » et « yarn-site.xml ».
Si l’interface web du NameNode n’a pas été affichée vous devez vérifier la configuration des
fichiers « core-site.xml » et « hdfs-site.xml », et suivre les étapes suivantes :
o Lancez la commande : hdfs namenode
o Généralement vous aurez comme exception : NameNode is not formatted
o Lancez les commandes : stop-dfs.sh et stop-yarn.sh
o Vérifiez la configuration des fichiers « core-site.xml » et « hdfs-site.xml ». Cette
exception peut être dû à l’oublie de la sauvegarde des modifications nécessaires sur
ces fichiers.
o Supprimez le contenu des deux dossiers (le contenu des dossiers, pas les dossiers!) :
/usr/local/hadoop/hadoopdata/hdfs/namenode
/usr/local/hadoop/hadoopdata/hdfs/datanode
o Refaites le formatage : hdfs namenode –format
o Lancez les commandes : start-dfs.sh et start-yarn.sh
o Lancez la commande : jps
Le namenode et le datanode doivent apparaitre dans la liste.
o Consultez la page http://localhost:50070/
5. Enjoy Hadoop!](https://image.slidesharecdn.com/installation-hadoopv2-170927121338/85/Installation-hadoopv2-7-4-amal-abid-13-320.jpg)

Ce document décrit l'installation et la configuration d'un cluster Hadoop sous Linux (Ubuntu 16.04) dans un mode pseudo-distribué. Il aborde les prérequis nécessaires, comme la mise à jour du système, l'installation de Java et SSH, ainsi que la configuration de divers fichiers de configuration Hadoop. Enfin, il explique comment tester la bonne installation de Hadoop et configure les paramètres principaux pour son opération.















































