Télécharger en tant que PDF, PPTX



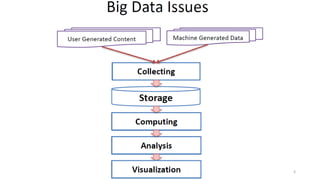
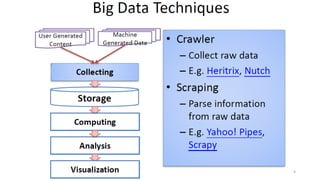
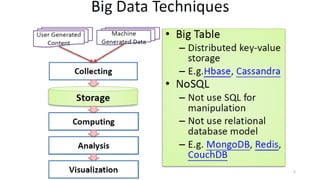
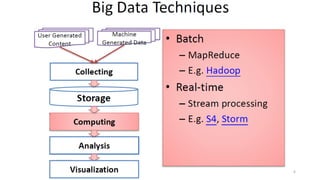
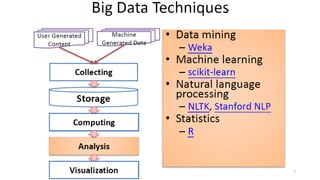

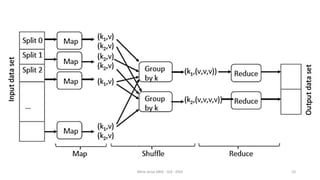



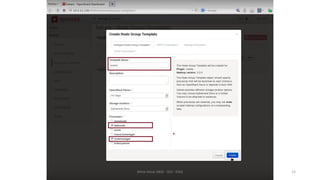
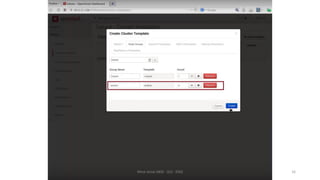
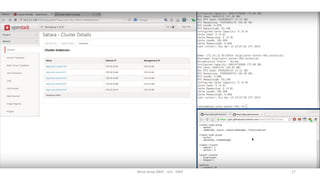
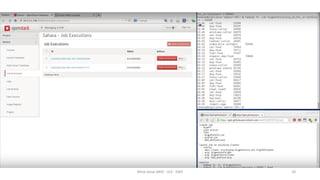



Le document présente divers aspects du Big Data, notamment l'utilisation de Hadoop dans des environnements distribués et le rôle d'OpenStack et de son composant Sahara pour faciliter la gestion des clusters Hadoop. Il explique également le projet Apache Mahout, utilisé pour la création d'algorithmes d'apprentissage automatique, soulignant son intégration avec Hadoop et son utilisation pour le clustering. Enfin, des liens vers des démonstrations vidéo sont fournis pour illustrer ces concepts.















































