Téléchargé 191 fois






















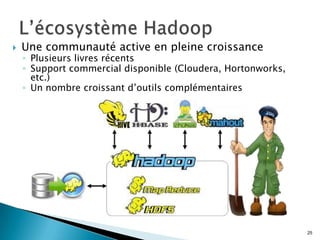











Le document présente une introduction aux concepts du big data et de Hadoop, y compris des définitions, des enjeux et des cas d'utilisation. Il détaille le fonctionnement technique de Hadoop, son écosystème, ainsi que des exemples d'application dans divers secteurs comme le commerce en ligne et la détection de fraudes. Enfin, il aborde les forces et les limites de Hadoop tout en soulignant son adoption croissante dans l'industrie.















![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)


























































