Télécharger en tant que PDF, PPTX



![Un exemple: Indexer en MapReduce
•
map(pageName, pageText):
– foreach word in pageText:
– emitIntermediate(word, pageName);
[copie et trie par clefs entre les noeuds]
•
reduce(word, pageNames):
– bucket = createBucketFor(word)
– foreach pageName in pageNames:
●
bucket.add(pageName)
– bucket.finalize()](https://image.slidesharecdn.com/ogrisel-hadoop-osdcfr-2009-091002190819-phpapp02/85/Hadoop-MapReduce-OSDC-FR-2009-4-320.jpg)

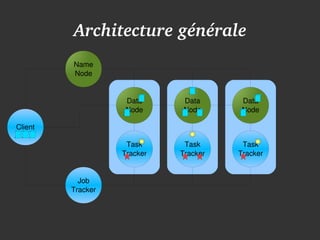


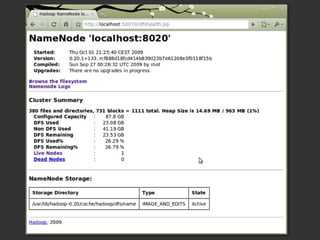
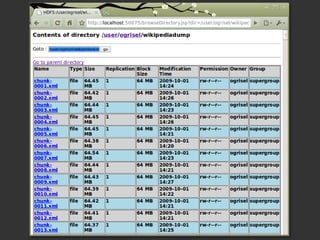
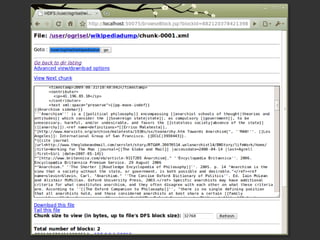

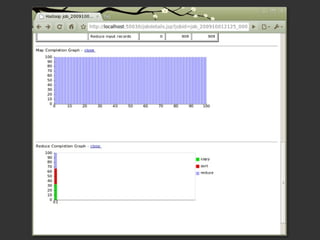

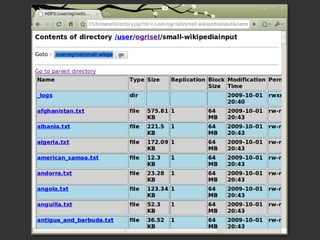
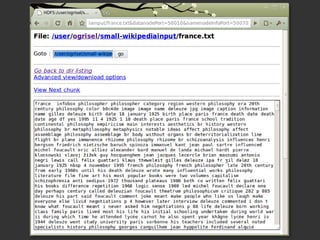


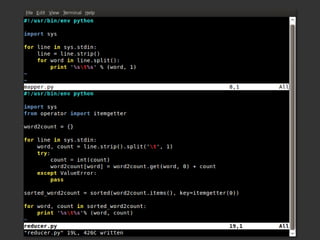







Le document présente Hadoop et MapReduce comme des outils essentiels pour le traitement de grandes quantités de données, en illustrant leur architecture et leur fonctionnement. Il comprend une démonstration d'indexation via MapReduce et des informations sur les projets liés à Hadoop ainsi que sur les langages de programmation compatibles. Enfin, il donne des conseils pratiques sur l'installation et l'apprentissage de ces technologies.































































